
yuyi
知不可乎骤得,托遗响于悲风

实验结果
自知识蒸馏相关实验
使用UAFM融合模块增强后的特征指导原始骨干网络输出的特征,最终使用原始骨干网络输出的特征进行推理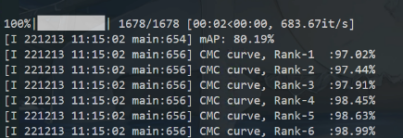
(Tips:这里使用了PVEN原始的超参数(batchsize=64、numinstance=4)。原PVEN性能为79.4%,rank-1为95.6%)
反过来,使用原始骨干网输出特征指导最终UAFM融合的特征,也如猜想那样降低了原本性能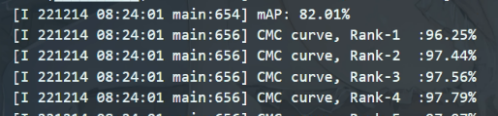
(Tips:这里使用了我们论文GLNet的超参数(batchsize=128、numinstance=8)。只使用特征融合的GLNet性能为82.7%左右)
实验表明,自知识蒸馏可以在不增加推理阶段计算量的情况下提升性能。
多尺度特征利用相关实验
首先使用了BiFPN加在重识别上进行实验,直接移植这种多尺度增强模块性能果然不好。
接着修改并设计了新的多特征融合方法,可以将三个特征图融合在一起,在Fast-reid上提升了近两个点。
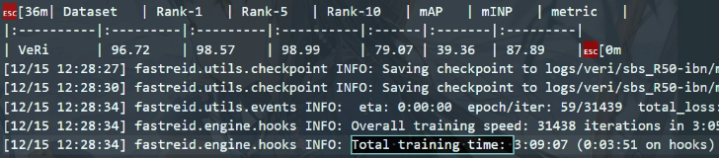
1.在fast-reid上进行多次实验,更加认识到重识别领域关于 batchsize和num_instance 这两个超参数的设定尤为重要。
例如HRCN的性能为83.1(batchsize:48,num_instance:12),其使用fast-reid作为baseline性能为76.8(batchsize:64,num_instance:16),如果将baseline的超参数设定为与HRCN一致, 性能会大幅下降。
2.从自知识蒸馏的实验结果来看,有效信息是可以从UAFM融合后的特征传递到原始输出特征上的。但是相比之间使用融合后的特征进行推理来说,性能的提升并不多,这可能是因为现有自知识蒸馏所使用的损失函数是为图像分类所设计的,而重识别中,图像分类只是作为辅助训练的一部分。
回顾之前全局和局部之间使用自知识蒸馏后无性能提升的实验结果,可能也是这个原因造成,单纯依靠基于分类的损失和简单的特征相似损失难以传递对于重识别有效的信息。
3.使用类似SE的模块来学习出多个(例:4个)值得关注的局部区域
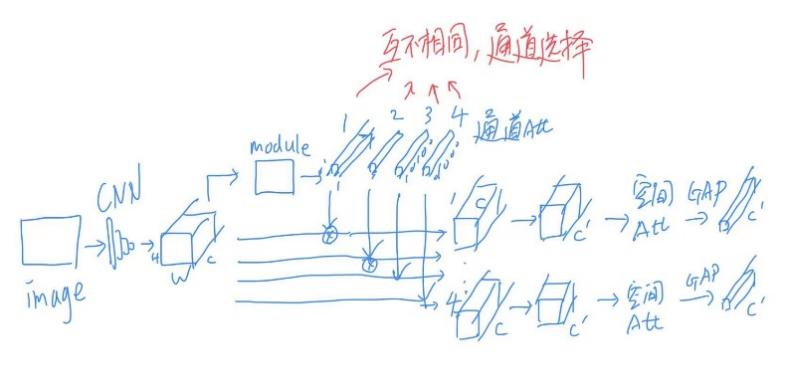
其关键在于损失函数的设计,这部分和上面自知识蒸馏目前面临的问题有相同之处,都是要针对重识别设计有效的损失函数。

https://t.me/s/flagman_official_registration
https://t.me/s/iGaming_live/4871