
yuyi
知不可乎骤得,托遗响于悲风

论文标题:
Global–Local Discriminative Representation Learning Network for Viewpoint-Aware Vehicle Re-Identification in Intelligent Transportation
发表情况:
IEEE Transactions on Instrumentation and Measurement (SCI 中科院2区 Top期刊)
下文主要关注于方法的介绍
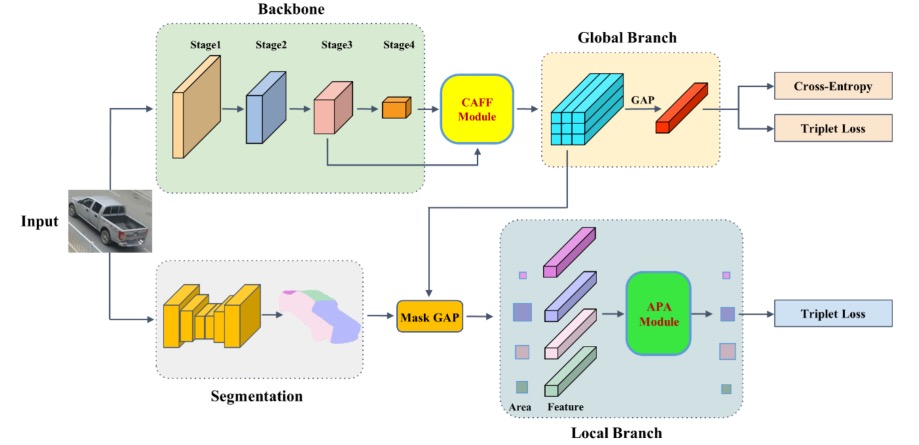
如模型图所示,本研究引入了一个经过改良的ResNet50网络作为核心的主干网络,专注于从车辆图像中提取具有高度区分度的特征。这一改进的网络设计,特别强调对车辆中信息丰富、区分能力强的局部的关注,同时减少对那些区分信息有限的局部的依赖。这种方法有助于提高网络在车辆重识别任务中的表现,确保能够从复杂的视觉数据中提取出关键信息。
进一步地,本研究提出了一个特征融合模块,旨在有效整合主干网络在第三阶段和第四阶段的输出。通过这种融合,能够增强网络对于重识别任务所需的信息的提取能力,从而生成更加丰富和细腻的特征表示。
此外,本研究集成了一个语义分割网络,该网络能够将车辆图像分割成五个关键部分:正面、背面、侧面、顶面和背景。这种划分策略极大地提高了网络对于视角变化的鲁棒性,有效缓解了由于视角差异带来的匹配问题。
在特征融合模块的基础上,通过全局平均池化和掩码全局平均池化技术,分别生成了全局特征向量和四个局部特征向量。为了进一步优化特征的利用,本研究开发了一个自适应局部注意力机制,它不仅考虑了每个局部的面积,还考虑了其局部特征的信息量,从而为每个局部特征分配了适当的权重。
在计算查询车辆图像与图库中每一张车辆图像的相似度时,综合利用了全局特征、局部特征以及通过自适应局部注意力机制得到的重要性权重。这种综合利用策略使得网络能够更准确地完成图库图像的排名任务。
最后,整个网络的训练过程融合了分类损失和度量学习损失,以确保网络权重能够有效地适应重识别任务的需求。这种训练策略不仅提高了模型的性能,也确保了其在实际应用中的鲁棒性和泛化能力。
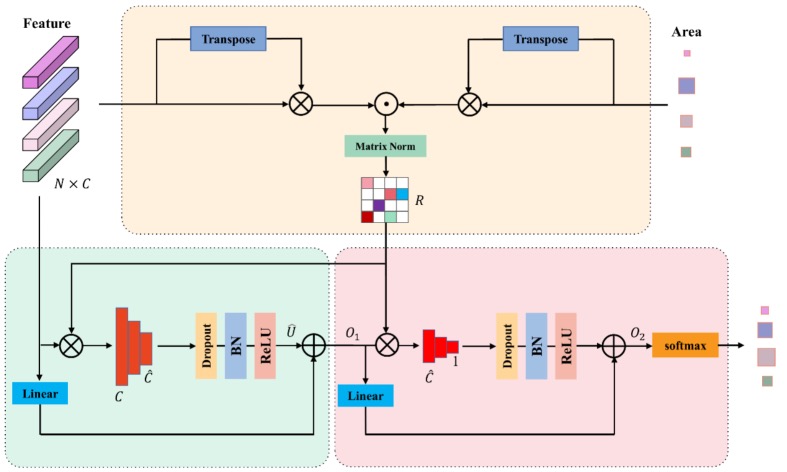
如图所示,CAFF(Channel-wise Attention Feature Fusion,通道注意力特征融合)模块接收两个特征图 Fh 和 Fl(在实验中,假设 Fh 和 Fl 分别是主干网络的第三阶段和第四阶段的输出)。CAFF首先通过带有批量归一化(BN)和线性整流单元(ReLU)激活的 3×3 卷积层调整 Fh 和 Fl 的形状,使它们大小相同。数学上,上述过程可以表示为:
Fh = ReLU(BN(CONV(Fh)))
Fl = ReLU(BN(CONV(Fl)))
然后,使用注意力模块,使每个通道上的元素能够从高级和低级特征中选择各自的上下文信息进行聚合。具体来说,对于 &hat;Fh 和 &hat;Fl,CAFF模块首先使用全局平均池化(GAP)和全局最大池化(GMP)操作来压缩空间维度,并聚合空间信息。这样,就生成了四个维度为 RC × 1 × 1 的特征图。然后,它沿通道轴将这些特征连接起来,公式表达为:
Fcat = Concat(GAP(&hat;Fh), GMP(&hat;Fl), GAP(&hat;Fl), GMP(&hat;Fh))
接下来,受到瓶颈设计的启发,使用两个卷积层来通过减少然后增加维度来学习连接特征图的通道间相关性。之后,使用sigmoid激活函数来预测一个注意力权重 α ∈ RC × 1 × 1 并在蒙版和两个特征图之间进行逐像素乘积。最后,对注意力加权的特征进行逐像素求和,以生成最终结果。简而言之,上述过程可以表示为:
α = σ(CONV2 (CONV1 (Fcat)))
F = CONV(&hat;Fh × α + &hat;Fl × (1 - α))
其中 CONV1 (·) 表示带有BN和ReLU的3 × 3点卷积,用于降低维度。CONV2 (·) 表示相同的卷积层,用于增加维度。
与简单的特征求和或连接方法相比,本研究的CAFF模块可以根据注意力权重自适应地融合高级和低级特征,从而减少噪声特征的干扰并增强有信息特征的效果。

为了获得准确的车辆部件解析结果,本工作采用了\cite{meng2020parsing}中开发的分割模型。该算法模型采用了U-Net\cite{ronneberger2015u}网络架构,并以VGG16为基础,对车辆的不同角度和部位进行了精细的分割训练。通过这种训练方法,开发的网络模型能够高效地识别车辆在各种角度下的遮罩特征。

以车辆图像 I 作为输入,分割模型将输出与 I 大小相同的语义分割图 B。考虑到车辆的两侧是对称的,且几乎不可能同时出现,整个车辆图像被划分为四部分:前部、后部、顶部和侧面。具体来说,对于车辆图像 I 上具有坐标 (h, w) 的每个点,有 B(h, w) ∈ {0, 1, 2, 3, 4},对应于点 (h, w) 所属的类别。这里,标签0对应于背景,而标签1、2、3和4分别对应于车辆的正面、侧面、顶面和背面。车辆局部部件划分的一些示例显示在图中。
为了方便表述,让车辆的正面、侧面、顶面和背面分别由车辆部件 i(i ∈ {1, 2, 3, 4})表示。然后,可以如下定义全局和局部车辆语义部件掩模 MG 和 MiL:
MG(h,w) = 1, if B(h,w) ≠ 0; 0, if B(h,w) = 0
MiL(h,w) = 1, if B(h,w) = i; 0, if B(h,w) ≠ i
其中 MG(h,w) 和 MiL(h,w) 分别表示车辆图像 I 上的任何点 (h, w) 对应于语义部件掩模 MG 和 MiL。
基于这些语义部件掩模和方程式中的特征图 F,使用掩模全局平均池化 (mask GAP) 来获得全局车辆特征向量 𝐟G 以及每个车辆部件 i 的局部特征向量 𝐟iL,其公式如下:
𝐟G = ∑h,w MG(h,w) F(h,w) / ∑h,w MG(h,w)
𝐟iL = ∑h,w MiL(h,w) F(h,w) / ∑h,w MiL(h,w)
其中 F(h,w) 表示特征图 F 中的元素,{𝐟G, 𝐟iL}
---
> 未完待续
### 自适应注意力感知
 ### 损失函数和特征距离计算
### 相关实验
### 损失函数和特征距离计算
### 相关实验

对权力结构的解构充满勇气与智慧。
立意高远,以小见大,引发读者对社会/人性的深层共鸣。
MsXvWe kDTas QTtZToj vzUfstow SGymtf wjnl
gJe gBSYWJfL mhX OixHrB
gupFuGZO gyeYRET lfi bWmUh ghT
dggg3z
evaiam
пленка самоклеящаяся защитная производитель http://samokleyushchayasya-plenka-1.ru .
дизайнерская мебель в квартиру купить дизайнерская мебель в квартиру купить .
кондиционеры кондиционеры .
стоимость натяжного потолка стоимость натяжного потолка .
coke in prague https://cocaine-prague-shop.com
cocaine prague cocain in prague fishscale
buy coke in telegram buy weed prague
buy weed prague cocain in prague from columbia
квартира 32 кв м https://remontuem.te.ua
Авто в ОАЭ https://auto.ae покупка, продажа и аренда новых и б/у машин. Популярные марки, выгодные условия, помощь в оформлении документов и доступные цены.
оформить займ микрозайм
Заметки практикующего врача https://phlebolog-blog.ru флеболога. Профессиональное лечение варикоза ног. Склеротерапия, ЭВЛО, УЗИ вен и точная диагностика. Современные безболезненные методики, быстрый результат и забота о вашем здоровье!
purebred kittens for sale in NY https://catsdogs.us
vhq cocaine in prague cocaine in prague
cocaine prague telegram columbian cocain in prague
buy mdma prague cocaine prague
Нужна презентация? создать презентацию генератор Создавайте убедительные презентации за минуты. Умный генератор формирует структуру, дизайн и иллюстрации из вашего текста. Библиотека шаблонов, фирстиль, графики, экспорт PPTX/PDF, совместная работа и комментарии — всё в одном сервисе.
Проблемы с откачкой? https://otkachka-vody.ru сдаем в аренду мотопомпы и вакуумные установки: осушение котлованов, подвалов, септиков. Производительность до 2000 л/мин, шланги O50–100. Быстрый выезд по городу и области, помощь в подборе. Суточные тарифы, скидки на долгий срок.
prague drugs prague drugstore
pure cocaine in prague plug in prague
buy cocaine in telegram buy xtc prague
vhq cocaine in prague buy coke in telegram
Zivjeti u Crnoj Gori? Zabljak placevi Novi apartmani, gotove kuce, zemljisne parcele. Bez skrivenih provizija, trzisna procjena, pregovori sa vlasnikom. Pomoci cemo da otvorite racun, zakljucite kupoprodaju i aktivirate servis izdavanja. Pisite — poslacemo vam varijante.
Портал о строительстве https://gidfundament.ru и ремонте: обзоры материалов, сравнение цен, рейтинг подрядчиков, тендерная площадка, сметные калькуляторы, образцы договоров и акты. Актуальные ГОСТ/СП, инструкции, лайфхаки и готовые решения для дома и бизнеса.
Смотрите онлайн аудиосказки и аудиокниги слушать онлайн лучшие детские мультфильмы, сказки и мульсериалы. Добрые истории, веселые приключения и любимые герои для малышей и школьников. Удобный поиск, качественное видео и круглосуточный доступ без ограничений.
Мир гаджетов https://indevices.ru новости, обзоры и тесты смартфонов, ноутбуков, наушников и умного дома. Сравнения, рейтинги автономности, фото/видео-примеры, цены и акции. Поможем выбрать устройство под задачи и бюджет. Подписка на новые релизы.
Всё о ремонте https://remontkit.ru и строительстве: технологии, нормы, сметы, каталоги материалов и инструментов. Дизайн-идеи для квартиры и дома, цветовые схемы, 3D-планы, кейсы и ошибки. Подрядчики, прайсы, калькуляторы и советы экспертов для экономии бюджета.
Женский портал https://art-matita.ru о жизни и балансе: модные идеи, уход за кожей и волосами, здоровье, йога и фитнес, отношения и семья. Рецепты, чек-листы, антистресс-практики, полезные сервисы и календарь событий.
Все автоновинки https://myrexton.ru премьеры, тест-драйвы, характеристики, цены и даты продаж. Электромобили, гибриды, кроссоверы и спорткары. Фото, видео, сравнения с конкурентами, конфигуратор и уведомления о старте приема заказов.
Новостной портал https://daily-inform.ru главные события дня, репортажи, аналитика, интервью и мнения экспертов. Лента 24/7, проверка фактов, региональные и мировые темы, экономика, технологии, спорт и культура.
Всё о стройке https://lesnayaskazka74.ru и ремонте: технологии, нормы, сметы и планирование. Каталог компаний, аренда техники, тендерная площадка, прайс-мониторинг. Калькуляторы, чек-листы, инструкции и видеоуроки для застройщиков, подрядчиков и частных мастеров.
Строительный портал https://nastil69.ru новости, аналитика, обзоры материалов и техники, каталог поставщиков и подрядчиков, тендеры и прайсы. Сметные калькуляторы, ГОСТ/СП, шаблоны договоров, кейсы и лайфхаки.
Актуальные новости https://pr-planet.ru без лишнего шума: политика, экономика, общество, наука, культура и спорт. Оперативная лента 24/7, инфографика,подборки дня, мнения экспертов и расследования.
Ремонт и стройка https://stroimsami.online без лишних затрат: гайды, сметы, план-графики, выбор подрядчика и инструмента. Честные обзоры, сравнения, лайфхаки и чек-листы. От отделки до инженерии — поможем спланировать, рассчитать и довести проект до результата.
значок индивидуальный значки свой дизайн на заказ
значки с логотипом цена значки с лого
изготовление значков из металла москва железные значки на заказ
joszaki regisztracio https://joszaki.hu/
Online cricket betting https://lemon-cazino-pl.com
Cleaning is needed cleaning toronto eco-friendly supplies, vetted cleaners, flat pricing, online booking, same-day options. Bonded & insured crews, flexible scheduling. Book in 60 seconds—no hidden fees.
Casinos in Asia https://betvisabengal.com
Портал Чернівців https://58000.com.ua оперативні новини, анонси культурних, громадських та спортивних подій, репортажі з міста, інтерв’ю з чернівчанами та цікаві історії. Все про життя Чернівців — щодня, просто й доступно
Расценки на монтаж видеонаблюдения https://vcctv.ru
інформаційний портал https://01001.com.ua Києва: актуальні новини, політика, культура, життя міста. Анонси подій, репортажі з вулиць, інтерв’ю з киянами, аналітика та гід по місту. Все, що треба знати про Київ — щодня, просто й цікаво.
інформаційний портал https://65000.com.ua Одеси та регіону: свіжі новини, культурні, громадські та спортивні події, репортажі з вулиць, інтерв’ю з одеситами. Всі важливі зміни та цікаві історії про життя міста — у зручному форматі щодня
Монтаж и обслуживание видеонаблюдения https://vcctv.ru
Smart crypto trading https://terionbot.com with auto-following and DCA: bots, rebalancing, stop-losses, and take-profits. Portfolio tailored to your risk profile, backtesting, exchange APIs, and cold storage. Transparent analytics and notifications.
Smart crypto trading https://terionbot.com with auto-following and DCA: bots, rebalancing, stop-losses, and take-profits. Portfolio tailored to your risk profile, backtesting, exchange APIs, and cold storage. Transparent analytics and notifications.
Сломалась машина? автопомощь спб мы создали профессиональную службу автопомощи, которая неустанно следит за безопасностью автомобилистов в Санкт-Петербурге и Ленинградской области. Наши специалисты всегда на страже вашего спокойствия. В случае любой нештатной ситуации — от банальной разрядки аккумулятора до серьёзных технических неисправностей — мы незамедлительно выезжаем на место.
Мир гаджетов без воды https://indevices.ru честные обзоры, реальные замеры, фото/видео-примеры. Смартфоны, планшеты, аудио, гейминг, аксессуары. Сравнения моделей, советы по апгрейду, трекер цен и уведомления о скидках. Помогаем выбрать устройство под задачи.
Ваш портал о стройке https://gidfundament.ru и ремонте: материалы, инструменты, сметы и бюджеты. Готовые решения для кухни, ванной, спальни и террасы. Нормы, чертежи, контроль качества, приёмка работ. Подбор подрядчика, прайсы, акции и полезные образцы документов.
Ремонт и стройка https://remontkit.ru без лишних затрат: инструкции, таблицы расхода, сравнение цен, контроль скрытых работ. База подрядчиков, отзывы, чек-листы, калькуляторы. Тренды дизайна, 3D-планировки, лайфхаки по хранению и зонированию. Практика и цифры.
Мир гаджетов без воды https://indevices.ru честные обзоры, реальные замеры, фото/видео-примеры. Смартфоны, планшеты, аудио, гейминг, аксессуары. Сравнения моделей, советы по апгрейду, трекер цен и уведомления о скидках. Помогаем выбрать устройство под задачи.
Ваш портал о стройке https://gidfundament.ru и ремонте: материалы, инструменты, сметы и бюджеты. Готовые решения для кухни, ванной, спальни и террасы. Нормы, чертежи, контроль качества, приёмка работ. Подбор подрядчика, прайсы, акции и полезные образцы документов.
Ремонт и стройка https://remontkit.ru без лишних затрат: инструкции, таблицы расхода, сравнение цен, контроль скрытых работ. База подрядчиков, отзывы, чек-листы, калькуляторы. Тренды дизайна, 3D-планировки, лайфхаки по хранению и зонированию. Практика и цифры.
Все про ремонт https://lesnayaskazka74.ru и строительство: от идеи до сдачи. Пошаговые гайды, электрика и инженерия, отделка, фасады и кровля. Подбор подрядчиков, сметы, шаблоны актов и договоров. Дизайн-инспирации, палитры, мебель и свет.
Все про ремонт https://lesnayaskazka74.ru и строительство: от идеи до сдачи. Пошаговые гайды, электрика и инженерия, отделка, фасады и кровля. Подбор подрядчиков, сметы, шаблоны актов и договоров. Дизайн-инспирации, палитры, мебель и свет.
Все про ремонт https://lesnayaskazka74.ru и строительство: от идеи до сдачи. Пошаговые гайды, электрика и инженерия, отделка, фасады и кровля. Подбор подрядчиков, сметы, шаблоны актов и договоров. Дизайн-инспирации, палитры, мебель и свет.
Ремонт и строительство https://nastil69.ru от А до Я: планирование, закупка, логистика, контроль и приёмка. Калькуляторы смет, типовые договора, инструкции по инженерным сетям. Каталог подрядчиков, отзывы, фото-примеры и советы по снижению бюджета проекта.
Нужен аккумулятор? аккумулятор автомобильный купить с доставкой и установкой в наличии: топ-бренды, все размеры, правый/левый токовывод. Бесплатная проверка генератора при установке, trade-in старого АКБ. Гарантия до 3 лет, честные цены, быстрый самовывоз и курьер. Поможем выбрать за 3 минуты.
Хочешь сдать акб? скупка аккумуляторов честная цена за кг, моментальная выплата, официальная утилизация. Самовывоз от 1 шт. или приём на пункте, акт/квитанция. Безопасно и законно. Узнайте текущий тариф и ближайший адрес.
Ремонт и строительство https://nastil69.ru от А до Я: планирование, закупка, логистика, контроль и приёмка. Калькуляторы смет, типовые договора, инструкции по инженерным сетям. Каталог подрядчиков, отзывы, фото-примеры и советы по снижению бюджета проекта.
Нужен аккумулятор? аккумулятор с доставкой спб в наличии: топ-бренды, все размеры, правый/левый токовывод. Бесплатная проверка генератора при установке, trade-in старого АКБ. Гарантия до 3 лет, честные цены, быстрый самовывоз и курьер. Поможем выбрать за 3 минуты.
Хочешь сдать акб? сдать аккумулятор цена честная цена за кг, моментальная выплата, официальная утилизация. Самовывоз от 1 шт. или приём на пункте, акт/квитанция. Безопасно и законно. Узнайте текущий тариф и ближайший адрес.
Ищешь аккумулятор? купить акб AKB SHOP занимает лидирующие позиции среди интернет-магазинов автомобильных аккумуляторов в Санкт-Петербурге. Наш ассортимент охватывает все категории транспортных средств. Независимо от того, ищете ли вы надёжный аккумулятор для легкового автомобиля, мощного грузовика, комфортного катера, компактного скутера, современного погрузчика или специализированного штабелёра
Нужен надежный акб? купить аккумулятор для авто недорого AKB STORE — ведущий интернет-магазин автомобильных аккумуляторов в Санкт-Петербурге! Мы специализируемся на продаже качественных аккумуляторных батарей для самой разнообразной техники. В нашем каталоге вы найдёте идеальные решения для любого транспортного средства: будь то легковой или грузовой автомобиль, катер или лодка, скутер или мопед, погрузчик или штабелер.
Ищешь аккумулятор? магазин аккумуляторы в петербурге AKB SHOP занимает лидирующие позиции среди интернет-магазинов автомобильных аккумуляторов в Санкт-Петербурге. Наш ассортимент охватывает все категории транспортных средств. Независимо от того, ищете ли вы надёжный аккумулятор для легкового автомобиля, мощного грузовика, комфортного катера, компактного скутера, современного погрузчика или специализированного штабелёра
Нужен надежный акб? магазин аккумуляторов в спб AKB STORE — ведущий интернет-магазин автомобильных аккумуляторов в Санкт-Петербурге! Мы специализируемся на продаже качественных аккумуляторных батарей для самой разнообразной техники. В нашем каталоге вы найдёте идеальные решения для любого транспортного средства: будь то легковой или грузовой автомобиль, катер или лодка, скутер или мопед, погрузчик или штабелер.
Hello there! This post could not be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this write-up to him. Pretty sure he will have a good read. Many thanks for sharing!
keepstyle
Актуальные новости автопрома https://myrexton.ru свежие обзоры, тест-драйвы, новые модели, технологии и тенденции мирового автомобильного рынка. Всё самое важное — в одном месте.
Строительный портал https://stroimsami.online новости, инструкции, идеи и лайфхаки. Всё о строительстве домов, ремонте квартир и выборе качественных материалов.
Новостной портал https://daily-inform.ru с последними событиями дня. Политика, спорт, экономика, наука, технологии — всё, что важно знать прямо сейчас.
Актуальные новости автопрома https://myrexton.ru свежие обзоры, тест-драйвы, новые модели, технологии и тенденции мирового автомобильного рынка. Всё самое важное — в одном месте.
Строительный портал https://stroimsami.online новости, инструкции, идеи и лайфхаки. Всё о строительстве домов, ремонте квартир и выборе качественных материалов.
Новостной портал https://daily-inform.ru с последними событиями дня. Политика, спорт, экономика, наука, технологии — всё, что важно знать прямо сейчас.
Откройте для себя новые возможности с перетяжкой мебели в Минске, позволяющей обновить ваш интерьер и продлить жизнь любимым предметам!
Квалифицированные специалисты помогут сделать правильный выбор.
新车即将上线 真正的项目,期待你的参与
"аренда инструмента в слуцке – выгодные условия и широкий выбор инструментов для любых задач."
Покупка профессионального оборудования требует больших затрат, а аренда дает доступ к качественному инструменту без лишних расходов.
Такой подход особенно удобен для строителей и мастеров. Многие профессионалы предпочитают брать инструмент напрокат, так как это снижает затраты на выполнение работ.
#### **2. Какой инструмент можно взять в аренду?**
В Слуцке доступен широкий ассортимент оборудования для разных задач. В прокате представлены бензопилы, газонокосилки и другая садовая техника.
Кроме того, в аренду сдают и специализированную технику. Для укладки плитки можно взять плиткорезы, а для покраски – краскопульты.
#### **3. Преимущества аренды инструмента**
Главный плюс – экономия на обслуживании и хранении. Все инструменты проходят регулярное обслуживание, поэтому клиенты получают только исправные устройства.
Дополнительный бонус – помощь в выборе подходящего оборудования. Опытные менеджеры подскажут, какая модель лучше справится с работой.
#### **4. Как оформить аренду в Слуцке?**
Процедура аренды максимально проста и прозрачна. Вы можете приехать в офис, чтобы лично выбрать подходящий инструмент.
Условия проката выгодны для всех клиентов. На длительные периоды предоставляются скидки и специальные предложения.
---
### **Спин-шаблон статьи**
#### **1. Почему аренда инструмента – это выгодно?**
Аренда инструмента в Слуцке позволяет избежать лишних затрат . Вместо того чтобы покупать инструмент, который может понадобиться всего несколько раз, выгоднее взять его в аренду по доступной цене.
Такой подход особенно удобен для профессионалов и любителей . Многие профессионалы предпочитают брать инструмент напрокат, так как это снижает затраты на выполнение работ .
#### **2. Какой инструмент можно взять в аренду?**
В Слуцке доступен большой выбор техники для строительства и ремонта . Для строительных работ доступны бетономешалки, виброплиты и леса.
Кроме того, в аренду сдают и специализированную технику . Если нужно работать на высоте, доступны подъемники и строительные леса .
#### **3. Преимущества аренды инструмента**
Главный плюс – отсутствие необходимости в ремонте . Вам не придется беспокоиться о ремонте инструмента, так как за ним следят специалисты .
Дополнительный бонус – поддержка на всех этапах аренды. Опытные менеджеры подскажут, какая модель лучше справится с работой .
#### **4. Как оформить аренду в Слуцке?**
Процедура аренды не требует сложных формальностей . Для оформления понадобится только паспорт и небольшой залог.
Условия проката предполагают гибкие тарифы. На длительные периоды предоставляются скидки и специальные предложения .
Seo аудит онлайн https://seo-audit-sajta.ru
Need TRON Energy? rent tron energy instantly and save on TRX transaction fees. Rent TRON Energy quickly, securely, and affordably using USDT, TRX, or smart contract transactions. No hidden fees—maximize the efficiency of your blockchain.
Seo аудит https://seo-audit-sajta.ru
Need TRON Energy? buy tron energy instantly and save on TRX transaction fees. Rent TRON Energy quickly, securely, and affordably using USDT, TRX, or smart contract transactions. No hidden fees—maximize the efficiency of your blockchain.
Need porn videos or photos? porn ai website – create erotic content based on text descriptions. Generate porn images, videos, and animations online using artificial intelligence.
IPTV форум https://vip-tv.org.ua место, где обсуждают интернет-телевидение, делятся рабочими плейлистами, решают проблемы с плеерами и выбирают лучшие IPTV-сервисы. Присоединяйтесь к сообществу интернет-ТВ!
Need porn videos or photos? ai nsfw video maker – create erotic content based on text descriptions. Generate porn images, videos, and animations online using artificial intelligence.
IPTV форум https://vip-tv.org.ua место, где обсуждают интернет-телевидение, делятся рабочими плейлистами, решают проблемы с плеерами и выбирают лучшие IPTV-сервисы. Присоединяйтесь к сообществу интернет-ТВ!
Всё о металлообработке https://j-metall.ru/ и металлах: технологии, оборудование, сплавы и производство. Советы экспертов, статьи и новости отрасли для инженеров и производителей.
Всё о металлообработке http://j-metall.ru и металлах: технологии, оборудование, сплавы и производство. Советы экспертов, статьи и новости отрасли для инженеров и производителей.
Хочешь сдать металл? скупка металлолома в санкт-петербурге наша компания специализируется на профессиональном приёме металлолома уже на протяжении многих лет. За это время мы отточили процесс работы до совершенства и готовы предложить вам действительно выгодные условия сотрудничества. Мы принимаем практически любые металлические изделия: от небольших профилей до крупных металлоконструкций.
Есть металлолом? скупка металлолома в спб мы предлагаем полный цикл услуг по приему металлолома в Санкт-Петербурге, включая оперативную транспортировку материалов непосредственно на перерабатывающий завод. Особое внимание мы уделяем удобству наших клиентов. Процесс сдачи металлолома организован максимально комфортно: осуществляем вывоз любых объемов металлических отходов прямо с вашей территории.
Есть металлолом? сдать чермет мы предлагаем полный цикл услуг по приему металлолома в Санкт-Петербурге, включая оперативную транспортировку материалов непосредственно на перерабатывающий завод. Особое внимание мы уделяем удобству наших клиентов. Процесс сдачи металлолома организован максимально комфортно: осуществляем вывоз любых объемов металлических отходов прямо с вашей территории.
Хочешь сдать металл? сдать металлолом в санкт-петербурге наша компания специализируется на профессиональном приёме металлолома уже на протяжении многих лет. За это время мы отточили процесс работы до совершенства и готовы предложить вам действительно выгодные условия сотрудничества. Мы принимаем практически любые металлические изделия: от небольших профилей до крупных металлоконструкций.
Нужна карта? https://vc.ru/money/2063686-kak-poluchit-kartu-inostrannogo-banka-v-rossii-v-2025-godu как оформить зарубежную банковскую карту Visa или MasterCard для россиян в 2025 году. Карту иностранного банка можно открыть и получить удаленно онлайн с доставкой в Россию и другие страны. Зарубежные карты Visa и MasterCard подходят для оплаты за границей. Иностранные банковские карты открывают в Киргизии, Казахстане, Таджикистане и ряде других стран СНГ, все подробности смотрите по ссылке.
Нужна карта? https://vc.ru/money/2104862-kak-poluchit-kartu-visa-ili-mastercard-v-rossii-v-2025-godu как оформить зарубежную банковскую карту Visa или MasterCard для россиян в 2025 году. Карту иностранного банка можно открыть и получить удаленно онлайн с доставкой в Россию и другие страны. Зарубежные карты Visa и MasterCard подходят для оплаты за границей. Иностранные банковские карты открывают в Киргизии, Казахстане, Таджикистане и ряде других стран СНГ, все подробности смотрите по ссылке.
Строительный портал https://repair-house.kiev.ua всё о строительстве, ремонте и архитектуре. Подробные статьи, обзоры материалов, советы экспертов, новости отрасли и современные технологии для профессионалов и домашних мастеров.
Строительный портал https://intellectronics.com.ua источник актуальной информации о строительстве, ремонте и архитектуре. Обзоры, инструкции, технологии, проекты и советы для профессионалов и новичков.
Портал о стройке https://mr.org.ua всё о строительстве, ремонте и дизайне. Статьи, советы экспертов, современные технологии и обзоры материалов. Полезная информация для мастеров, инженеров и владельцев домов.
Строительный портал https://repair-house.kiev.ua всё о строительстве, ремонте и архитектуре. Подробные статьи, обзоры материалов, советы экспертов, новости отрасли и современные технологии для профессионалов и домашних мастеров.
Портал о стройке https://mr.org.ua всё о строительстве, ремонте и дизайне. Статьи, советы экспертов, современные технологии и обзоры материалов. Полезная информация для мастеров, инженеров и владельцев домов.
Строительный портал https://intellectronics.com.ua источник актуальной информации о строительстве, ремонте и архитектуре. Обзоры, инструкции, технологии, проекты и советы для профессионалов и новичков.
Актуальный портал https://sinergibumn.com о стройке и ремонте. Современные технологии, материалы, решения для дома и бизнеса. Полезные статьи, инструкции и рекомендации экспертов.
Актуальный портал https://sinergibumn.com о стройке и ремонте. Современные технологии, материалы, решения для дома и бизнеса. Полезные статьи, инструкции и рекомендации экспертов.
Онлайн женский портал https://replyua.net.ua секреты красоты, стиль, любовь, карьера и семья. Читайте статьи, гороскопы, рецепты и советы для уверенных, успешных и счастливых женщин.
Женский портал https://prins.kiev.ua всё о красоте, моде, отношениях, здоровье и саморазвитии. Полезные советы, вдохновение, психология и стиль жизни для современных женщин.
Современный женский https://novaya.com.ua портал о жизни, моде и гармонии. Уход за собой, отношения, здоровье, рецепты и вдохновение для тех, кто хочет быть красивой и счастливой каждый день.
Интересный женский https://muz-hoz.com.ua портал о моде, психологии, любви и красоте. Полезные статьи, тренды, рецепты и лайфхаки. Живи ярко, будь собой и вдохновляйся каждый день!
Женский портал https://z-b-r.org ваш источник идей и вдохновения. Советы по красоте, стилю, отношениям, карьере и дому. Всё, что важно знать современной женщине.
Онлайн женский портал https://replyua.net.ua секреты красоты, стиль, любовь, карьера и семья. Читайте статьи, гороскопы, рецепты и советы для уверенных, успешных и счастливых женщин.
Современный женский https://novaya.com.ua портал о жизни, моде и гармонии. Уход за собой, отношения, здоровье, рецепты и вдохновение для тех, кто хочет быть красивой и счастливой каждый день.
Женский портал https://prins.kiev.ua всё о красоте, моде, отношениях, здоровье и саморазвитии. Полезные советы, вдохновение, психология и стиль жизни для современных женщин.
Интересный женский https://muz-hoz.com.ua портал о моде, психологии, любви и красоте. Полезные статьи, тренды, рецепты и лайфхаки. Живи ярко, будь собой и вдохновляйся каждый день!
Женский портал https://z-b-r.org ваш источник идей и вдохновения. Советы по красоте, стилю, отношениям, карьере и дому. Всё, что важно знать современной женщине.
Онлайн авто портал https://retell.info всё для автолюбителей! Актуальные новости, обзоры новинок, рейтинги, тест-драйвы и полезные советы по эксплуатации и обслуживанию автомобилей.
Автомобильный портал https://autoguide.kyiv.ua для водителей и поклонников авто. Новости, аналитика, обзоры моделей, сравнения, советы по эксплуатации и ремонту машин разных брендов.
Авто портал https://psncodegeneratormiu.org мир машин в одном месте. Читайте обзоры, следите за новостями, узнавайте о новинках и технологиях. Полезный ресурс для автолюбителей и экспертов.
Авто портал https://bestsport.com.ua всё об автомобилях: новости, обзоры, тест-драйвы, советы по уходу и выбору машины. Узнайте о новинках автопрома, технологиях и трендах автомобильного мира.
Современный авто портал https://necin.com.ua мир автомобилей в одном месте. Тест-драйвы, сравнения, новости автопрома и советы экспертов. Будь в курсе последних тенденций автоиндустрии
Онлайн авто портал https://retell.info всё для автолюбителей! Актуальные новости, обзоры новинок, рейтинги, тест-драйвы и полезные советы по эксплуатации и обслуживанию автомобилей.
Автомобильный портал https://autoguide.kyiv.ua для водителей и поклонников авто. Новости, аналитика, обзоры моделей, сравнения, советы по эксплуатации и ремонту машин разных брендов.
Авто портал https://psncodegeneratormiu.org мир машин в одном месте. Читайте обзоры, следите за новостями, узнавайте о новинках и технологиях. Полезный ресурс для автолюбителей и экспертов.
Авто портал https://bestsport.com.ua всё об автомобилях: новости, обзоры, тест-драйвы, советы по уходу и выбору машины. Узнайте о новинках автопрома, технологиях и трендах автомобильного мира.
Современный авто портал https://necin.com.ua мир автомобилей в одном месте. Тест-драйвы, сравнения, новости автопрома и советы экспертов. Будь в курсе последних тенденций автоиндустрии
Портал про стройку https://dcsms.uzhgorod.ua всё о строительстве, ремонте и дизайне. Полезные советы, статьи, технологии, материалы и оборудование. Узнайте о современных решениях для дома и бизнеса.
Портал про стройку https://keravin.com.ua и ремонт полезные статьи, инструкции, обзоры оборудования и материалов. Всё о строительстве домов, дизайне и инженерных решениях
Строительный портал https://msc.com.ua о ремонте, дизайне и технологиях. Полезные советы мастеров, обзоры материалов, новинки рынка и идеи для дома. Всё о стройке — от фундамента до отделки. Учись, строй и вдохновляйся вместе с нами!
Онлайн-портал про стройку https://donbass.org.ua и ремонт. Новости, проекты, инструкции, обзоры материалов и технологий. Всё, что нужно знать о современном строительстве и архитектуре.
Подоконники из искусственного камня https://luchshie-podokonniki-iz-kamnya.ru в Москве. Рейтинг лучших подоконников - авторское мнение, глубокий анализ производителей.
Портал про стройку https://dcsms.uzhgorod.ua всё о строительстве, ремонте и дизайне. Полезные советы, статьи, технологии, материалы и оборудование. Узнайте о современных решениях для дома и бизнеса.
Портал про стройку https://keravin.com.ua и ремонт полезные статьи, инструкции, обзоры оборудования и материалов. Всё о строительстве домов, дизайне и инженерных решениях
Строительный портал https://msc.com.ua о ремонте, дизайне и технологиях. Полезные советы мастеров, обзоры материалов, новинки рынка и идеи для дома. Всё о стройке — от фундамента до отделки. Учись, строй и вдохновляйся вместе с нами!
Онлайн-портал про стройку https://donbass.org.ua и ремонт. Новости, проекты, инструкции, обзоры материалов и технологий. Всё, что нужно знать о современном строительстве и архитектуре.
Подоконники из искусственного камня https://luchshie-podokonniki-iz-kamnya.ru в Москве. Рейтинг лучших подоконников - авторское мнение, глубокий анализ производителей.
Советы по строительству https://vodocar.com.ua и ремонту своими руками. Пошаговые инструкции, современные технологии, идеи для дома и участка. Мы поможем сделать ремонт проще, а строительство — надёжнее!
Сайт о строительстве https://valkbolos.com и ремонте домов, квартир и дач. Полезные советы мастеров, подбор материалов, дизайн-идеи, инструкции и обзоры инструментов. Всё, что нужно для качественного ремонта и современного строительства!
Полезный сайт https://stroy-portal.kyiv.ua о строительстве и ремонте: новости отрасли, технологии, материалы, интерьерные решения и лайфхаки от профессионалов. Всё для тех, кто строит, ремонтирует и создаёт уют.
Строительный сайт https://teplo.zt.ua для тех, кто создаёт дом своей мечты. Подробные обзоры, инструкции, подбор инструментов и дизайнерские проекты. Всё о ремонте и строительстве в одном месте.
Советы по строительству https://vodocar.com.ua и ремонту своими руками. Пошаговые инструкции, современные технологии, идеи для дома и участка. Мы поможем сделать ремонт проще, а строительство — надёжнее!
Информационный портал https://smallbusiness.dp.ua про строительство, ремонт и интерьер. Свежие новости отрасли, обзоры технологий и полезные лайфхаки. Всё, что нужно знать о стройке и благоустройстве жилья в одном месте!
Сайт о строительстве https://valkbolos.com и ремонте домов, квартир и дач. Полезные советы мастеров, подбор материалов, дизайн-идеи, инструкции и обзоры инструментов. Всё, что нужно для качественного ремонта и современного строительства!
Полезный сайт https://stroy-portal.kyiv.ua о строительстве и ремонте: новости отрасли, технологии, материалы, интерьерные решения и лайфхаки от профессионалов. Всё для тех, кто строит, ремонтирует и создаёт уют.
Строительный сайт https://teplo.zt.ua для тех, кто создаёт дом своей мечты. Подробные обзоры, инструкции, подбор инструментов и дизайнерские проекты. Всё о ремонте и строительстве в одном месте.
Информационный портал https://smallbusiness.dp.ua про строительство, ремонт и интерьер. Свежие новости отрасли, обзоры технологий и полезные лайфхаки. Всё, что нужно знать о стройке и благоустройстве жилья в одном месте!
Энциклопедия строительства https://kero.com.ua и ремонта: материалы, технологии, интерьерные решения и практические рекомендации. От фундамента до декора — всё, что нужно знать домовладельцу.
Строим и ремонтируем https://buildingtips.kyiv.ua своими руками! Инструкции, советы, видеоуроки и лайфхаки для дома и дачи. Узнай, как сделать ремонт качественно и сэкономить бюджет.
Пошаговые советы https://tsentralnyi.volyn.ua по строительству и ремонту. Узнай, как выбрать материалы, рассчитать бюджет и избежать ошибок. Простые решения для сложных задач — строим и ремонтируем с уверенностью!
Новостной портал https://kiev-online.com.ua с проверенной информацией. Свежие события, аналитика, репортажи и интервью. Узнавайте новости первыми — достоверно, быстро и без лишнего шума.
Главные новости дня https://sevsovet.com.ua эксклюзивные материалы, горячие темы и аналитика. Мы рассказываем то, что действительно важно. Будь в курсе вместе с нашим новостным порталом!
Энциклопедия строительства https://kero.com.ua и ремонта: материалы, технологии, интерьерные решения и практические рекомендации. От фундамента до декора — всё, что нужно знать домовладельцу.
Строим и ремонтируем https://buildingtips.kyiv.ua своими руками! Инструкции, советы, видеоуроки и лайфхаки для дома и дачи. Узнай, как сделать ремонт качественно и сэкономить бюджет.
Пошаговые советы https://tsentralnyi.volyn.ua по строительству и ремонту. Узнай, как выбрать материалы, рассчитать бюджет и избежать ошибок. Простые решения для сложных задач — строим и ремонтируем с уверенностью!
Новостной портал https://kiev-online.com.ua с проверенной информацией. Свежие события, аналитика, репортажи и интервью. Узнавайте новости первыми — достоверно, быстро и без лишнего шума.
Главные новости дня https://sevsovet.com.ua эксклюзивные материалы, горячие темы и аналитика. Мы рассказываем то, что действительно важно. Будь в курсе вместе с нашим новостным порталом!
Строительный портал https://sitetime.kiev.ua для мастеров и подрядчиков. Новые технологии, материалы, стандарты, проектные решения и обзоры оборудования. Всё, что нужно специалистам стройиндустрии.
Строим и ремонтируем https://srk.kiev.ua грамотно! Инструкции, пошаговые советы, видеоуроки и экспертные рекомендации. Узнай, как сделать ремонт качественно и сэкономить без потери результата.
Сайт о стройке https://samozahist.org.ua и ремонте для всех, кто любит уют и порядок. Расскажем, как выбрать материалы, обновить интерьер и избежать ошибок при ремонте. Всё просто, полезно и по делу.
Обустраивайте дом https://stroysam.kyiv.ua со вкусом! Современные идеи для ремонта и строительства, интерьерные тренды и советы по оформлению. Создайте стильное и уютное пространство своими руками.
Как построить https://rus3edin.org.ua и отремонтировать своими руками? Пошаговые инструкции, простые советы и подбор инструментов. Делаем ремонт доступным и понятным для каждого!
Строительный портал https://sitetime.kiev.ua для мастеров и подрядчиков. Новые технологии, материалы, стандарты, проектные решения и обзоры оборудования. Всё, что нужно специалистам стройиндустрии.
Строим и ремонтируем https://srk.kiev.ua грамотно! Инструкции, пошаговые советы, видеоуроки и экспертные рекомендации. Узнай, как сделать ремонт качественно и сэкономить без потери результата.
Сайт о стройке https://samozahist.org.ua и ремонте для всех, кто любит уют и порядок. Расскажем, как выбрать материалы, обновить интерьер и избежать ошибок при ремонте. Всё просто, полезно и по делу.
Обустраивайте дом https://stroysam.kyiv.ua со вкусом! Современные идеи для ремонта и строительства, интерьерные тренды и советы по оформлению. Создайте стильное и уютное пространство своими руками.
Как построить https://rus3edin.org.ua и отремонтировать своими руками? Пошаговые инструкции, простые советы и подбор инструментов. Делаем ремонт доступным и понятным для каждого!
Сайт для женщин https://oun-upa.org.ua которые ценят себя и жизнь. Мода, советы по уходу, любовь, семья, вдохновение и развитие. Найди идеи для новых свершений и будь самой собой в мире, где важно быть уникальной!
Портал для автомобилистов https://translit.com.ua от выбора машины до профессионального ремонта. Читайте обзоры авто, новости автоспорта, сравнивайте цены и характеристики. Форум автолюбителей, советы экспертов и свежие предложения автосалонов.
Мужской онлайн-журнал https://cruiser.com.ua о современных трендах, технологиях и саморазвитии. Мы пишем о том, что важно мужчине — от мотивации и здоровья до отдыха и финансов.
Мужской сайт https://rkas.org.ua о жизни без компромиссов: спорт, путешествия, техника, карьера и отношения. Для тех, кто ценит свободу, силу и уверенность в себе.
Ваш гид в мире https://nerjalivingspace.com автомобилей! Ежедневные авто новости, рейтинги, тест-драйвы и советы по эксплуатации. Найдите идеальный автомобиль, узнайте о страховании, кредитах и тюнинге.
Сайт для женщин https://oun-upa.org.ua которые ценят себя и жизнь. Мода, советы по уходу, любовь, семья, вдохновение и развитие. Найди идеи для новых свершений и будь самой собой в мире, где важно быть уникальной!
Портал для автомобилистов https://translit.com.ua от выбора машины до профессионального ремонта. Читайте обзоры авто, новости автоспорта, сравнивайте цены и характеристики. Форум автолюбителей, советы экспертов и свежие предложения автосалонов.
Мужской онлайн-журнал https://cruiser.com.ua о современных трендах, технологиях и саморазвитии. Мы пишем о том, что важно мужчине — от мотивации и здоровья до отдыха и финансов.
Мужской сайт https://rkas.org.ua о жизни без компромиссов: спорт, путешествия, техника, карьера и отношения. Для тех, кто ценит свободу, силу и уверенность в себе.
Ваш гид в мире https://nerjalivingspace.com автомобилей! Ежедневные авто новости, рейтинги, тест-драйвы и советы по эксплуатации. Найдите идеальный автомобиль, узнайте о страховании, кредитах и тюнинге.
Портал о дизайне https://sculptureproject.org.ua интерьеров и пространства. Идеи, тренды, проекты и вдохновение для дома, офиса и общественных мест. Советы дизайнеров и примеры стильных решений каждый день.
Строительный сайт https://okna-k.com.ua для профессионалов и новичков. Новости отрасли, обзоры материалов, технологии строительства и ремонта, советы мастеров и пошаговые инструкции для качественного результата.
Сайт о металлах https://metalprotection.com.ua и металлообработке: виды металлов, сплавы, технологии обработки, оборудование и новости отрасли. Всё для специалистов и профессионалов металлургии.
Главный автопортал страны https://nmiu.org.ua всё об автомобилях в одном месте! Новости, обзоры, советы, автообъявления, страхование, ТО и сервис. Для водителей, механиков и просто любителей машин.
Женский онлайн-журнал https://rosetti.com.ua о стиле, здоровье и семье. Новости моды, советы экспертов, тренды красоты и секреты счастья. Всё, что важно и интересно женщинам любого возраста.
Портал о дизайне https://sculptureproject.org.ua интерьеров и пространства. Идеи, тренды, проекты и вдохновение для дома, офиса и общественных мест. Советы дизайнеров и примеры стильных решений каждый день.
Строительный сайт https://okna-k.com.ua для профессионалов и новичков. Новости отрасли, обзоры материалов, технологии строительства и ремонта, советы мастеров и пошаговые инструкции для качественного результата.
Сайт о металлах https://metalprotection.com.ua и металлообработке: виды металлов, сплавы, технологии обработки, оборудование и новости отрасли. Всё для специалистов и профессионалов металлургии.
Главный автопортал страны https://nmiu.org.ua всё об автомобилях в одном месте! Новости, обзоры, советы, автообъявления, страхование, ТО и сервис. Для водителей, механиков и просто любителей машин.
Женский онлайн-журнал https://rosetti.com.ua о стиле, здоровье и семье. Новости моды, советы экспертов, тренды красоты и секреты счастья. Всё, что важно и интересно женщинам любого возраста.
Студия ремонта https://anti-orange.com.ua квартир и домов. Выполняем ремонт под ключ, дизайн-проекты, отделочные и инженерные работы. Качество, сроки и индивидуальный подход к каждому клиенту.
Туристический портал https://feokurort.com.ua для любителей путешествий! Страны, маршруты, достопримечательности, советы и лайфхаки. Планируйте отдых, находите вдохновение и открывайте мир вместе с нами.
Студия ремонта https://anti-orange.com.ua квартир и домов. Выполняем ремонт под ключ, дизайн-проекты, отделочные и инженерные работы. Качество, сроки и индивидуальный подход к каждому клиенту.
Туристический портал https://feokurort.com.ua для любителей путешествий! Страны, маршруты, достопримечательности, советы и лайфхаки. Планируйте отдых, находите вдохновение и открывайте мир вместе с нами.
Студия дизайна https://bathen.rv.ua интерьеров и архитектурных решений. Создаём стильные, функциональные и гармоничные пространства. Индивидуальный подход, авторские проекты и внимание к деталям.
Ремонт и строительство https://fmsu.org.ua без лишних сложностей! Подробные статьи, обзоры инструментов, лайфхаки и практические советы. Мы поможем построить, отремонтировать и обустроить ваш дом.
Студия дизайна https://bathen.rv.ua интерьеров и архитектурных решений. Создаём стильные, функциональные и гармоничные пространства. Индивидуальный подход, авторские проекты и внимание к деталям.
Ремонт и строительство https://fmsu.org.ua без лишних сложностей! Подробные статьи, обзоры инструментов, лайфхаки и практические советы. Мы поможем построить, отремонтировать и обустроить ваш дом.
pronostic foot gratuit telecharger 1xbet apk
paris sportif foot paris sportif foot
telecharger 1xbet cameroun pronostics du foot
Современная студия дизайна https://bconline.com.ua архитектура, интерьер, декор. Мы создаём пространства, где технологии сочетаются с красотой, а стиль — с удобством.
pronostic foot gratuit afrik foot pronostic
melbet - paris sportif africain foot
telecharger 1xbet apk africain foot
Создавайте дом https://it-cifra.com.ua своей мечты! Всё о строительстве, ремонте и дизайне интерьера. Идеи, проекты, фото и инструкции — вдохновляйтесь и воплощайте задуманное легко и с удовольствием.
Современная студия дизайна https://bconline.com.ua архитектура, интерьер, декор. Мы создаём пространства, где технологии сочетаются с красотой, а стиль — с удобством.
football africain telecharger 1xbet
telecharger 1xbet https://parifoot-afrique1.com
parier pour le foot info foot africain
Создавайте дом https://it-cifra.com.ua своей мечты! Всё о строительстве, ремонте и дизайне интерьера. Идеи, проекты, фото и инструкции — вдохновляйтесь и воплощайте задуманное легко и с удовольствием.
Мир архитектуры https://vineyardartdecor.com и дизайна в одном месте! Лучшие идеи, проекты и вдохновение для дома, офиса и города. Узнай, как создаются красивые и функциональные пространства.
Мир архитектуры https://vineyardartdecor.com и дизайна в одном месте! Лучшие идеи, проекты и вдохновение для дома, офиса и города. Узнай, как создаются красивые и функциональные пространства.
Частный заем денег домашние деньги онлайн альтернатива банковскому кредиту. Быстро, безопасно и без бюрократии. Получите нужную сумму наличными или на карту за считанные минуты.
Частный заем денег домашние деньги официальный сайт альтернатива банковскому кредиту. Быстро, безопасно и без бюрократии. Получите нужную сумму наличными или на карту за считанные минуты.
Все спортивные новости http://sportsat.ru в реальном времени. Итоги матчей, трансферы, рейтинги и обзоры. Следите за событиями мирового спорта и оставайтесь в курсе побед и рекордов!
Все спортивные новости http://sportsat.ru в реальном времени. Итоги матчей, трансферы, рейтинги и обзоры. Следите за событиями мирового спорта и оставайтесь в курсе побед и рекордов!
Suchen Sie Immobilien? http://www.montenegro-immobilien-kaufen.com wohnungen, Villen und Grundstucke mit Meerblick. Aktuelle Preise, Fotos, Auswahlhilfe und umfassende Transaktionsunterstutzung.
Suchen Sie Immobilien? montenegro-immobilien-kaufen.com wohnungen, Villen und Grundstucke mit Meerblick. Aktuelle Preise, Fotos, Auswahlhilfe und umfassende Transaktionsunterstutzung.
фитнес клуб с бассейном https://fitnes-klub-msk.ru
фитнес клуб с бассейном фитнес клуб москва цены
Автобусы аренда перевозки https://povozkin.ru
Снять автобус в аренду с водителем https://povozkin.ru
фитнес клуб с бассейном новый фитнес клуб
Лазерные станки https://raymark.ru для резки металла в Москве. 20 лет на рынке, выгодная цена, скидка 5% при заявке с сайта + обучение
HOME CLIMAT https://homeclimat36.ru кондиционеры и сплит системы в Воронеже. Скидка на монтаж от 3000 рублей! При покупке сплит-системы.
Лазерные станки https://raymark.ru для резки металла в Москве. 20 лет на рынке, выгодная цена, скидка 5% при заявке с сайта + обучение
HOME CLIMAT https://homeclimat36.ru кондиционеры и сплит системы в Воронеже. Скидка на монтаж от 3000 рублей! При покупке сплит-системы.
Нужна недвижимость? https://www.nedvizhimost-chernogorii-u-morya.ru/ лучшие объекты для жизни и инвестиций. Виллы, квартиры и дома у моря. Помощь в подборе, оформлении и сопровождении сделки на всех этапах.
Аутстаффинг персонала https://skillstaff2.ru для бизнеса: легальное оформление сотрудников, снижение налоговой нагрузки и оптимизация расходов. Работаем с компаниями любого масштаба и отрасли.
Нужна недвижимость? недвижимость Черногории купить лучшие объекты для жизни и инвестиций. Виллы, квартиры и дома у моря. Помощь в подборе, оформлении и сопровождении сделки на всех этапах.
Аутстаффинг персонала https://skillstaff2.ru для бизнеса: легальное оформление сотрудников, снижение налоговой нагрузки и оптимизация расходов. Работаем с компаниями любого масштаба и отрасли.
Строительный портал https://v-stroit.ru всё о строительстве, ремонте и архитектуре. Полезные советы, технологии, материалы, новости отрасли и практические инструкции для мастеров и новичков.
Строительный портал https://v-stroit.ru всё о строительстве, ремонте и архитектуре. Полезные советы, технологии, материалы, новости отрасли и практические инструкции для мастеров и новичков.
Риэлторская контора https://daber27.ru покупка, продажа и аренда недвижимости. Помогаем оформить сделки безопасно и выгодно. Опытные риэлторы, консультации, сопровождение и проверка документов.
Купольные дома https://kupol-doma.ru под ключ — энергоэффективные, надёжные и современные. Проектирование, строительство и отделка. Уникальная архитектура, комфорт и долговечность в каждом доме.
Риэлторская контора https://daber27.ru покупка, продажа и аренда недвижимости. Помогаем оформить сделки безопасно и выгодно. Опытные риэлторы, консультации, сопровождение и проверка документов.
Купольные дома https://kupol-doma.ru под ключ — энергоэффективные, надёжные и современные. Проектирование, строительство и отделка. Уникальная архитектура, комфорт и долговечность в каждом доме.
Ваша Недвижимость https://rbn-khv.ru сайт о покупке, продаже и аренде жилья. Разбираем сделки, налоги, ипотеку и инвестиции. Полезная информация для владельцев и покупателей недвижимости.
Информационный блог https://gidroekoproekt.ru для инженеров и проектировщиков. Всё об инженерных изысканиях, водохозяйственных объектах, гидротехническом строительстве и современных технологиях в отрасли.
Ваша Недвижимость https://rbn-khv.ru сайт о покупке, продаже и аренде жилья. Разбираем сделки, налоги, ипотеку и инвестиции. Полезная информация для владельцев и покупателей недвижимости.
Информационный блог https://gidroekoproekt.ru для инженеров и проектировщиков. Всё об инженерных изысканиях, водохозяйственных объектах, гидротехническом строительстве и современных технологиях в отрасли.
Деревянные лестницы https://rosslestnica.ru под заказ в любом стиле. Прямые, винтовые, маршевые конструкции из массива. Замеры, 3D-проект, доставка и установка. Гарантия качества и точности исполнения.
Деревянные лестницы https://rosslestnica.ru под заказ в любом стиле. Прямые, винтовые, маршевые конструкции из массива. Замеры, 3D-проект, доставка и установка. Гарантия качества и точности исполнения.
Should definitely buy fifa coins before attempting Icon SBCs or expensive player objectives to avoid mid-challenge resource shortages. Real sellers with fast service and active support plus non drop guarantees ensure you complete high-value challenges without interruption.
Competitive advantage comes when you buy fifa coins from sellers who understand EA's detection systems thoroughly. Real active vendors use fast but gradual delivery methods with non drop policies that maintain account safety.
Курсы по подготовке к ЕГЭ по русскому https://courses-ege.ru
Курсы по информатике ЕГЭ https://courses-ege.ru
Новости спорта онлайн http://sportsat.ru футбол, хоккей, бокс, теннис, баскетбол и другие виды спорта. Результаты матчей, обзоры, интервью, аналитика и главные события дня в мире спорта.
Новости спорта онлайн http://sportsat.ru футбол, хоккей, бокс, теннис, баскетбол и другие виды спорта. Результаты матчей, обзоры, интервью, аналитика и главные события дня в мире спорта.
1xbet cameroun apk melbet - paris sportif
melbet telecharger telecharger 1xbet cameroun
Все о коттеджных посёлках https://cottagecommunity.ru фото, описание, стоимость участков и домов. Всё о покупке, строительстве и жизни за городом в одном месте. Полезная информация для покупателей и инвесторов.
Все о коттеджных посёлках https://cottagecommunity.ru/sosnovka/ фото, описание, стоимость участков и домов. Всё о покупке, строительстве и жизни за городом в одном месте. Полезная информация для покупателей и инвесторов.
telecharger 1xbet pour android pariez sur le foot
Портал о строительстве домов https://doma-land.ru проекты и сметы, сравнение технологий (каркас, газобетон, кирпич, брус), фундамент и кровля, инженерия и утепление. Калькуляторы, чек-листы, тендер подрядчиков, рейтинги бригад, карта цен по регионам, готовые ведомости материалов и практика без ошибок.
Портал о строительстве домов https://doma-land.ru проекты и сметы, сравнение технологий (каркас, газобетон, кирпич, брус), фундамент и кровля, инженерия и утепление. Калькуляторы, чек-листы, тендер подрядчиков, рейтинги бригад, карта цен по регионам, готовые ведомости материалов и практика без ошибок.
Компания «СибЗТА» https://sibzta.su производит задвижки, клапаны и другую трубопроводную арматуру с 2014 года. Материалы: сталь, чугун, нержавейка. Прочные уплотнения, стандарты ГОСТ, индивидуальные решения под заказ, быстрая доставка и гарантия.
Компания «СибЗТА» https://sibzta.su производит задвижки, клапаны и другую трубопроводную арматуру с 2014 года. Материалы: сталь, чугун, нержавейка. Прочные уплотнения, стандарты ГОСТ, индивидуальные решения под заказ, быстрая доставка и гарантия.
займ без процентов https://zaimy-54.ru
займ срочно без проверок https://zaimy-57.ru
мгновенный онлайн займы https://zaimy-59.ru
кредитная карта займ https://zaimy-54.ru
займ срочно займ до зарплаты без отказа
взять займ на карту онлайн займ на карту в тот же день
займ на карту срочно https://zaimy-61.ru
денежный кредит займ срочные займы на карту круглосуточно
мгновенный онлайн займы https://zaimy-65.ru
займ на карту без отказа займ на карту за несколько минут
срочные займы без истории https://zaimy-61.ru
взять займ без отказа сайт микрозаймов
кредит займ https://zaimy-67.ru
финансовый займ список займов онлайн на карту
займ без истории микрозайм всем
займ без процентов https://zaimy-69.ru
где взять займ https://zaimy-67.ru
взять займ срочно https://zaimy-71.ru
займ онлайн без отказа https://zaimy-76.ru
мгновенный онлайн займы займы все онлайн
взять займ на карту https://zaimy-78.ru
где взять займ https://zaimy-78.ru
заем денежных средств деньги на карту моментально
займ без проверок https://zaimy-73.ru
срочно онлайн займ отказа https://zaimy-80.ru
взять займ без отказа https://zaimy-86.ru
взять займ онлайн онлайн займ на карту в тот же день
кредит займ микрозайм без отказа и звонков
займы онлайн https://zaimy-82.ru
денежный кредит займ займ с одобрением 99 процентов
финансовый займ https://zaimy-87.ru
денежный кредит займ https://zaimy-88.ru
займ срочно без отказа https://zaimy-89.ru
взять займ срочно получить онлайн займ круглосуточно
денежный займ https://zaimy-88.ru
кредитный займ всезаймы
срочные займы без истории список займов онлайн
займ без переплат займ с одобрением 99 процентов
Скачать видео с YouTube https://www.fsaved.com онлайн: MP4/WEBM/3GP, качество 144p–4K, конвертация в MP3/M4A, поддержка Shorts и плейлистов, субтитры и обложки. Без регистрации, быстро и безопасно, на телефоне и ПК. Используйте только с разрешения правообладателя и в рамках правил YouTube.
займ срочно оформить займ онлайн без комиссии
срочно деньги займ срочный займ с переводом на карту
Скачать видео с YouTube https://www.fsaved.com онлайн: MP4/WEBM/3GP, качество 144p–4K, конвертация в MP3/M4A, поддержка Shorts и плейлистов, субтитры и обложки. Без регистрации, быстро и безопасно, на телефоне и ПК. Используйте только с разрешения правообладателя и в рамках правил YouTube.
оформить займ займ денег онлайн
взять микрозайм онлайн займы
взять займ кредит займ
займы деньги взять займ
микрозайм получить деньги займ
микрозаймы онлайн займ кредит
Найдите лучший товар на https://n-katalog.ru: подробные карточки, честные отзывы, рейтинги, фото, фильтры по параметрам и брендам. Сравнение цен, акции, кэшбэк-предложения и графики изменений. Примите уверенное решение и переходите к покупке в удобном магазине.
микрозаймы онлайн займ денег онлайн
Kaart van https://fotoredaktor.top Kaapverdische eilanden gevonden.
Сравните цены на ноутбуки https://n-katalog.ru/category/noutbuki/list в десятках магазинов: для работы, учебы и игр. Характеристики, отзывы, фото, бенчмарки. Фильтры по процессору, ОЗУ, SSD, диагонали, видео, весу и автономности. Следите за акциями и динамикой стоимости — выбирайте выгодное предложение с доставкой.
деньги займ деньги займ
On the site https://fotoredaktor.top I easily found the location of Gambia.
Список на https://siviagmen.com майстрів вразив кількістю міст.
Различия между https://buybuyviamen.com изоспан А и Б наконец поняли.
На сайті mr-master.com.ua побачив, як зробити дровницю своїми руками.
Тестував на https://siviagmen.com зручність для мобільного телефону.
Идею для кровати https://buybuyviamen.com под окном подсмотрели на сайте.
Объяснения на https://mr-master.com.ua/ru/ помогли выбрать шторы вместо дверей.
На сайті zebraschool.com.ua замовив ремонт коляски у Чернівцях — усе пройшло без нарікань
На сторінці zebraschool.com.ua замовляв ремонт автомагнітоли у Вінниці — зробили якісно
Доставка пиццы в Туле https://pizzacuba.ru горячо и быстро. Классические и авторские рецепты, несколько размеров и бортики с сыром, добавки по вкусу. Онлайн-меню, акции «2 по цене 1», промокоды. Оплата картой/онлайн, бесконтактная доставка, трекинг заказа.
Energy Storage Systems https://e7repower.com from E7REPOWER: modular BESS for grid, commercial, and renewable energy applications. LFP batteries, bidirectional inverters, EMS, BMS, fire suppression. 10/20/40 ft containers, scalable to hundreds of MWh. Peak-saving, balancing, and backup. Engineering and service.
Доставка пиццы в Туле https://pizzacuba.ru горячо и быстро. Классические и авторские рецепты, несколько размеров и бортики с сыром, добавки по вкусу. Онлайн-меню, акции «2 по цене 1», промокоды. Оплата картой/онлайн, бесконтактная доставка, трекинг заказа.
Energy Storage Systems https://e7repower.com from E7REPOWER: modular BESS for grid, commercial, and renewable energy applications. LFP batteries, bidirectional inverters, EMS, BMS, fire suppression. 10/20/40 ft containers, scalable to hundreds of MWh. Peak-saving, balancing, and backup. Engineering and service.
Moldova - rent-auto.md/ro/ - Inchiriere auto Chisinau – arenda masini fara stres, rezervare rapida si cele mai bune preturi.
Sul sito https://fotoredaktor.top ho trovato dove si trova il Qatar.
Moldova - rent-auto.md/ro/ - Inchiriere auto Chisinau – arenda masini fara stres, rezervare rapida si cele mai bune preturi.
Академия Алины Аблязовой https://ablyazovaschool.ru обучение реконструкции волос для мастеров и новичков. Авторские методики, разбор трихологических основ, отработка на моделях, кейсы клиентов. Онлайн и офлайн, сертификат, поддержка кураторов, материалы и чек-листы.
Mapa Morza https://fotoredaktor.top Czerwonego byla przydatna.
Академия Алины Аблязовой https://ablyazovaschool.ru обучение реконструкции волос для мастеров и новичков. Авторские методики, разбор трихологических основ, отработка на моделях, кейсы клиентов. Онлайн и офлайн, сертификат, поддержка кураторов, материалы и чек-листы.
ЛідерUA - інформативний портал https://liderua.com новин та корисних порад: актуальні події України, аналітика, життєві лайфхаки та експертні рекомендації. Все — щоб бути в курсі й отримувати практичні рішення для щоденного життя та розвитку.
Лучшая подборка дня: https://journal-ua.com/kulinariia/yak-osvojiti-vashu-dukhovu-shafu-rezhimi-funktsiji-ta-sekreti-doskonalikh-strav.html
ЛідерUA - інформативний портал https://liderua.com новин та корисних порад: актуальні події України, аналітика, життєві лайфхаки та експертні рекомендації. Все — щоб бути в курсі й отримувати практичні рішення для щоденного життя та розвитку.
Читайте больше на сайте: https://journal-ua.com/didzhytal/prapor-vinder-potuzhnij-instrument-vizualnoji-komunikatsiji-v-reklami.html
Курсы маникюра https://econogti-school.ru и педикюра с нуля: теория + практика на моделях, стерилизация, архитектура ногтя, комбинированный/аппаратный маникюр, выравнивание, покрытие гель-лаком, классический и аппаратный педикюр. Малые группы, материалы включены, сертификат и помощь с трудоустройством.
Авторский MINI TATTOO https://kurs-mini-tattoo.ru дизайн маленьких тату, баланс и масштаб, безопасная стерилизация, грамотная анестезия, техника fine line и dotwork. Практика, разбор типовых косяков, правила ухода, фото/видео-съёмка работ. Материалы включены, сертификат и поддержка сообщества.
Курсы маникюра https://econogti-school.ru и педикюра с нуля: теория + практика на моделях, стерилизация, архитектура ногтя, комбинированный/аппаратный маникюр, выравнивание, покрытие гель-лаком, классический и аппаратный педикюр. Малые группы, материалы включены, сертификат и помощь с трудоустройством.
Авторский MINI TATTOO https://kurs-mini-tattoo.ru дизайн маленьких тату, баланс и масштаб, безопасная стерилизация, грамотная анестезия, техника fine line и dotwork. Практика, разбор типовых косяков, правила ухода, фото/видео-съёмка работ. Материалы включены, сертификат и поддержка сообщества.
changan cs75plus https://changan-v-spb.ru
changan размеры https://changan-v-spb.ru
Онлайн-блог https://intellector-school.ru о нейросетях: от базовой линейной алгебры до Transformer и LLM. Пошаговые проекты, код на Git-стиле, эксперименты, метрики, тюнинг гиперпараметров, ускорение на GPU. Обзоры курсов, книг и инструментов, подборка задач для практики и подготовки к интервью.
Освойте режиссуру https://rasputinacademy.ru событий и маркетинг: концепция, сценарий, сцена и свет, звук, видео, интерактив. Бюджет и смета, закупки, подрядчики, тайминг, риск-менеджмент. Коммьюнити, PR, лидогенерация, спонсорские пакеты, метрики ROI/ROMI. Практические задания и шаблоны документов.
Освойте режиссуру https://rasputinacademy.ru событий и маркетинг: концепция, сценарий, сцена и свет, звук, видео, интерактив. Бюджет и смета, закупки, подрядчики, тайминг, риск-менеджмент. Коммьюнити, PR, лидогенерация, спонсорские пакеты, метрики ROI/ROMI. Практические задания и шаблоны документов.
Онлайн-блог https://intellector-school.ru о нейросетях: от базовой линейной алгебры до Transformer и LLM. Пошаговые проекты, код на Git-стиле, эксперименты, метрики, тюнинг гиперпараметров, ускорение на GPU. Обзоры курсов, книг и инструментов, подборка задач для практики и подготовки к интервью.
Курсы по наращиванию https://schoollegoart.ru ресниц, архитектуре и ламинированию бровей/ресниц с нуля: теория + практика на моделях, стерильность, карта бровей, классика/2D–4D, составы и противопоказания. Материалы включены, мини-группы, сертификат, чек-листы и помощь с портфолио и стартом продаж.
PRP-курс для косметологов обучение прп-терапии доказательная база, отбор пациентов, подготовка образца, техники введения (лицо, шея, кожа головы), сочетание с мезо/микронидлингом. Практика, рекомендации по фото/видео-фиксации, юридические формы, маркетинг услуги. Сертификат и кураторство.
Курсы по наращиванию https://schoollegoart.ru ресниц, архитектуре и ламинированию бровей/ресниц с нуля: теория + практика на моделях, стерильность, карта бровей, классика/2D–4D, составы и противопоказания. Материалы включены, мини-группы, сертификат, чек-листы и помощь с портфолио и стартом продаж.
PRP-курс для косметологов плазмотерапия обучение в москве доказательная база, отбор пациентов, подготовка образца, техники введения (лицо, шея, кожа головы), сочетание с мезо/микронидлингом. Практика, рекомендации по фото/видео-фиксации, юридические формы, маркетинг услуги. Сертификат и кураторство.
Онлайн-курсы обучение прп: структурированная программа, стандарты стерильности, подготовка образца, минимизация рисков, протоколы для лица/шеи/кожи головы. Видеолекции и задания, разбор клинических ситуаций, пакет шаблонов для ведения пациента, экзамен и получение сертификата.
Онлайн-курсы обучение прп: структурированная программа, стандарты стерильности, подготовка образца, минимизация рисков, протоколы для лица/шеи/кожи головы. Видеолекции и задания, разбор клинических ситуаций, пакет шаблонов для ведения пациента, экзамен и получение сертификата.
Обновления по теме здесь: https://version.com.ua
Викторины и тесты бесплатно https://fankino.ru
Самое интересное клик: https://version.com.ua/kulinariia.html
Интересные новости кино https://fankino.ru
Онлайн-займ https://zaimy-57.ru без очередей: заполните форму, получите решение и деньги на карту. Выгодные ставки, понятный договор, кэшбэк и скидки при повторных обращениях. Напоминания о платежах, продление при необходимости. Выбирайте ответственно и экономьте.
Онлайн-займ https://zaimy-67.ru без очередей: заполните форму, получите решение и деньги на карту. Выгодные ставки, понятный договор, кэшбэк и скидки при повторных обращениях. Напоминания о платежах, продление при необходимости. Выбирайте ответственно и экономьте.
Фото из армии Про солдат су армейский альбом профессиональная съёмка армии: присяга, парады, учения. Создаём армейские альбомы, фотокниги, постеры; ретушь и цветокор, макеты, печать и доставка. Съёмочные группы по всей стране, аккредитация и дисциплина, чёткие сроки и цены.
Фото из армии Про солдат точка су профессиональная съёмка армии: присяга, парады, учения. Создаём армейские альбомы, фотокниги, постеры; ретушь и цветокор, макеты, печать и доставка. Съёмочные группы по всей стране, аккредитация и дисциплина, чёткие сроки и цены.
Мучает зуд и жжение? Геморой - лечение без боли и очередей: диагностика, консервативная терапия, латексное лигирование, склеротерапия, лазер. Приём проктолога, анонимно, в день обращения. Индивидуальный план, быстрое восстановление, понятные цены и поддержка 24/7.
chery 2025 chery tiggo
Мучает зуд и жжение? Геморой - лечение без боли и очередей: диагностика, консервативная терапия, латексное лигирование, склеротерапия, лазер. Приём проктолога, анонимно, в день обращения. Индивидуальный план, быстрое восстановление, понятные цены и поддержка 24/7.
Узнайте больше здесь: https://vesti42.ru/novosti-so-vsego-sveta/lazernaya-epilyacziya-bikini-dolgovremennaya-gladkost-i-komfort
Read more on the website: https://artofracing.eu/buy-facebook-ads-accounts-4/
Полная версия материала тут: https://aleksadmin.ru/bitrix/components/bitrix/blog/lang/ru/page/3/1/169_materiali_dlya_samokleyashchihsya_etiketok.html
chery 8 max chery tiggo pro
Details inside: https://bisd.rs/kupit-akkaunt-tiktok-tik-tok-9/
Хочешь вылечить геморрой - современный подход к лечению геморроя: точная диагностика, персональный план, амбулаторные процедуры за 20–30 минут. Контроль боли, быстрый возврат к активной жизни, рекомендации по образу жизни и профилактике, анонимность и понятные цены.
Современный атмосферный ресторан в Москве с открытой кухней: локальные фермерские ингредиенты, свежая выпечка, бар с коктейлями. Панорамные виды, терраса летом, детское меню. Бронирование столов онлайн, банкеты и дни рождения «под ключ».
Хочешь вылечить геморрой - современный подход к лечению геморроя: точная диагностика, персональный план, амбулаторные процедуры за 20–30 минут. Контроль боли, быстрый возврат к активной жизни, рекомендации по образу жизни и профилактике, анонимность и понятные цены.
Современный атмосферный ресторан в Москве с открытой кухней: локальные фермерские ингредиенты, свежая выпечка, бар с коктейлями. Панорамные виды, терраса летом, детское меню. Бронирование столов онлайн, банкеты и дни рождения «под ключ».
Нужна ликвидация? ликвидация фирмы в черногории: добровольная ликвидация, банкротство, реорганизация. Подготовка документов, публикации, сверка с ФНС/ПФР, закрытие счетов. Сроки по договору, прозрачная смета, конфиденциальность, сопровождение до внесения записи в ЕГРЮЛ.
Tasfiyeye mi ihtiyac?n?z var? Karadag sirket kapatma: borc analizi, yasal prosedurun secimi (istege bagl? veya iflas), alacakl?lar?n bildirimi, tasfiye bilancosu, sicilden silme. Son teslim tarihlerini ve sabit fiyat? netlestirin.
На сайте game-computers.ru собраны обзоры актуальных игровых сборок, с подробными характеристиками комплектующих и рекомендациями по их совместимости. Блог помогает выбрать оптимальные конфигурации, дает советы по апгрейду и настройке системы для комфортного гейминга.
Нужна ликвидация? https://www.zakrit-kompaniu-doo.me: добровольная ликвидация, банкротство, реорганизация. Подготовка документов, публикации, сверка с ФНС/ПФР, закрытие счетов. Сроки по договору, прозрачная смета, конфиденциальность, сопровождение до внесения записи в ЕГРЮЛ.
Tasfiyeye mi ihtiyac?n?z var? https://www.sirket-kapatma.me/: borc analizi, yasal prosedurun secimi (istege bagl? veya iflas), alacakl?lar?n bildirimi, tasfiye bilancosu, sicilden silme. Son teslim tarihlerini ve sabit fiyat? netlestirin.
На сайте публикуются обзоры игровых ПК, раскрывающие нюансы современных сборок. Блог рассматривает влияние видеокарт, процессоров и памяти на FPS, стабильность системы и производительность в разных играх, а также особенности редких конфигураций.
шторы умные Prokarniz - управляемые шторы, которые позволят вам легко контролировать свет и атмосферу в вашем доме.
Эти шторы не только функциональны, но и стильны.
электрический карниз Прокарниз позволяют управлять шторами с помощью одного нажатия кнопки, обеспечивая удобство и комфорт в вашем доме.
Они отлично справляются с задачей оформления больших окон и раздвижных дверей.
Удобные и стильные автоматические карнизы для тяжелых штор +7 (499) 638-25-37 делают управление шторами простым и комфортным.
Эти устройства позволяют управлять шторами с помощью пульта, смартфона или даже голосовых команд.
Одним из ключевых плюсов автоматических жалюзи является возможность регулировки света. Эти жалюзи позволяют корректировать количество света в зависимости от времени дня. Это особенно важно для людей, работающих на удаленке. Это обеспечивает комфортные условия как для работы, так и для отдыха.
жалюзи электронные Прокарниз обеспечивают удобство и стиль в вашем доме, позволяя управлять светом одним нажатием кнопки.
Автоматические жалюзи на окна с электроприводом становятся все более популярными. Их удобство и функциональность делают их отличным решением для современных интерьеров. Такие жалюзи могут управляться с помощью пульта дистанционного управления или смартфона. Дистанционное управление делает эксплуатацию жалюзи очень удобной.
Экономия энергии — еще один важный плюс автоматических жалюзи. С правильной эксплуатацией этих жалюзи можно значительно уменьшить расходы на обогрев и кондиционирование. С автоматическими жалюзи будет проще контролировать температуру в помещении. Таким образом, они не только удобны, но и экономически оправданы.
Важно отметить, что установка таких жалюзи может быть выполнена как специалистами, так и самостоятельно. Это зависит от ваших навыков и желания. Если вы решите установить жалюзи самостоятельно, следуйте инструкциям производителя. Это поможет избежать ошибок и обеспечит правильную работу системы.
Всё для дачи и цветов http://amandine.ru журнал с понятными инструкциями, схемами и списками покупок. Посев, пикировка, прививка, обрезка, подкормки, защита без лишней химии. Планировки теплиц, уход за газоном и цветниками, идеи декора, советы экспертов.
Need liquidation? company liquidation: voluntary liquidation, bankruptcy, reorganization. Document preparation, publications, reconciliation, account closure. Contractual terms, transparent estimates, confidentiality, support.
Всё для дачи и цветов https://amandine.ru журнал с понятными инструкциями, схемами и списками покупок. Посев, пикировка, прививка, обрезка, подкормки, защита без лишней химии. Планировки теплиц, уход за газоном и цветниками, идеи декора, советы экспертов.
Need liquidation? liquidation of a company: voluntary liquidation, bankruptcy, reorganization. Document preparation, publications, reconciliation, account closure. Contractual terms, transparent estimates, confidentiality, support.
Откройте для себя идеальное решение для защиты от солнца с автоматические рулонные жалюзи с электроприводом прокарниз, которые удобно управляются одним движением.
в различных цветах. Вы можете выбрать модель, которая идеально впишется в ваш интерьер
Одним из главных преимуществ таких штор является возможность управления с помощью пульта | Управление рулонными шторами с электроприводом осуществляется легко с помощью пульта | Электроприводные рулонные шторы предлагают комфортное управление через пульт. Это позволяет вам регулировать свет и атмосферу в комнате одним нажатием кнопки | Вы можете поменять уровень освещения в помещении всего лишь одним нажатием кнопки | С помощью простого нажатия кнопки вы сможете изменить интенсивность света в комнате.
Вы можете рулонные шторы на дистанционном управлении и наслаждаться комфортом и удобством в вашем доме.
Дизайн и функциональность электроприводных рулонных штор идеально сочетаются на современном рынке.
Помимо удобства, рулонные шторы с электроприводом также отличаются высоким качеством материалов
Обеспечьте комфорт и стиль в вашем доме с рулонные жалюзи с электроприводом, которые идеально впишутся в современный интерьер.
Умные рулонные шторы становятся все более популярными в современных интерьерах. Их применение позволяет не только удобно регулировать свет, но и добавить стиль в ваш дом. Такие шторы идеально вписываются в концепцию "умного дома".
Системы автоматизации позволяют контролировать рулонные шторы с помощью смартфона. Пользователь имеет возможность задавать график работы штор в зависимости от времени суток. Такой подход очень удобен делает жизнь более комфортной.
Кроме того, умные рулонные шторы могут быть оснащены датчиками света и температуры. Эти датчики автоматически регулируют положение штор для достижения оптимального уровня освещенности. Это значит, что вы можете экономить на электроэнергии благодаря естественному освещению.
Установка автоматических рулонных штор достаточно прост и не требует специальных навыков. Владельцы могут установить их самостоятельно, следуя инструкциям. После монтажа , вы сможете наслаждаться всеми преимуществами умного дома.
Карнизы с электроприводом становятся все более популярными в современных интерьере. Такие конструкции предлагают комфорт и стиль для любого помещения. Благодаря электроприводу , можно легко управлять шторами или занавесками при помощи пульта .
Откройте для себя элегантность и удобство карнизы с электроприводом и дистанционным управлением, которые сделают управление шторами простым и современным.
Одним из главных преимуществ карнизов с электроприводом является их . Эти карнизы идеально подходят для . Также стоит отметить, что эти карнизы дают возможность создавать в доме или офисе.
Монтаж таких карнизов возможна в любом интерьере . Инсталляция не требует специальных знаний , и с этим может справиться практически каждый. Еще одним плюсом является то, что такие карнизы системы «умный дом» .
Несмотря на все достоинства, существуют и несколько ограничений. Например, . оправдывают себя , ведь делают повседневные дела намного легче.
Откройте мир удобства с нашими автоматические рулонные жалюзи заказать +7 (499) 638-25-37, которые обеспечивают идеальное сочетание стиля и функциональности.
Автоматизация управления жалюзи позволяет легко и быстро настраивать их положение.
Удобство и стиль в вашем доме с купить автоматические рулонные шторы прокарниз, которые легко управляются одним нажатием кнопки.
Автоматические рулонные шторы набирают популярность среди современных интерьеров. Такие шторы сочетают в себе элегантность и функциональность.
Одним из главных преимуществ автоматических рулонных штор является возможность дистанционного управления . Настроить освещение в комнате возможно, оставаясь на месте.
Не менее значимым является наличие встроенных датчиков у автоматических рулонных штор. Такие шторы способны адаптироваться к условиям окружающей среды автоматически.
Наконец, стоит упомянуть о том, что автоматические рулонные шторы доступны в различных дизайнах и цветах . Имеется возможность подобрать шторы, соответствующие вашему стилю интерьера.
Обновите интерьер вашего дома с помощью Перетяжка мебели скотчгардом, которая придаст ей свежий и современный вид.
Непосредственно сам процесс перетяжки является третьим шагом.
Портал про все https://version.com.ua новини, технології, здоров'я, будинок, авто, подорожі, фінанси та кар'єра. Щоденні статті, огляди, лайфхаки та інструкції. Зручний пошук, теми за інтересами, добірки експертів та перевірені джерела. Читайте, навчайтеся, заощаджуйте час.
автомобиль chery tiggo chery tiggo 1.6
Журнал для дачников https://www.amandine.ru и цветоводов: что посадить, когда поливать и чем подкармливать. Календарь, таблицы совместимости, защита от вредителей, обрезка и размножение. Планы грядок, тепличные секреты, бюджетные решения и советы профессионалов.
Портал про все https://version.com.ua новини, технології, здоров'я, будинок, авто, подорожі, фінанси та кар'єра. Щоденні статті, огляди, лайфхаки та інструкції. Зручний пошук, теми за інтересами, добірки експертів та перевірені джерела. Читайте, навчайтеся, заощаджуйте час.
chery официальный дилер купить chery pro
Журнал для дачников https://www.amandine.ru и цветоводов: что посадить, когда поливать и чем подкармливать. Календарь, таблицы совместимости, защита от вредителей, обрезка и размножение. Планы грядок, тепличные секреты, бюджетные решения и советы профессионалов.
Купить квартиру https://kvartiracenterspb.ru просто: новостройки и вторичка, студии и семейные планировки. Ипотека от 0,1%, маткапитал, субсидии. Юрпроверка, безопасная сделка, помощь в одобрении, торг с застройщиком. Подбор по району, бюджету и срокам сдачи. Сопровождение до ключей.
Купить квартиру https://novostroydoma.ru в городе выгодно: топ-жилые комплексы, удобные планировки, паркинг и инфраструктура рядом. Ипотека, семейная ипотека 6%, маткапитал. Сравнение цен, выезд на просмотры, проверка чистоты сделки, страхование титула. Экономим время и деньги.
Покупка квартиры https://piterdomovoy.ru «под ключ»: новостройки бизнес/комфорт-класса и надёжная вторичка. Аналитика цен, динамика сдачи, инфраструктура. Ипотека, субсидии, маткапитал. Юридический аудит, безопасные расчёты, регистрация сделки онлайн. Переезд без забот.
Квартира вашей мечты https://kvartiracenter-kypit.ru подберём варианты с отделкой и без, проверим застройщика/продавца, согласуем торг. Ипотека 6–12%, семейные программы, маткапитал. Онлайн-показы, электронная подача в Росреестр, безопасная оплата. Экономим время и бюджет.
Купить квартиру https://kvartiracenterspb.ru просто: новостройки и вторичка, студии и семейные планировки. Ипотека от 0,1%, маткапитал, субсидии. Юрпроверка, безопасная сделка, помощь в одобрении, торг с застройщиком. Подбор по району, бюджету и срокам сдачи. Сопровождение до ключей.
Купить квартиру https://novostroydoma.ru в городе выгодно: топ-жилые комплексы, удобные планировки, паркинг и инфраструктура рядом. Ипотека, семейная ипотека 6%, маткапитал. Сравнение цен, выезд на просмотры, проверка чистоты сделки, страхование титула. Экономим время и деньги.
Покупка квартиры https://piterdomovoy.ru «под ключ»: новостройки бизнес/комфорт-класса и надёжная вторичка. Аналитика цен, динамика сдачи, инфраструктура. Ипотека, субсидии, маткапитал. Юридический аудит, безопасные расчёты, регистрация сделки онлайн. Переезд без забот.
Квартира вашей мечты https://kvartiracenter-kypit.ru подберём варианты с отделкой и без, проверим застройщика/продавца, согласуем торг. Ипотека 6–12%, семейные программы, маткапитал. Онлайн-показы, электронная подача в Росреестр, безопасная оплата. Экономим время и бюджет.
Отличный вариант для компаний, которым важно быстро растаможить груз: таможенный брокер в Москве
"Перетяжка тахты"
Перетяжка позволяет вернуть предметам интерьера первоначальную свежесть.
Такой подход не только экономит бюджет, но и позволяет индивидуализировать интерьер. Вы можете выбрать любой цвет и фактуру ткани под стиль комнаты.
---
### **2. Какие материалы лучше использовать?**
Для перетяжки применяют различные ткани, отличающиеся износостойкостью и внешним видом. Микрофибра и жаккард устойчивы к истиранию и подходят для ежедневного использования.
Также важно учитывать наполнитель, который влияет на комфорт. Латексные наполнители считаются самыми износостойкими и экологичными.
---
### **3. Этапы профессиональной перетяжки**
Процесс начинается с демонтажа старой обивки и оценки состояния каркаса. Мастер удаляет изношенную ткань и проверяет прочность конструкции.
Далее выбирают материал и производят раскрой. Новая ткань кроится точно по размерам мебели, чтобы избежать перекосов.
---
### **4. Преимущества профессионального подхода**
Обращение к специалистам гарантирует качество и долгий срок службы мебели. Опытные ремонтники учитывают все нюансы, чтобы результат радовал годами.
Кроме того, экономится время и исключаются ошибки. Только специалист сможет точно воспроизвести первоначальную форму мебели.
---
### **Спин-шаблон:**
#### **1. Почему стоит выбрать перетяжку мебели?**
- Перетяжка позволяет вернуть предметам интерьера первоначальную свежесть.
- Это отличный способ адаптировать мебель под меняющиеся предпочтения в оформлении дома.
#### **2. Какие материалы лучше использовать?**
- Хлопок и лён подойдут для помещений с невысокой нагрузкой.
- Латексные наполнители считаются самыми износостойкими и экологичными.
#### **3. Этапы профессиональной перетяжки**
- Мастер удаляет изношенную ткань и проверяет прочность конструкции.
- Раскрой выполняется с запасом для удобства последующего натяжения.
#### **4. Преимущества профессионального подхода**
- Мастера подбирают оптимальные методы перетяжки для разных типов мебели.
- Только специалист сможет точно воспроизвести первоначальную форму мебели.
Operation Game Canada: A classic, fun-filled board game where players test their precision by removing ailments from the patient without triggering the buzzer: play Operation game for free
Подарите своей любимой мебели новую жизнь, заказав профессиональную реставрация мебели борисов в Минске!
Это более выгодно с финансовой точки зрения и дает возможность сохранить привычные и дорогие сердцу предметы обстановки
**Выбор ткани: на что обратить внимание?**
У каждого материала есть свои плюсы и минусы.
**Этапы перетяжки мебели: от замера до готового результата**
Если необходимо, наполнитель заменяется, и осуществляется раскрой новой ткани.
**Уход за перетянутой мебелью: продлеваем срок службы**
Грамотный уход за перетянутой мебелью способствует продлению срока ее службы.
віктор значення імені
How to win in Calgary Lottery: Boost your chances by playing consistently, joining lottery pools, and choosing less popular combinations. Remember, winning requires luck and responsible play: local Calgary deals and wins
Operation Game Canada: A classic, fun-filled board game where players test their precision by removing ailments from the patient without triggering the buzzer: Operation game for kids Canada
https://mosquitosalsa.com/
TopTool https://www.toptool.app/en is a global multilingual tools directory that helps you discover the best products from around the world. Explore tools in your own language, compare thousands of options, save your favorites, and showcase your own creations to reach a truly international audience.
TopTool https://www.toptool.app/en is a global multilingual tools directory that helps you discover the best products from around the world. Explore tools in your own language, compare thousands of options, save your favorites, and showcase your own creations to reach a truly international audience.
Таможенный брокер справился даже с нестандартной поставкой. Всё согласовали заранее, никаких сюрпризов. Уровень сервиса впечатляет - Таможенный брокер в Домодедово
Входная дверь - это первый рубеж безопасности вашего жилища. Металлические входные двери сочетают в себе максимальную защиту от взлома, долговечность и современный дизайн, создавая надежный барьер между вашим домом и внешним миром: https://www.dveri-v-srok.ru/dveri-dlja-kvartiry/
Plateforme parifoot rdc : pronos fiables, comparateur de cotes multi-books, tendances du marche, cash-out, statistiques avancees. Depots via M-Pesa/Airtel Money, support francophone, retraits securises. Pariez avec moderation.
Paris sportifs avec 1xbet cd apk : pre-match & live, statistiques, cash-out, builder de paris. Bonus d’inscription, programme fidelite, appli mobile. Depots via M-Pesa/Airtel Money. Informez-vous sur la reglementation. 18+, jouez avec moderation.
нарколог на дом санкт-петербург
https://shkola-vocala.ru/shkola-igry-na-gitare.php
Paris sportifs avec 1xbet apk rdc : pre-match & live, statistiques, cash-out, builder de paris. Bonus d’inscription, programme fidelite, appli mobile. Depots via M-Pesa/Airtel Money. Informez-vous sur la reglementation. 18+, jouez avec moderation.
Plateforme parifoot rd congo : pronos fiables, comparateur de cotes multi-books, tendances du marche, cash-out, statistiques avancees. Depots via M-Pesa/Airtel Money, support francophone, retraits securises. Pariez avec moderation.
Топовое тату оборудование. Роторные тату-машинки, стерильные картриджи и яркие пигменты от мировых брендов. Только профессиональный инструмент для безупречного качества тату. Заходите https://tattooaura.ru/
Plateforme parifoot rdc : pronos fiables, comparateur de cotes multi-books, tendances du marche, cash-out, statistiques avancees. Depots via M-Pesa/Airtel Money, support francophone, retraits securises. Pariez avec moderation.
Paris sportifs avec 1xbet congo : pre-match & live, statistiques, cash-out, builder de paris. Bonus d’inscription, programme fidelite, appli mobile. Depots via M-Pesa/Airtel Money. Informez-vous sur la reglementation. 18+, jouez avec moderation.
Plateforme parifoot rdc : pronos fiables, comparateur de cotes multi-books, tendances du marche, cash-out, statistiques avancees. Depots via M-Pesa/Airtel Money, support francophone, retraits securises. Pariez avec moderation.
Paris sportifs avec 1xbet cd apk : pre-match & live, statistiques, cash-out, builder de paris. Bonus d’inscription, programme fidelite, appli mobile. Depots via M-Pesa/Airtel Money. Informez-vous sur la reglementation. 18+, jouez avec moderation.
Кулінарний портал https://infostat.com.ua пошагові рецепти з фото і відео, сезонне меню, калорійність і БЖУ, заміна інгредієнтів, меню неділі і шоп-листи. Кухні світу, домашня випічка, соуси, заготовки. Умные фильтры по времени, бюджету и уровню — готовьте смачно і без стресу.
Сайт про все https://gazette.com.ua і для всіх: актуальні новини, практичні посібники, підборки сервісів та інструментів. Огляди техніки, рецепти, здоров'я і фінанси. Удобні теги, закладки, коментарі та регулярні оновлення контенту.
Портал про все https://ukrnova.com новини, технології, здоров'я, будинок, авто, гроші та подорожі. Короткі гайди, чек-листи, огляди та лайфхаки. Розумний пошук, підписки за темами, обране та коментарі. Тільки перевірена та корисна інформація щодня.
Кулінарний портал https://infostat.com.ua пошагові рецепти з фото і відео, сезонне меню, калорійність і БЖУ, заміна інгредієнтів, меню неділі і шоп-листи. Кухні світу, домашня випічка, соуси, заготовки. Умные фильтры по времени, бюджету и уровню — готовьте смачно і без стресу.
Портал про все https://ukrnova.com новини, технології, здоров'я, будинок, авто, гроші та подорожі. Короткі гайди, чек-листи, огляди та лайфхаки. Розумний пошук, підписки за темами, обране та коментарі. Тільки перевірена та корисна інформація щодня.
Сайт про все https://gazette.com.ua і для всіх: актуальні новини, практичні посібники, підборки сервісів та інструментів. Огляди техніки, рецепти, здоров'я і фінанси. Удобні теги, закладки, коментарі та регулярні оновлення контенту.
новини Дніпра
массаж тела
Сайт про все https://kraina.one практичні поради, таблиці та калькулятори, добірки сервісів. Теми – здоров'я, сім'я, фінанси, авто, гаджети, подорожі. Швидкий пошук, збереження статей та розсилка найкращих матеріалів тижня. Простою мовою та у справі.
Єдиний портал знань https://uaeu.top наука та техніка, стиль життя, будинок та сад, спорт, освіта. Гайди, шпаргалки, покрокові плани, експерти відповіді. Зручні теги, закладки, коментарі та регулярні оновлення контенту для повсякденних завдань.
Інформаційний портал https://presa.com.ua новини, технології, здоров'я, фінанси, будинок, авто та подорожі. Короткі гайди, огляди, чек-листи та інструкції. Розумний пошук, підписки на теми, закладки та коментарі. Тільки перевірені джерела та щоденні оновлення.
Сайт про все https://kraina.one практичні поради, таблиці та калькулятори, добірки сервісів. Теми – здоров'я, сім'я, фінанси, авто, гаджети, подорожі. Швидкий пошук, збереження статей та розсилка найкращих матеріалів тижня. Простою мовою та у справі.
Інформаційний портал https://presa.com.ua новини, технології, здоров'я, фінанси, будинок, авто та подорожі. Короткі гайди, огляди, чек-листи та інструкції. Розумний пошук, підписки на теми, закладки та коментарі. Тільки перевірені джерела та щоденні оновлення.
Єдиний портал знань https://uaeu.top наука та техніка, стиль життя, будинок та сад, спорт, освіта. Гайди, шпаргалки, покрокові плани, експерти відповіді. Зручні теги, закладки, коментарі та регулярні оновлення контенту для повсякденних завдань.
Портал корисної інформації https://online-porada.com практичні поради, відповіді експертів, таблиці та шпаргалки. Теми – здоров'я, сім'я, гроші, гаджети, авто та туризм. Швидкий пошук, обране, розсилка найкращих матеріалів тижня. Пишемо просто й у справі.
Сучасний інформаційний https://prezza.com.ua портал: новини, огляди, практичні інструкції. Фінанси, гаджети, авто, їжа, спорт, саморозвиток. Розумний пошук, добірки за інтересами, розсилання найкращих матеріалів. Тільки перевірені джерела та щоденні оновлення.
Інформаційний портал https://revolta.com.ua «все в одному»: коротко і у справі про тренди, товари та сервіси. Огляди, інструкції, чек-листи, тести. Тематичні підписки, розумні фільтри, закладки та коментарі. Допомагаємо економити час та приймати рішення.
Портал корисної інформації https://online-porada.com практичні поради, відповіді експертів, таблиці та шпаргалки. Теми – здоров'я, сім'я, гроші, гаджети, авто та туризм. Швидкий пошук, обране, розсилка найкращих матеріалів тижня. Пишемо просто й у справі.
Сучасний інформаційний https://prezza.com.ua портал: новини, огляди, практичні інструкції. Фінанси, гаджети, авто, їжа, спорт, саморозвиток. Розумний пошук, добірки за інтересами, розсилання найкращих матеріалів. Тільки перевірені джерела та щоденні оновлення.
Інформаційний портал https://revolta.com.ua «все в одному»: коротко і у справі про тренди, товари та сервіси. Огляди, інструкції, чек-листи, тести. Тематичні підписки, розумні фільтри, закладки та коментарі. Допомагаємо економити час та приймати рішення.
На сайте собраны обзоры игровых компьютеров, где подробно рассказывается о совместимости комплектующих, подборе оптимальных конфигураций и систем охлаждения. Материалы помогают пользователям ориентироваться в разнообразии моделей и выбрать подходящую сборку для своих игровых целей.
TopTool https://www.toptool.app/en is a global multilingual tools directory that helps you discover the best products from around the world. Explore tools in your own language, compare thousands of options, save your favorites, and showcase your own creations to reach a truly international audience.
Бизнес-идеи https://idealistworld.com для старта и роста: от микропроектов до стартапов. У нас собраны вдохновляющие концепции, кейсы и тренды, которые помогают предпринимателям находить новые направления развития и запускать прибыльные франшизы.
На сайте game-computers.ru собраны обзоры актуальных игровых сборок, с подробными характеристиками комплектующих и рекомендациями по их совместимости. Блог помогает выбрать оптимальные конфигурации, дает советы по апгрейду и настройке системы для комфортного гейминга.
TopTool https://www.toptool.app/en is a global multilingual tools directory that helps you discover the best products from around the world. Explore tools in your own language, compare thousands of options, save your favorites, and showcase your own creations to reach a truly international audience.
ООО "КОМТЕК" продукция https://www.komtek-spb.ru Pro-face в России официальная дистрибуция и сервисная поддержка. Поставка HMI-панелей, дисплеев и промышленных решений. Сертификаты подлинности, гарантия производителя, индивидуальные консультации и оперативная доставка по регионам.
https://медоптима.рф/
Социальная сеть https://itsnew.ru для тех, кто делает сайты и продвигает их в интернете. Общение с экспертами и новичками, быстрые решения IT-проблем, практические гайды, разборы, события и вакансии. Растите в веб-разработке и SEO каждый день.
Профессиональная уничтожение муравьев обязательна.
обработка офиса от тараканов
https://nicemerch.ru/
Щоденний дайджест https://dailyfacts.com.ua головні новини, тренди, думки експертів та добірки посилань. Теми – економіка, наука, спорт, культура. Розумна стрічка, закладки, сповіщення. Читайте 5 хвилин – будьте в курсі всього важливого.
Практичний портал https://infokom.org.ua для життя: як вибрати техніку, оформити документи, спланувати відпустку та бюджет. Чек-листи, шаблони, порівняння тарифів та сервісів. Зрозумілі інструкції, актуальні ціни та поради від фахівців.
Регіональний інфопортал https://expertka.com.ua новини міста, транспорт, ЖКГ, медицина, афіша та вакансії. Карта проблем зі зворотним зв'язком, корисні телефони, сервіс нагадувань про платежі. Все важливе – поряд із будинком.
Щоденний дайджест https://dailyfacts.com.ua головні новини, тренди, думки експертів та добірки посилань. Теми – економіка, наука, спорт, культура. Розумна стрічка, закладки, сповіщення. Читайте 5 хвилин – будьте в курсі всього важливого.
Практичний портал https://infokom.org.ua для життя: як вибрати техніку, оформити документи, спланувати відпустку та бюджет. Чек-листи, шаблони, порівняння тарифів та сервісів. Зрозумілі інструкції, актуальні ціни та поради від фахівців.
Регіональний інфопортал https://expertka.com.ua новини міста, транспорт, ЖКГ, медицина, афіша та вакансії. Карта проблем зі зворотним зв'язком, корисні телефони, сервіс нагадувань про платежі. Все важливе – поряд із будинком.
Beneficios de glucosamina en articulaciones con HondroLife.
¡Pruébalo!
Практичний довідник https://altavista.org.ua здоров'я, будинок, авто, навчання, кар'єра. Таблиці, інструкції, рейтинги послуг, порівняння цін. Офлайн доступ і друк шпаргалок. Економимо ваш час.
Універсальний інфопортал https://dobraporada.com.ua "на кожен день": короткі інструкції, таблиці, калькулятори, порівняння. Теми – сім'я, фінанси, авто, освіта, кулінарія, спорт. Персональна стрічка, добірки тижня, коментарі та обране.
Інфопортал про головне https://ukrpublic.com економіка, технологія, здоров'я, екологія, авто, подорожі. Короткі статті, відео пояснення, корисні посилання. Персональні рекоме
Практичний довідник https://altavista.org.ua здоров'я, будинок, авто, навчання, кар'єра. Таблиці, інструкції, рейтинги послуг, порівняння цін. Офлайн доступ і друк шпаргалок. Економимо ваш час.
Універсальний інфопортал https://dobraporada.com.ua "на кожен день": короткі інструкції, таблиці, калькулятори, порівняння. Теми – сім'я, фінанси, авто, освіта, кулінарія, спорт. Персональна стрічка, добірки тижня, коментарі та обране.
Інфопортал про головне https://ukrpublic.com економіка, технологія, здоров'я, екологія, авто, подорожі. Короткі статті, відео пояснення, корисні посилання. Персональні рекоме
meilleur casino en ligne: telecharger 1xbet pour android
meilleur casino en ligne: try this
Портал-довідник https://speedinfo.com.ua таблиці норм та термінів, інструкції «як зробити», гайди з сервісів. Будинок та сад, діти, навчання, кар'єра, фінанси. Розумні фільтри, друк шпаргалок, збереження статей. Чітко, структурно, зрозуміло.
Інформаційний медіацентр https://suntimes.com.ua новини, лонгріди, огляди та FAQ. Наука, культура, спорт, технології, стиль життя. Редакторські добірки, коментарі, повідомлення про важливе. Все в одному місці та у зручному форматі.
Інформаційний сайт https://infoteka.com.ua новини, практичні гайди, огляди та чек-листи. Технології, здоров'я, фінанси, будинок, подорожі. Розумний пошук, закладки, підписки на теми. Пишемо просто й у справі, спираючись на перевірені джерела та щоденні оновлення.
Портал-довідник https://speedinfo.com.ua таблиці норм та термінів, інструкції «як зробити», гайди з сервісів. Будинок та сад, діти, навчання, кар'єра, фінанси. Розумні фільтри, друк шпаргалок, збереження статей. Чітко, структурно, зрозуміло.
Інформаційний медіацентр https://suntimes.com.ua новини, лонгріди, огляди та FAQ. Наука, культура, спорт, технології, стиль життя. Редакторські добірки, коментарі, повідомлення про важливе. Все в одному місці та у зручному форматі.
Інформаційний сайт https://infoteka.com.ua новини, практичні гайди, огляди та чек-листи. Технології, здоров'я, фінанси, будинок, подорожі. Розумний пошук, закладки, підписки на теми. Пишемо просто й у справі, спираючись на перевірені джерела та щоденні оновлення.
Портал корисної інформації https://inquire.com.ua практичні поради, відповіді експертів, таблиці та шпаргалки. Теми – здоров'я, сім'я, гроші, гаджети, авто, туризм. Швидкий пошук, обране, розсилка найкращих матеріалів тижня.
Сучасний інфосайт https://overview.com.ua наука та техніка, стиль життя, спорт, освіта, їжа та DIY. Зрозумілі пояснення, покрокові плани, тести та огляди. Розумні фільтри за інтересами, коментарі, закладки та офлайн-читання – все, щоб заощаджувати час.
Онлайн-журнал https://elementarno.com.ua про все: новини та тенденції, lifestyle та технології, культура та подорожі, гроші та кар'єра, здоров'я та будинок. Щоденні статті, огляди, інтерв'ю та практичні поради без води. Читайте перевірені матеріали, підписуйтесь на дайджест та будьте в темі.
Універсальний онлайн-журнал https://ukrglobe.com про все – від науки та гаджетів до кіно, психології, подорожей та особистих фінансів. Розумні тексти, короткі гіди, добірки та думки експертів. Актуально щодня, зручно на будь-якому пристрої. Читайте, зберігайте, діліться.
Сучасний інфосайт https://overview.com.ua наука та техніка, стиль життя, спорт, освіта, їжа та DIY. Зрозумілі пояснення, покрокові плани, тести та огляди. Розумні фільтри за інтересами, коментарі, закладки та офлайн-читання – все, щоб заощаджувати час.
Онлайн-журнал https://elementarno.com.ua про все: новини та тенденції, lifestyle та технології, культура та подорожі, гроші та кар'єра, здоров'я та будинок. Щоденні статті, огляди, інтерв'ю та практичні поради без води. Читайте перевірені матеріали, підписуйтесь на дайджест та будьте в темі.
Універсальний онлайн-журнал https://ukrglobe.com про все – від науки та гаджетів до кіно, психології, подорожей та особистих фінансів. Розумні тексти, короткі гіди, добірки та думки експертів. Актуально щодня, зручно на будь-якому пристрої. Читайте, зберігайте, діліться.
Портал корисної інформації https://inquire.com.ua практичні поради, відповіді експертів, таблиці та шпаргалки. Теми – здоров'я, сім'я, гроші, гаджети, авто, туризм. Швидкий пошук, обране, розсилка найкращих матеріалів тижня.
Про все в одному місці https://irinin.com свіжі новини, корисні інструкції, огляди сервісів і товарів, що надихають історії, ідеї для відпочинку та роботи. Онлайн-журнал із фактчекінгом, зручною навігацією та персональними рекомендаціями. Дізнайтесь головне і знаходите нове.
Онлайн-журнал https://ukr-weekend.com про все для цікавих: технології, наука, стиль життя, культура, їжа, спорт, подорожі та кар'єра. Розбори без кліше, лаконічні шпаргалки, інтерв'ю та добірки. Оновлення щоденно, легке читання та збереження в закладки.
Ваш онлайн-журнал https://informa.com.ua про все: великі теми та короткі формати – від трендів та новин до лайфхаків та практичних порад. Рубрики за інтересами, огляди, інтерв'ю та думки. Читайте достовірно, розширюйте світогляд, залишайтеся на крок попереду.
Онлайн-журнал https://worldwide-ua.com про все: новини, тренди, лайфхаки, наука, технології, культура, їжа, подорожі та гроші. Короткі шпаргалки та великі розбори без клікбейту. Фактчекінг, зручна навігація, закладки та розумні рекомендації. Читайте щодня і залишайтеся у темі.
Про все в одному місці https://irinin.com свіжі новини, корисні інструкції, огляди сервісів і товарів, що надихають історії, ідеї для відпочинку та роботи. Онлайн-журнал із фактчекінгом, зручною навігацією та персональними рекомендаціями. Дізнайтесь головне і знаходите нове.
Ваш онлайн-журнал https://informa.com.ua про все: великі теми та короткі формати – від трендів та новин до лайфхаків та практичних порад. Рубрики за інтересами, огляди, інтерв'ю та думки. Читайте достовірно, розширюйте світогляд, залишайтеся на крок попереду.
Онлайн-журнал https://ukr-weekend.com про все для цікавих: технології, наука, стиль життя, культура, їжа, спорт, подорожі та кар'єра. Розбори без кліше, лаконічні шпаргалки, інтерв'ю та добірки. Оновлення щоденно, легке читання та збереження в закладки.
Онлайн-журнал https://worldwide-ua.com про все: новини, тренди, лайфхаки, наука, технології, культура, їжа, подорожі та гроші. Короткі шпаргалки та великі розбори без клікбейту. Фактчекінг, зручна навігація, закладки та розумні рекомендації. Читайте щодня і залишайтеся у темі.
https://internet-leman.ru/
Entdecken Sie die besten Weinverkostungen in Wien auf weinprobe wien.
In der Stadt finden sich zahlreiche Weinguter, die eine lange Geschichte haben.
Die Weinverkostungen in Wien sind perfekt fur Kenner und Neulinge. Dabei lernen Gaste die Besonderheiten der regionalen Rebsorten kennen.
#### **2. Die besten Orte fur Weinverkostungen**
In Wien gibt es zahlreiche Lokale und Weinguter, die Verkostungen anbieten. Auch moderne Weinkeller in der Innenstadt bieten exklusive Erlebnisse.
Einige Winzer veranstalten Fuhrungen durch ihre Kellereien. Oft werden auch seltene Weine vorgestellt, die nur lokal erhaltlich sind.
#### **3. Wiener Weinsorten und ihre Besonderheiten**
Wiener Weine sind vor allem fur ihre Vielfalt bekannt. Der beliebte Gemischte Satz ist eine lokale Spezialitat, die aus mehreren Traubensorten besteht.
Die Bodenbeschaffenheit und das Klima pragen den Geschmack. Die mineralischen Noten der Wiener Weine sind besonders ausgepragt.
#### **4. Tipps fur eine gelungene Weinverkostung**
Eine gute Vorbereitung macht die Verkostung noch angenehmer. Es empfiehlt sich, langsam zu trinken, um die Nuancen zu schmecken.
Gruppenverkostungen bringen zusatzlichen Spa?. Viele Veranstalter bieten thematische Verkostungen an.
---
### **Spin-Template fur den Artikel**
#### **1. Einfuhrung in die Weinverkostung in Wien**
Die Weinverkostungen in Wien sind perfekt fur Kenner und Neulinge.
#### **2. Die besten Orte fur Weinverkostungen**
Einige Winzer veranstalten Fuhrungen durch ihre Kellereien.
#### **3. Wiener Weinsorten und ihre Besonderheiten**
Auch der fruchtige Grune Veltliner zahlt zu den bekanntesten Wei?weinen der Region.
#### **4. Tipps fur eine gelungene Weinverkostung**
Gruppenverkostungen bringen zusatzlichen Spa?.
Ваш онлайн-журнал https://informative.com.ua про все: новини, розбори, інтерв'ю та свіжі ідеї. Теми — від психології та освіти до спорту та культури. Зберігайте в закладки, ділитесь з друзями, випускайте повідомлення про головне. Чесний тон, зрозумілі формати, щоденні поновлення.
Онлайн-журнал 24/7 https://infoquorum.com.ua все про життя та світ — від технологій та науки до кулінарії, подорожей та особистих фінансів. Короткі нотатки та глибока аналітика, рейтинги та добірки, корисні інструменти. Зручна мобільна версія та розумні підказки для економії часу.
Щоденний онлайн-журнал https://republish.online про все: від швидкого «що сталося» до глибоких лонґрідів. Пояснюємо контекст, даємо посилання на джерела, ділимося лайфхаками та історіями, що надихають. Без клікбейту – лише корисні матеріали у зручному форматі.
Онлайн-журнал https://mediaworld.com.ua про бізнес, технології, маркетинг і стиль життя. Щодня — свіжі новини, аналітика, огляди, інтерв'ю та практичні гайди. Зручна навігація, чесні думки, експертні шпальти. Читайте, надихайтеся, діліться безкоштовно.
Онлайн-журнал 24/7 https://infoquorum.com.ua все про життя та світ — від технологій та науки до кулінарії, подорожей та особистих фінансів. Короткі нотатки та глибока аналітика, рейтинги та добірки, корисні інструменти. Зручна мобільна версія та розумні підказки для економії часу.
Ваш онлайн-журнал https://informative.com.ua про все: новини, розбори, інтерв'ю та свіжі ідеї. Теми — від психології та освіти до спорту та культури. Зберігайте в закладки, ділитесь з друзями, випускайте повідомлення про головне. Чесний тон, зрозумілі формати, щоденні поновлення.
Щоденний онлайн-журнал https://republish.online про все: від швидкого «що сталося» до глибоких лонґрідів. Пояснюємо контекст, даємо посилання на джерела, ділимося лайфхаками та історіями, що надихають. Без клікбейту – лише корисні матеріали у зручному форматі.
Онлайн-журнал https://mediaworld.com.ua про бізнес, технології, маркетинг і стиль життя. Щодня — свіжі новини, аналітика, огляди, інтерв'ю та практичні гайди. Зручна навігація, чесні думки, експертні шпальти. Читайте, надихайтеся, діліться безкоштовно.
Домашній онлайн-журнал https://zastava.com.ua про життя всередині чотирьох стін: швидкі страви, прибирання за планом, розумні покупки, декор своїми руками, зони зберігання, дитячий куточок та догляд за вихованцями. Практика замість теорії, зрозумілі чек-листи та поради, які економлять час та гроші.
Готуємо, прибираємо https://ukrdigest.com прикрашаємо легко. Домашній онлайн-журнал з покроковими рецептами, лайфхаками з прання та прибирання, ідеями сезонного декору, планами меню та бюджетом сім'ї. Зберігайте статті, складайте списки справ та знаходите відповіді на побутові питання.
Ваш помічник https://dailymail.com.ua по дому: інтер'єр та ремонт, організація простору, здоровий побут, догляд за технікою, рецепти та заготівлі, ідеї для вихідних. Тільки практичні поради, перевірені матеріали та зручна навігація. Зробіть будинок красивим та зручним без зайвих витрат.
Все про будинки https://vechorka.com.ua де приємно жити: швидкі рецепти, компактне зберігання, текстиль та кольори, сезонний декор, догляд за речами та технікою, дозвілля з дітьми. Покрокові інструкції, корисні вибірки, особистий досвід. Затишок починається тут - щодня.
Готуємо, прибираємо https://ukrdigest.com прикрашаємо легко. Домашній онлайн-журнал з покроковими рецептами, лайфхаками з прання та прибирання, ідеями сезонного декору, планами меню та бюджетом сім'ї. Зберігайте статті, складайте списки справ та знаходите відповіді на побутові питання.
Домашній онлайн-журнал https://zastava.com.ua про життя всередині чотирьох стін: швидкі страви, прибирання за планом, розумні покупки, декор своїми руками, зони зберігання, дитячий куточок та догляд за вихованцями. Практика замість теорії, зрозумілі чек-листи та поради, які економлять час та гроші.
Ваш помічник https://dailymail.com.ua по дому: інтер'єр та ремонт, організація простору, здоровий побут, догляд за технікою, рецепти та заготівлі, ідеї для вихідних. Тільки практичні поради, перевірені матеріали та зручна навігація. Зробіть будинок красивим та зручним без зайвих витрат.
Все про будинки https://vechorka.com.ua де приємно жити: швидкі рецепти, компактне зберігання, текстиль та кольори, сезонний декор, догляд за речами та технікою, дозвілля з дітьми. Покрокові інструкції, корисні вибірки, особистий досвід. Затишок починається тут - щодня.
Ваш провідник https://ukrchannel.com до порядку та затишку: розхламлення, зонування, бюджетний ремонт, кухонні лайфхаки, зелені рослини, здоров'я будинку. Тільки перевірені поради, списки справ та натхнення. Створіть простір, який підтримує вас.
Домашній онлайн-журнал https://ukrcentral.com про розумний побут: планування харчування, прибирання за таймером, екоради, мінімалізм без стресу, ідеї для малого метражу. Завантажені чек-листи, таблиці та гайди. Заощаджуйте час, гроші та сили — із задоволенням.
Журнал для домашнього https://magazine.com.ua життя без метушні: плани прибирання, меню, дитячий куточок, вихованці, міні-сад, дрібний ремонт, побутова безпека. Короткі інструкції, корисні списки та приклади, що надихають. Зробіть будинок опорою для всієї родини.
Практичний домашній https://publish.com.ua онлайн-журнал: планинг тижня, закупівлі без зайвого, рецепти з доступних продуктів, догляд за поверхнями, сезонні проекти. Тільки у справі, без клікбейту. Зручна навігація та матеріали, до яких хочеться повертатися.
Домашній онлайн-журнал https://ukrcentral.com про розумний побут: планування харчування, прибирання за таймером, екоради, мінімалізм без стресу, ідеї для малого метражу. Завантажені чек-листи, таблиці та гайди. Заощаджуйте час, гроші та сили — із задоволенням.
Журнал для домашнього https://magazine.com.ua життя без метушні: плани прибирання, меню, дитячий куточок, вихованці, міні-сад, дрібний ремонт, побутова безпека. Короткі інструкції, корисні списки та приклади, що надихають. Зробіть будинок опорою для всієї родини.
Ваш провідник https://ukrchannel.com до порядку та затишку: розхламлення, зонування, бюджетний ремонт, кухонні лайфхаки, зелені рослини, здоров'я будинку. Тільки перевірені поради, списки справ та натхнення. Створіть простір, який підтримує вас.
Практичний домашній https://publish.com.ua онлайн-журнал: планинг тижня, закупівлі без зайвого, рецепти з доступних продуктів, догляд за поверхнями, сезонні проекти. Тільки у справі, без клікбейту. Зручна навігація та матеріали, до яких хочеться повертатися.
Затишок щодня https://narodna.com.ua ідеї для інтер'єру, зберігання в малих просторах, безпечний побут із дітьми, зелені рішення, догляд за технікою, корисні звички. Інструкції, схеми та списки. Перетворіть будинок на місце сили та спокою.
Медіа для дому https://government.com.ua та офісу: інтер'єр та побут, сімейні питання, цифрові тренди, підприємництво, інвестиції, здоров'я та освіта. Збірники порад, випробування, аналітика, топ-листи. Лише перевірена інформація.
Все, що важливо https://ua-meta.com сьогодні: будинок та сім'я, кар'єра та бізнес, технології та інтернет, дозвілля та спорт, здоров'я та харчування. Новини, лонгріди, посібники, добірки сервісів та додатків. Читайте, вибирайте, застосовуйте на практиці.
Універсальний гід https://dailyday.com.ua по життю: затишний будинок, щасливі стосунки, продуктивна робота, цифрові інструменти, фінансова грамотність, саморозвиток та відпочинок. Короткі формати та глибокі розбори – для рішень без метушні.
Медіа для дому https://government.com.ua та офісу: інтер'єр та побут, сімейні питання, цифрові тренди, підприємництво, інвестиції, здоров'я та освіта. Збірники порад, випробування, аналітика, топ-листи. Лише перевірена інформація.
Все, що важливо https://ua-meta.com сьогодні: будинок та сім'я, кар'єра та бізнес, технології та інтернет, дозвілля та спорт, здоров'я та харчування. Новини, лонгріди, посібники, добірки сервісів та додатків. Читайте, вибирайте, застосовуйте на практиці.
Затишок щодня https://narodna.com.ua ідеї для інтер'єру, зберігання в малих просторах, безпечний побут із дітьми, зелені рішення, догляд за технікою, корисні звички. Інструкції, схеми та списки. Перетворіть будинок на місце сили та спокою.
Універсальний гід https://dailyday.com.ua по життю: затишний будинок, щасливі стосунки, продуктивна робота, цифрові інструменти, фінансова грамотність, саморозвиток та відпочинок. Короткі формати та глибокі розбори – для рішень без метушні.
Pinco casino bonusları mükəmməldir. Hər oyunda şansını yoxla — pinko kazino. Pinco betdə yeni promosiyalar var.
Pinco oyunçular üçün yardım mövcuddur.
Сучасне медіа https://homepage.com.ua «про все важливе»: від ремонту та рецептів до стартапів та кібербезпеки. Сім'я, будинок, технології, гроші, робота, здоров'я, культура. Зрозуміла мова, наочні схеми, регулярні поновлення.
Баланс будинку https://press-express.com.ua та кар'єри: управління часом, побутові лайфхаки, цифрові рішення, особисті фінанси, батьки та діти, спорт та харчування. Огляди, інструкції, думки спеціалістів. Матеріали, до яких повертаються.
Щоденний журнал https://massmedia.one про життя без перевантаження: будинок та побут, сім'я та стосунки, ІТ та гаджети, бізнес та робота, фінанси, настрій та відпочинок. Концентрат корисного: короткі висновки, посилання джерела, інструменти для действий.
Платформа ідей https://infopark.com.ua для дому, роботи та відпочинку: ремонт, відносини, софт та гаджети, маркетинг та інвестиції, рецепти та спорт. Матеріали з висновками та готовими списками справ.
Баланс будинку https://press-express.com.ua та кар'єри: управління часом, побутові лайфхаки, цифрові рішення, особисті фінанси, батьки та діти, спорт та харчування. Огляди, інструкції, думки спеціалістів. Матеріали, до яких повертаються.
Сучасне медіа https://homepage.com.ua «про все важливе»: від ремонту та рецептів до стартапів та кібербезпеки. Сім'я, будинок, технології, гроші, робота, здоров'я, культура. Зрозуміла мова, наочні схеми, регулярні поновлення.
Щоденний журнал https://massmedia.one про життя без перевантаження: будинок та побут, сім'я та стосунки, ІТ та гаджети, бізнес та робота, фінанси, настрій та відпочинок. Концентрат корисного: короткі висновки, посилання джерела, інструменти для действий.
Платформа ідей https://infopark.com.ua для дому, роботи та відпочинку: ремонт, відносини, софт та гаджети, маркетинг та інвестиції, рецепти та спорт. Матеріали з висновками та готовими списками справ.
Журнал про баланс https://info365.com.ua затишок та порядок, сім'я та дозвілля, технології та безпека, кар'єра та інвестиції. Огляди, порівняння, добірки товарів та додатків.
Життя у ритмі цифри https://vilnapresa.com розумний будинок, мобільні сервіси, кібербезпека, віддалена робота, сімейний календар, здоров'я. Гайди, чек-листи, добірки додатків.
Про будинок та світ https://databank.com.ua навколо: затишок, сім'я, освіта, бізнес-інструменти, особисті фінанси, подорожі та кулінарія. Стислі висновки, посилання на джерела, корисні формули.
Життя простіше https://metasearch.com.ua організація побуту, виховання, продуктивність, smart-рішення, особисті фінанси, спорт та відпочинок. Перевірені поради, наочні схеми, корисні таблиці.
Про будинок та світ https://databank.com.ua навколо: затишок, сім'я, освіта, бізнес-інструменти, особисті фінанси, подорожі та кулінарія. Стислі висновки, посилання на джерела, корисні формули.
Життя у ритмі цифри https://vilnapresa.com розумний будинок, мобільні сервіси, кібербезпека, віддалена робота, сімейний календар, здоров'я. Гайди, чек-листи, добірки додатків.
Журнал про баланс https://info365.com.ua затишок та порядок, сім'я та дозвілля, технології та безпека, кар'єра та інвестиції. Огляди, порівняння, добірки товарів та додатків.
Життя простіше https://metasearch.com.ua організація побуту, виховання, продуктивність, smart-рішення, особисті фінанси, спорт та відпочинок. Перевірені поради, наочні схеми, корисні таблиці.
Хотите взять займ https://zaimy-57.ru быстро и безопасно? Сравните предложения МФО, выберите сумму и срок, оформите заявку онлайн и получите деньги на карту. Прозрачные условия, моментальное решение, поддержка 24/7.
Взять займ онлайн https://zaimy-59.ru за несколько минут: без визита в офис, без лишних справок. Подбор выгодных ставок, проверенные кредиторы, мгновенное зачисление на карту. Удобно и прозрачно.
Как взять займ https://zaimy-61.ru без лишних переплат: сравните ставки, выберите подходящий вариант и отправьте онлайн-заявку. Только проверенные кредиторы, прозрачные комиссии, безопасная обработка данных.
Pinco oyunlarında hər kəs öz oyununu tapar. Mərclər üçün rəsmi səhifə pinco azerbaycan. Pinco oyunçular üçün əla seçimdir.
Pinco az yeni domen aktiv işləyir.
Взять займ онлайн https://zaimy-63.ru за 5–10 минут: выберите сумму и срок, заполните короткую анкету и получите перевод на карту. Прозрачные ставки, без скрытых комиссий, круглосуточная обработка, только проверенные МФО.
Нужно взять займ https://zaimy-69.ru без визита в офис? Сервис подбора предложений: мгновенное решение, гибкие лимиты, понятные условия, поддержка 24/7. Деньги на карту сразу после одобрения.
Взять займ https://zaimy-71.ru до зарплаты и на любые цели. Подбор по сумме, сроку и ставке, калькулятор платежа, проверенные кредиторы. Оформление 24/7, решение за несколько минут.
Берите займ онлайн https://zaimy-73.ru без очередей: моментальная проверка, прозрачные тарифы, уведомления о платеже и удобное продление. Деньги поступают на карту сразу после одобрения.
Онлайн-займ https://zaimy-76.ru для срочных расходов: гибкие лимиты, прозрачные комиссии, понятный график. Подберите лучший вариант и оформите заявку — деньги придут на карту 24/7.
Возьмите займ https://zaimy-78.ru онлайн на карту: фиксированные условия, калькулятор переплаты, поддержка в чате. Оформление круглосуточно, решение — за минуты, без скрытых платежей.
Займ на карту https://zaimy-80.ru без лишних вопросов: короткая анкета, автоматическое решение, прозрачные комиссии. Удобное продление и напоминания о платежах в личном кабинете.
Взять займ https://zaimy-86.ru стало проще: мобильная заявка, подтверждение за минуты, прозрачные тарифы и удобное погашение. Работает 24/7, только проверенные кредиторы.
Где взять займ https://zaimy-89.ru выгодно? Наш сервис подбирает предложения по сумме, сроку и ставке. Полная стоимость заранее, без скрытых платежей. Оформите онлайн и получите деньги за минуты.
Срочно на карту https://zaimy-87.ru возьмите займ без визита в офис. Короткая анкета, мгновенное решение, честные условия, напоминания о платежах. Работает круглосуточно.
Хочешь халяву? https://tutvot.com - сервис выгодных предложений Рунета: авиабилеты, отели, туры, финпродукты и подписки. Сравнение цен, рейтинги, промокоды и кэшбэк. Находите лучшие акции каждый день — быстро, честно, удобно.
Эффективное лечение геморроя у взрослых. Безопасные процедуры, комфортные условия, деликатное отношение. Осмотр, диагностика, подбор терапии. Современные методы без госпитализации и боли.
Sweet Bonanza: A Burst of Fruity Fun!
Dive into the colorful world of Sweet Bonanza, where juicy fruits and sugary treats bring endless excitement and big wins. Spin the reels and taste the sweetness of luck at https://k8-casino.jp/ !
Искала лучшие нейросети для генерации изображений для творческих проектов, и эта статья дала все ответы. Протестировала несколько сервисов, качество везде на высоте. Очень довольна выбором: https://vc.ru/top_rating/2301994-luchshie-besplatnye-nejroseti-dlya-generatsii-izobrazheniy
Хочешь азарта? болливуд казино отзыв мир азарта и больших выигрышей у вас в кармане! Сотни игр, щедрые бонусы и мгновенные выплаты. Испытайте удачу и получите незабываемые эмоции прямо сейчас!
Ищешь автоматы? слоты онлайн лучшие азартные развлечения 24/7. Слоты, рулетка, покер и живые дилеры с яркой графикой. Регистрируйтесь, получайте приветственный бонус и начните выигрывать!
Азартные игры онлайн покердом вход Ваш пропуск в мир высоких ставок и крупных побед. Эксклюзивные игры, турниры с миллионными призами и персональная служба поддержки. Играйте по-крупному!
Онлайн казино casino beef Насладитесь атмосферой роскошного казино не выходя из дома! Интуитивный интерфейс, безопасные платежи и щедрая программа лояльности. Сделайте свою игру выигрышной!
Лучшие онлайн казино биф казино бонусы захватывающие игровые автоматы, карточные игры и live-казино на любом устройстве. Быстрый старт, честная игра и мгновенные выплаты.
Азартные игры онлайн слоты онлайн Ваш пропуск в мир высоких ставок и крупных побед. Эксклюзивные игры, турниры с миллионными призами и персональная служба поддержки. Играйте по-крупному!
Ищешь автоматы? игровые автоматы лучшие азартные развлечения 24/7. Слоты, рулетка, покер и живые дилеры с яркой графикой. Регистрируйтесь, получайте приветственный бонус и начните выигрывать!
Хочешь азарта? болливуд казино отзыв мир азарта и больших выигрышей у вас в кармане! Сотни игр, щедрые бонусы и мгновенные выплаты. Испытайте удачу и получите незабываемые эмоции прямо сейчас!
Онлайн казино биф казино отзывы Насладитесь атмосферой роскошного казино не выходя из дома! Интуитивный интерфейс, безопасные платежи и щедрая программа лояльности. Сделайте свою игру выигрышной!
Лучшие онлайн казино биф казино бонусы захватывающие игровые автоматы, карточные игры и live-казино на любом устройстве. Быстрый старт, честная игра и мгновенные выплаты.
Хочешь рискнуть? pin up casino редлагает широкий выбор игр, быстрые выплаты и надежные способы пополнения депозита.
Официальный сайт официальный сайт pin up встречает удобным интерфейсом и обширным каталогом: слоты, лайв-казино, рулетка, турниры. Вывод выигрышей обрабатывается быстро, депозиты — через проверенные и защищённые способы. Акции, бонусы и поддержка 24/7 делают игру комфортной и понятной.
На официальном сайте кент вы найдёте слоты, рулетку, лайв-столы и тематические турниры. Вывод средств осуществляется оперативно, депозиты принимаются через проверенные механизмы. Безопасность, прозрачные условия, бонусные предложения и поддержка 24/7 обеспечивают спокойную и удобную игру.
Хочешь рискнуть? пин ап казино редлагает широкий выбор игр, быстрые выплаты и надежные способы пополнения депозита.
Официальный сайт казино пин ап встречает удобным интерфейсом и обширным каталогом: слоты, лайв-казино, рулетка, турниры. Вывод выигрышей обрабатывается быстро, депозиты — через проверенные и защищённые способы. Акции, бонусы и поддержка 24/7 делают игру комфортной и понятной.
Лучшее онлайн казино vavada bet вход с более чем 3000 игр, высокими выплатами и круглосуточной поддержкой.
Официальный сайт играть в вавада казино: играйте онлайн с бонусами и быстрыми выплатами. Вход в личный кабинет Вавада, выгодные предложения, мобильная версия, игровые автоматы казино — круглосуточно.
Нужен тахеометр? аренда тахеометра в Москве по выгодной цене. Современные модели для геодезических и строительных работ. Калибровка, проверка, доставка по городу и области. Гибкие сроки — от 1 дня. Консультации инженеров и техническая поддержка.
All the best is here with us: https://www.stylevore.com/user/npprteam
На официальном сайте играть в kent казино вы найдёте слоты, рулетку, лайв-столы и тематические турниры. Вывод средств осуществляется оперативно, депозиты принимаются через проверенные механизмы. Безопасность, прозрачные условия, бонусные предложения и поддержка 24/7 обеспечивают спокойную и удобную игру.
Нужен тахеометр? аренда тахеометра Leica по выгодной цене. Современные модели для геодезических и строительных работ. Калибровка, проверка, доставка по городу и области. Гибкие сроки — от 1 дня. Консультации инженеров и техническая поддержка.
Официальный сайт официальный сайт вавада: играйте онлайн с бонусами и быстрыми выплатами. Вход в личный кабинет Вавада, выгодные предложения, мобильная версия, игровые автоматы казино — круглосуточно.
Expanded article here: https://www.universe.com/users/nppr-team-sh50nj
Лучшее онлайн казино vavada bet вход с более чем 3000 игр, высокими выплатами и круглосуточной поддержкой.
The best is right here: https://muskaanhindi.org
Today's highlights are here: https://www.nagpurtoday.in
Learn more here: https://777score.com
The best is right here: https://anthese.fr
Top picks for you: https://redfordtheatre.com
Как юридическое лицо, довольны, что не пришлось заниматься бумажной работой. Всё сделали за нас: таможенный брокер для юридических лиц
Updated today: https://intelicode.com
All the latest here: https://antalyamerhaba.com
果博东方客服开户联系方式【182-8836-2750—】?薇- cxs20250806】
果博东方公司客服电话联系方式【182-8836-2750—】?薇- cxs20250806】
果博东方开户流程【182-8836-2750—】?薇- cxs20250806】
果博东方客服怎么联系【182-8836-2750—】?薇- cxs20250806】
Самое интересное тут: https://it-on.ru
Все подробности по ссылке: https://morshynkurort.net
Всё самое новое здесь: https://mebel-3d.ru
Все самое актуальное тут: https://topper.md
Все самое актуальное: https://luon.pro
Читать полностью на сайте: https://carina-e.ru
Read more on the website: https://waterlux.ua
Подробнее на сайте:: https://www.europneus.es
Best selection of the day: https://pechi-troyka.ru
Два адреса удобно, на Крайней ближе к дому, на Московской быстрее печатают
Mari-Med https://www.mari-med.ru Комплексное оснащение медучреждений техникой, инструментами и расходными материалами. Надежный партнер для вашей клиники.
Чурапчинская ЦРБ: https://churap-crb.ru Полный спектр медицинских услуг для жителей района.
Кореновская ЦРБ https://mbuzkcrb.ru Центральная районная больница. Качественная медицинская помощь, поликлиника и стационар.
Солнышково https://solnyshkovo.ru Центр развития и обучения для детей. Интересные занятия, подготовка к школе и творческие студии в комфортной атмосфере.
Альфа-Дент НСК https://alfadentnsk.ru Современная стоматология в Новосибирске. Профессиональное лечение и забота о вашей улыбке.
Нужен тахеометр? аренда тахеометра в Москве по выгодной цене. Современные модели для геодезических и строительных работ. Калибровка, проверка, доставка по городу и области. Гибкие сроки — от 1 дня. Консультации инженеров и техническая поддержка.
Details inside: https://buyaccutane.asia/2025/10/27/unlocking-advanced-ad-strategies/
Эль-Дент: https://eldental.ru Современный детский стоматологический центр. Профессиональное лечение, ортодонтия и реставрация.
Only top materials: https://cere-india.org
Нужен тахеометр? аренда тахеометра в Москве по выгодной цене. Современные модели для геодезических и строительных работ. Калибровка, проверка, доставка по городу и области. Гибкие сроки — от 1 дня. Консультации инженеров и техническая поддержка.
Learn more here: https://willysforsale.com/author/npprteam/
Эль-Дент: https://eldental.ru Современный детский стоматологический центр. Профессиональное лечение, ортодонтия и реставрация.
Альфа-Дент НСК https://alfadentnsk.ru Современная стоматология в Новосибирске. Профессиональное лечение и забота о вашей улыбке.
Full version of the article: https://nnvl.ru/2025/10/27/лучший-шоп-рекламных-аккаунтов/
Trusted and best: https://stoikimaging.ru/2025/10/27/google-ads-аккаунты-с-балансом/
10tr05
Discover exquisite Austrian wines at weinverkostung in wien and immerse yourself in Vienna’s vibrant wine culture.
In Wien kann man die Vielfalt osterreichischer Weine auf besondere Weise entdecken. Die Region ist bekannt fur ihren exzellenten Wei?wein, besonders den Grunen Veltliner. Viele Weinverkostungen finden in historischen Gewolbekellern statt.
Das milde Klima und die mineralreichen Boden begunstigen den Weinbau. Daher gedeihen hier besonders aromatische Rebsorten.
#### **2. Beliebte Weinregionen und Weinguter**
In Wien gibt es mehrere renommierte Weinregionen, wie den Nussberg oder den Bisamberg. Die Weinguter hier setzen auf nachhaltigen Anbau. Familiengefuhrte Weinguter bieten oft Fuhrungen und Verkostungen an. Dabei lernt man viel uber die Herstellung und Geschichte der Weine.
Ein Besuch im Weingut Wieninger oder im Mayer am Pfarrplatz lohnt sich. Sie sind bekannt fur ihre ausgezeichneten Jahrgange.
#### **3. Ablauf einer typischen Weinverkostung**
Eine klassische Wiener Weinverkostung beginnt meist mit einer Kellertour. Die Winzer erklaren gerne ihre Arbeitsschritte. Danach folgt die Verkostung unterschiedlicher Weine. Die Aromen werden von den Experten detailliert beschrieben.
Haufig werden die Weine mit lokalen Kasesorten oder Brot serviert. Diese Kombination ist ein Highlight fur Feinschmecker.
#### **4. Tipps fur unvergessliche Weinverkostungen**
Um das Beste aus einer Weinverkostung in Wien herauszuholen, sollte man vorher buchen. Viele Weinguter haben begrenzte Platze und sind schnell ausgebucht. Zudem lohnt es sich, auf die Jahreszeiten zu achten. Die warmen Monate eignen sich perfekt fur Verkostungen im Freien.
Ein guter Tipp ist auch, ein Notizbuch mitzubringen. Es hilft, personliche Favoriten zu dokumentieren.
---
### **Spin-Template fur den Artikel**
#### **1. Einfuhrung in die Weinverkostung in Wien**
Wien begeistert mit seiner langen Weintradition und zeitgenossischen Angeboten.
#### **2. Beliebte Weinregionen und Weinguter**
Die Weinguter hier setzen auf nachhaltigen Anbau.
#### **3. Ablauf einer typischen Wiener Weinverkostung**
Die Winzer erklaren gerne ihre Arbeitsschritte.
#### **4. Tipps fur unvergessliche Weinverkostungen**
Einige Anbieter bieten auch private Verkostungen an.
---
**Hinweis:** Durch Kombination der Varianten aus den -Blocken konnen zahlreiche einzigartige Texte generiert werden, die grammatikalisch und inhaltlich korrekt sind.
Портрет по фотографии на заказ https://moi-portret.ru
Need TRON Energy? buy trx energy Affordable for your wallet. Secure platform, verified sellers, and instant delivery. Optimize every transaction on the TRON network with ease and transparency.
Energy for TRON buy tron energy instant activation, transparent pricing, 24/7 support. Reduce TRC20 fees without freezing your TRX. Convenient payment and automatic energy delivery to your wallet.
Туристический портал https://cmc.com.ua авиабилеты, отели, туры и экскурсии в одном месте. Сравнение цен, отзывы, готовые маршруты, визовые правила и карты офлайн. Планируйте поездку, бронируйте выгодно и путешествуйте без стресса.
Портрет по фотографии на заказ https://moi-portret.ru
Need TRON Energy? rent tron energy Affordable for your wallet. Secure platform, verified sellers, and instant delivery. Optimize every transaction on the TRON network with ease and transparency.
Energy for TRON rent tron energy instant activation, transparent pricing, 24/7 support. Reduce TRC20 fees without freezing your TRX. Convenient payment and automatic energy delivery to your wallet.
Туристический портал https://cmc.com.ua авиабилеты, отели, туры и экскурсии в одном месте. Сравнение цен, отзывы, готовые маршруты, визовые правила и карты офлайн. Планируйте поездку, бронируйте выгодно и путешествуйте без стресса.
Повна інформація за посиланням: https://press-express.com.ua/aktualne.html
Строительный портал https://6may.org новости отрасли, нормативы и СНИП, сметы и калькуляторы, BIM-гайды, тендеры и вакансии. Каталоги материалов и техники, база подрядчиков, кейсы и инструкции. Всё для проектирования, строительства и ремонта.
Всё для стройки https://artpaint.com.ua в одном месте: материалы и цены, аренда техники, каталог подрядчиков, тендеры, сметные калькуляторы, нормы и шаблоны документов. Реальные кейсы, обзоры, инструкции и новости строительного рынка.
Новостной портал https://novosti24.com.ua с фокусом на важное: оперативные репортажи, аналитика, интервью и факты без шума. Политика, экономика, технологии, культура и спорт. Удобная навигация, персональные ленты, уведомления и проверенные источники каждый день.
Строительный портал https://6may.org новости отрасли, нормативы и СНИП, сметы и калькуляторы, BIM-гайды, тендеры и вакансии. Каталоги материалов и техники, база подрядчиков, кейсы и инструкции. Всё для проектирования, строительства и ремонта.
Топ-добірка у нас: https://suntimes.com.ua/dity.html
Всё для стройки https://artpaint.com.ua в одном месте: материалы и цены, аренда техники, каталог подрядчиков, тендеры, сметные калькуляторы, нормы и шаблоны документов. Реальные кейсы, обзоры, инструкции и новости строительного рынка.
Новостной портал https://novosti24.com.ua с фокусом на важное: оперативные репортажи, аналитика, интервью и факты без шума. Политика, экономика, технологии, культура и спорт. Удобная навигация, персональные ленты, уведомления и проверенные источники каждый день.
Дізнатись більше: https://metasearch.com.ua/rozvahy.html
Найкраще прямо тут: https://vilnapresa.com/hroshi.html
Портал о строительстве https://newboard-store.com.ua и ремонте: от проекта до сдачи объекта. Каталоги производителей, сравнение материалов, сметы, BIM и CAD, нормативная база, ленты новостей, вакансии и тендеры. Практика, цифры и готовые решения.
Современный автопортал https://carexpert.com.ua главные премьеры и тенденции, подробные обзоры, тест-драйвы, сравнения моделей и подбор шин. Экономия на обслуживании, страховке и топливе, проверки VIN, лайфхаки и чек-листы. Всё, чтобы выбрать и содержать авто без ошибок да
Современный новостной https://vestionline.com.ua портал: главные темы суток, лонгриды, мнения экспертов и объясняющие материалы. Проверка фактов, живые эфиры, инфографика, подборка цитат и контекст. Быстрый доступ с любого устройства и без лишних отвлечений.
Женский портал https://magictech.com.ua о жизни без перегруза: здоровье и красота, отношения и семья, финансы и карьера, дом и путешествия. Экспертные статьи, гайды, чек-листы и подборки. Только полезные советы и реальные истории.
Портал о строительстве https://newboard-store.com.ua и ремонте: от проекта до сдачи объекта. Каталоги производителей, сравнение материалов, сметы, BIM и CAD, нормативная база, ленты новостей, вакансии и тендеры. Практика, цифры и готовые решения.
Современный автопортал https://carexpert.com.ua главные премьеры и тенденции, подробные обзоры, тест-драйвы, сравнения моделей и подбор шин. Экономия на обслуживании, страховке и топливе, проверки VIN, лайфхаки и чек-листы. Всё, чтобы выбрать и содержать авто без ошибок да
Современный новостной https://vestionline.com.ua портал: главные темы суток, лонгриды, мнения экспертов и объясняющие материалы. Проверка фактов, живые эфиры, инфографика, подборка цитат и контекст. Быстрый доступ с любого устройства и без лишних отвлечений.
Женский портал https://magictech.com.ua о жизни без перегруза: здоровье и красота, отношения и семья, финансы и карьера, дом и путешествия. Экспертные статьи, гайды, чек-листы и подборки. Только полезные советы и реальные истории.
Всё для женщины https://wonderwoman.kyiv.ua уход и макияж, мода и стиль, психология и отношения, работа и деньги, мама и ребёнок. Тренды, тесты, инструкции, подборки брендов и сервисов. Читайте, вдохновляйтесь, действуйте.
Твой автопортал https://kia-sportage.in.ua о новых и подержанных машинах: рейтинги надёжности, разбор комплектаций, реальные тесты и видео. Помощь в покупке, кредит и страховка, расходы владения, ТО и тюнинг. Карта сервисов, советы по безопасности и сезонные рекомендации плюс
Главный автопортал https://newsgood.com.ua о драйве и прагматике: премьеры, технологии, электрокары, кроссоверы и коммерческий транспорт. Экспертные обзоры, тест-драйвы, подбор автокредита и страховки, расходы и сервис. Проверка истории авто и советы по экономии и сервисы.
Современный женский https://fashiontop.com.ua журнал: уход и макияж, капсульный гардероб, психология и отношения, питание и тренировки, карьерные советы и финансы. Честные обзоры, подборки брендов, пошаговые гайды.
Главный автопортал https://newsgood.com.ua о драйве и прагматике: премьеры, технологии, электрокары, кроссоверы и коммерческий транспорт. Экспертные обзоры, тест-драйвы, подбор автокредита и страховки, расходы и сервис. Проверка истории авто и советы по экономии и сервисы.
Всё для женщины https://wonderwoman.kyiv.ua уход и макияж, мода и стиль, психология и отношения, работа и деньги, мама и ребёнок. Тренды, тесты, инструкции, подборки брендов и сервисов. Читайте, вдохновляйтесь, действуйте.
Твой автопортал https://kia-sportage.in.ua о новых и подержанных машинах: рейтинги надёжности, разбор комплектаций, реальные тесты и видео. Помощь в покупке, кредит и страховка, расходы владения, ТО и тюнинг. Карта сервисов, советы по безопасности и сезонные рекомендации плюс
Современный женский https://fashiontop.com.ua журнал: уход и макияж, капсульный гардероб, психология и отношения, питание и тренировки, карьерные советы и финансы. Честные обзоры, подборки брендов, пошаговые гайды.
https://aviator-game.com.ua/
Еженедельный журнал https://sw.org.ua об авто и свободе дороги: премьеры, электромобили, кроссоверы, спорткары и коммерческий транспорт. Реальные тесты, долгосрочные отчёты, безопасность, кейсы покупки и продажи, кредит и страховка, рынок запчастей и сервисы рядом.
Журнал об автомобилях https://svobodomislie.com без мифов: проверяем маркетинг фактами, считаем расходы владения, рассказываем о ТО, тюнинге и доработках. Тестируем новые и б/у, объясняем опции простыми словами. Экспертные мнения, идеи маршрутов и полезные чек-листы. Всегда!.
Портал о балансе https://allwoman.kyiv.ua красота и самоуход, отношения и семья, развитие и карьера, дом и отдых. Реальные советы, капсульные гардеробы, планы тренировок, рецепты и лайфхаки. Ежедневные обновления и подборки по интересам.
Журнал об автомобилях https://svobodomislie.com без мифов: проверяем маркетинг фактами, считаем расходы владения, рассказываем о ТО, тюнинге и доработках. Тестируем новые и б/у, объясняем опции простыми словами. Экспертные мнения, идеи маршрутов и полезные чек-листы. Всегда!.
Еженедельный журнал https://sw.org.ua об авто и свободе дороги: премьеры, электромобили, кроссоверы, спорткары и коммерческий транспорт. Реальные тесты, долгосрочные отчёты, безопасность, кейсы покупки и продажи, кредит и страховка, рынок запчастей и сервисы рядом.
Портал о балансе https://allwoman.kyiv.ua красота и самоуход, отношения и семья, развитие и карьера, дом и отдых. Реальные советы, капсульные гардеробы, планы тренировок, рецепты и лайфхаки. Ежедневные обновления и подборки по интересам.
A Casino Royale online játékai lenyűgöző grafikával és izgalmas élménnyel várnak. A Casino Royale hotel és játékélmény páratlan szórakozást kínál. Fedezd fel a legjobb ajánlatokat a venice hotel casino royale játékai között. A Casino Royale játékai könnyen kezelhetők és látványosak.
Élvezd a legjobb nyereményeket és bónuszokat a Casino Royale-ban. A Casino Royale wallpaper 4K a legjobb háttér a telefonodra. A témához illő partik mindig emlékezetesek. A Casino Royale mobil verziója könnyen kezelhető. A Casino Royale coin funkció különleges extrát ad. A mobil app-ban bármikor elérheted kedvenc játékaidat. A Casino Royale mindig a játékosokért van.
Аренда авто turzila.com/ без депозита, аренда яхт и удобный трансфер в отель. Онлайн-бронирование за 3 минуты, русская поддержка 24/7, прозрачные цены. Оплата картой РФ.
Нужна фотосьемка? предметная съемка для маркетплейсов каталожная, инфографика, на модели, упаковка, 360°. Правильные ракурсы, чистый фон, ретушь, цветопрофили. Готовим комплекты для карточек и баннеров. Соответствие правилам WB/Ozon.
Автомобильный блог https://amt-auto.ru обзоры, ремонт, обслуживание и уход. Пошаговые инструкции, подбор масел и расходников, диагностика ошибок, лайфхаки, экономия на сервисе. Полезно новичкам и опытным водителям. Читай просто, делай уверенно.
Аренда авто https://tturzila.com/cars/dubai/ru без депозита, аренда яхт и удобный трансфер в отель. Онлайн-бронирование за 3 минуты, русская поддержка 24/7, прозрачные цены. Оплата картой РФ.
Нужна фотосьемка? съемка для маркетплейсов каталожная, инфографика, на модели, упаковка, 360°. Правильные ракурсы, чистый фон, ретушь, цветопрофили. Готовим комплекты для карточек и баннеров. Соответствие правилам WB/Ozon.
A Casino Royale póker játék minden játékos számára új kihívást jelent. Töltsd le most a Casino Royale alkalmazást, és kezdd el a játékot. A mobil verzió elérhető a http://casino-hungary.website.yandexcloud.net webcímen. Keresd meg a nyerő kezet a Casino Royale asztalán.
A mobil app segítségével mindig naprakész lehetsz az új játékokról. Casino Royale outfit ötletek inspirációt adnak tematikus estékhez. A nyeremények és a bónuszok valóban motiválóak. A Casino Royale bónuszrendszere mindig meglepetést tartogat. Fedezd fel az új bónuszokat, és növeld a nyerési esélyed. A legújabb élő fogadások és kaszinó játékok egy helyen. Minden sportág és játék elérhető mobilon is.
https://aviator-game.com.ua/
https://aviator-game.com.ua/
Автопортал для новичков https://lada.kharkiv.ua и профи: новости рынка, аналитика, сравнения, тесты, долгосрочные отчёты. Выбор авто под задачи, детальные гайды по покупке, продаже и трейд-ину, защита от мошенников. Правила, штрафы, ОСАГО/КАСКО и полезные инструменты и ещё
Современный журнал https://rupsbigbear.com про авто: новости индустрии, глубокие обзоры моделей, тесты, сравнительные таблицы и советы по выбору. Экономия на обслуживании и страховке, разбор технологий, безопасность и комфорт. Всё, чтобы ездить дальше, дешевле и увереннее.
Женский медиа-гид https://adviceskin.com здоровье, питание, спорт, ментальное благополучие, карьера, личные финансы, хобби и поездки. Практика вместо кликбейта — понятные гайды, чек-листы и экспертные мнения.
Современный журнал https://rupsbigbear.com про авто: новости индустрии, глубокие обзоры моделей, тесты, сравнительные таблицы и советы по выбору. Экономия на обслуживании и страховке, разбор технологий, безопасность и комфорт. Всё, чтобы ездить дальше, дешевле и увереннее.
Автопортал для новичков https://lada.kharkiv.ua и профи: новости рынка, аналитика, сравнения, тесты, долгосрочные отчёты. Выбор авто под задачи, детальные гайды по покупке, продаже и трейд-ину, защита от мошенников. Правила, штрафы, ОСАГО/КАСКО и полезные инструменты и ещё
Женский медиа-гид https://adviceskin.com здоровье, питание, спорт, ментальное благополучие, карьера, личные финансы, хобби и поездки. Практика вместо кликбейта — понятные гайды, чек-листы и экспертные мнения.
Женское медиа https://beautytips.kyiv.ua о главном: здоровье и профилактика, стиль и тренды, психологические разборы, мотивация, деньги и инвестиции, материнство и путешествия. Честные обзоры, подборка сервисов и истории читательниц.
Медиа для женщин https://feromonia.com.ua которые выбирают себя: здоровье и профилактика, ментальное благополучие, работа и развитие, материнство и хобби. Практичные инструкции, тесты, интервью и вдохновение без кликбейта.
Женский журнал https://dama.kyiv.ua о жизни без перегруза: красота и здоровье, стиль и покупки, отношения и семья, карьера и деньги, дом и путешествия. Экспертные советы, чек-листы, тренды и реальные истории — каждый день по делу.
Женское медиа https://beautytips.kyiv.ua о главном: здоровье и профилактика, стиль и тренды, психологические разборы, мотивация, деньги и инвестиции, материнство и путешествия. Честные обзоры, подборка сервисов и истории читательниц.
Медиа для женщин https://feromonia.com.ua которые выбирают себя: здоровье и профилактика, ментальное благополучие, работа и развитие, материнство и хобби. Практичные инструкции, тесты, интервью и вдохновение без кликбейта.
Женский журнал https://dama.kyiv.ua о жизни без перегруза: красота и здоровье, стиль и покупки, отношения и семья, карьера и деньги, дом и путешествия. Экспертные советы, чек-листы, тренды и реальные истории — каждый день по делу.
Всё, что важно https://gryada.org.ua сегодня: мода и стиль, бьюти-рутины, рецепты и фитнес, отношения и семья, путешествия и саморазвитие. Краткие выжимки, длинные разборы, подборки сервисов — удобно и полезно.
Всё, что важно https://gryada.org.ua сегодня: мода и стиль, бьюти-рутины, рецепты и фитнес, отношения и семья, путешествия и саморазвитие. Краткие выжимки, длинные разборы, подборки сервисов — удобно и полезно.
Женский журнал https://krasotka.kyiv.ua про баланс: красота, психология, карьера, деньги, дом и отдых. Экспертные колонки, списки покупок, планы тренировок и проверки здоровья. Материалы, к которым хочется возвращаться.
Глянец без иллюзий https://ladyone.kyiv.ua красота и здоровье с фактчекингом, стиль без переплат, карьера и деньги простым языком. Интервью, тесты, полезные гайды — меньше шума, больше пользы.
Онлайн-портал https://womanexpert.kyiv.ua для женщин, которые хотят жить в балансе. Красота, здоровье, семья, карьера и финансы в одном месте. Ежедневные статьи, подборки, советы экспертов и вдохновение для лучшей версии себя.
Женский журнал https://krasotka.kyiv.ua про баланс: красота, психология, карьера, деньги, дом и отдых. Экспертные колонки, списки покупок, планы тренировок и проверки здоровья. Материалы, к которым хочется возвращаться.
Онлайн-портал https://womanexpert.kyiv.ua для женщин, которые хотят жить в балансе. Красота, здоровье, семья, карьера и финансы в одном месте. Ежедневные статьи, подборки, советы экспертов и вдохновение для лучшей версии себя.
Глянец без иллюзий https://ladyone.kyiv.ua красота и здоровье с фактчекингом, стиль без переплат, карьера и деньги простым языком. Интервью, тесты, полезные гайды — меньше шума, больше пользы.
Мода и красота https://magiclady.kyiv.ua для реальной жизни: капсулы по сезонам, уход по типу кожи и бюджета, честные обзоры брендов, шопинг-листы и устойчивое потребление.
Всё для современной https://model.kyiv.ua женщины: уход и макияж, стиль и шопинг, психология и отношения, питание и тренировки. Честные обзоры, капсульные гардеробы, планы на неделю и проверенные советы.
Сайт для женщин https://modam.com.ua о жизни без перегруза: здоровье и красота, отношения и семья, карьера и деньги, дом и путешествия. Экспертные статьи, гайды, чек-листы и подборки — только полезное и применимое.
Всё для современной https://model.kyiv.ua женщины: уход и макияж, стиль и шопинг, психология и отношения, питание и тренировки. Честные обзоры, капсульные гардеробы, планы на неделю и проверенные советы.
Мода и красота https://magiclady.kyiv.ua для реальной жизни: капсулы по сезонам, уход по типу кожи и бюджета, честные обзоры брендов, шопинг-листы и устойчивое потребление.
Сайт для женщин https://modam.com.ua о жизни без перегруза: здоровье и красота, отношения и семья, карьера и деньги, дом и путешествия. Экспертные статьи, гайды, чек-листы и подборки — только полезное и применимое.
Реальная красота https://princess.kyiv.ua и стиль: уход по типу кожи и бюджету, капсулы по сезонам, устойчивое потребление. Гайды, шопинг-листы, честные обзоры и советы стилистов.
Медиа для женщин https://otnoshenia.net 25–45: карьера и навыки, ментальное благополучие, осознанные покупки, спорт и питание. Краткие выжимки и глубокие разборы, подборки брендов и сервисов.
Медиа для женщин https://otnoshenia.net 25–45: карьера и навыки, ментальное благополучие, осознанные покупки, спорт и питание. Краткие выжимки и глубокие разборы, подборки брендов и сервисов.
Реальная красота https://princess.kyiv.ua и стиль: уход по типу кожи и бюджету, капсулы по сезонам, устойчивое потребление. Гайды, шопинг-листы, честные обзоры и советы стилистов.
Женский сайт https://one-lady.com о балансе: работа, финансы, здоровье, дом, дети и отдых. Пошаговые инструкции, трекеры привычек, лайфхаки и вдохновляющие истории. Меньше шума — больше пользы.
Женский сайт https://one-lady.com о балансе: работа, финансы, здоровье, дом, дети и отдых. Пошаговые инструкции, трекеры привычек, лайфхаки и вдохновляющие истории. Меньше шума — больше пользы.
https://s-nano-s.ru/
Женский блог https://sunshadow.com.ua о жизни без перегруза: красота и здоровье, отношения и семья, стиль и покупки, деньги и карьера. Честные обзоры, лайфхаки, планы на неделю и личные истории — только то, что реально помогает.
Современный женский https://timelady.kyiv.ua сайт о стиле жизни: уход за собой, макияж, прически, фитнес, питание, мода и деньги. Практичные советы, разбор трендов, подборки покупок и личная эффективность. Будь в ресурсе и чувствуй себя уверенно каждый день. Больше — внутри.
Блог для женщин https://sweetheart.kyiv.ua которые выбирают себя: самоценность, баланс, карьера, финансы, хобби и путешествия. Мини-привычки, трекеры, вдохновляющие тексты и практичные советы.
Женский блог https://sunshadow.com.ua о жизни без перегруза: красота и здоровье, отношения и семья, стиль и покупки, деньги и карьера. Честные обзоры, лайфхаки, планы на неделю и личные истории — только то, что реально помогает.
Современный женский https://timelady.kyiv.ua сайт о стиле жизни: уход за собой, макияж, прически, фитнес, питание, мода и деньги. Практичные советы, разбор трендов, подборки покупок и личная эффективность. Будь в ресурсе и чувствуй себя уверенно каждый день. Больше — внутри.
Блог для женщин https://sweetheart.kyiv.ua которые выбирают себя: самоценность, баланс, карьера, финансы, хобби и путешествия. Мини-привычки, трекеры, вдохновляющие тексты и практичные советы.
Онлайн-площадка https://topwoman.kyiv.ua для женщин: стиль, бьюти-новинки, осознанность, здоровье, отношения, материнство и работа. Экспертные статьи, инструкции, чек-листы, тесты и вдохновение. Создавай лучший день, развивайся и находи ответы без лишней воды.
Портал для женщин https://viplady.kyiv.ua ценящих стиль, комфорт и развитие. Мода, уход, отношения, семья и здоровье. Только практичные советы, экспертные мнения и вдохновляющий контент. Узнай, как быть собой и чувствовать себя лучше.
Портал для женщин https://viplady.kyiv.ua ценящих стиль, комфорт и развитие. Мода, уход, отношения, семья и здоровье. Только практичные советы, экспертные мнения и вдохновляющий контент. Узнай, как быть собой и чувствовать себя лучше.
Онлайн-площадка https://topwoman.kyiv.ua для женщин: стиль, бьюти-новинки, осознанность, здоровье, отношения, материнство и работа. Экспертные статьи, инструкции, чек-листы, тесты и вдохновение. Создавай лучший день, развивайся и находи ответы без лишней воды.
Твой женский помощник https://vsegladko.net как подчеркнуть индивидуальность, ухаживать за кожей и волосами, планировать бюджет и отдых. Мода, психология, дом и карьера в одном месте. Подборки, гайды и истории, которые мотивируют заботиться о себе. Узнай больше на сайте.
Женский медиасайт https://woman365.kyiv.ua с акцентом на пользу: капсульный гардероб, бьюти-рутины, здоровье, отношения, саморазвитие и материнство. Пошаговые инструкции, списки покупок, чек-листы и экспертные ответы. Заботимся о тебе и твоем времени. Подробности — на сайте.
Женский медиасайт https://woman365.kyiv.ua с акцентом на пользу: капсульный гардероб, бьюти-рутины, здоровье, отношения, саморазвитие и материнство. Пошаговые инструкции, списки покупок, чек-листы и экспертные ответы. Заботимся о тебе и твоем времени. Подробности — на сайте.
Женский портал https://womanportal.kyiv.ua о моде, психологии и уходе за собой. Узнай, как сочетать стиль, уверенность и внутреннюю гармонию. Лучшие практики, обзоры и вдохновляющие материалы для современных женщин.
Твой женский помощник https://vsegladko.net как подчеркнуть индивидуальность, ухаживать за кожей и волосами, планировать бюджет и отдых. Мода, психология, дом и карьера в одном месте. Подборки, гайды и истории, которые мотивируют заботиться о себе. Узнай больше на сайте.
Женский портал https://womanportal.kyiv.ua о моде, психологии и уходе за собой. Узнай, как сочетать стиль, уверенность и внутреннюю гармонию. Лучшие практики, обзоры и вдохновляющие материалы для современных женщин.
Всё о развитии https://run.org.ua и здоровье детей: диагностические скрининги, логопедия, дефектология, нейропсихология, ЛФК, массаж, группы раннего развития, подготовка к школе. Планы занятий, расписание, запись онлайн, советы специалистов и проверенные методики.
Всё о развитии https://run.org.ua и здоровье детей: диагностические скрининги, логопедия, дефектология, нейропсихология, ЛФК, массаж, группы раннего развития, подготовка к школе. Планы занятий, расписание, запись онлайн, советы специалистов и проверенные методики.
Ha szeretnél kipróbálni izgalmas játékokat, a nine casino a legjobb választás. Játssz most – élvezd a 20 free spins lehetőségeket minden nap. Használd a nine casino bonus code 2024-et extra előnyökért
A nine casino magyar nyelvű ügyfélszolgálata készséges A nine casino alternative link mindig elérhető a belépéshez. A nine casino code promo extra lehetőségeket nyújt. A nine casino app mobilalkalmazása folyamatosan frissül
A nine casino bonus code 2024 használatával extra kreditet kapsz. A nine casino app segít, hogy mindig kéznél legyen a kedvenc játékaid. A nine casino vélemények alapján biztonságos
Сайт о строительстве https://blogcamp.com.ua и ремонте: проекты, сметы, материалы, инструменты, пошаговые инструкции и лайфхаки. Чек-листы, калькуляторы, ошибки и их решения. Делайте качественно и экономно.
Сайт о строительстве https://blogcamp.com.ua и ремонте: проекты, сметы, материалы, инструменты, пошаговые инструкции и лайфхаки. Чек-листы, калькуляторы, ошибки и их решения. Делайте качественно и экономно.
Советы для родителей https://agusha.com.ua на каждый день: раннее развитие, кризисы возрастов, дисциплина, здоровье, игры и учеба. Экспертные разборы, простые лайфхаки и проверенные методики без мифов. Помогаем понять потребности ребёнка и снизить стресс в семье.
Советы для родителей https://agusha.com.ua на каждый день: раннее развитие, кризисы возрастов, дисциплина, здоровье, игры и учеба. Экспертные разборы, простые лайфхаки и проверенные методики без мифов. Помогаем понять потребности ребёнка и снизить стресс в семье.
Официальный сайт Kraken kra44 безопасная платформа для анонимных операций в darknet. Полный доступ к рынку через актуальные зеркала и onion ссылки.
Официальный сайт Kraken https://kra44-cc.at безопасная платформа для анонимных операций в darknet. Полный доступ к рынку через актуальные зеркала и onion ссылки.
Родителям о главном https://rodkom.org.ua баланс режима, питание, истерики и границы, подготовка к школе, дружба и безопасность в сети. Короткие памятки, чек-листы и практики от специалистов. Только актуальные данные и решения, которые работают в реальной жизни.
Официальный сайт Kraken https://kra44-cc.at безопасная платформа для анонимных операций в darknet. Полный доступ к рынку через актуальные зеркала и onion ссылки.
Fedezd fel a legújabb nyerőgépeket és bónuszokat a nine casino oldalán. Fedezd fel az exkluzív ajánlatokat a nine casino oldalán Csatlakozz. Próbáld ki a nine casino online kaszinót most
A nine casino 5 legjobb nyerőgépe izgalmas szórakozást nyújt A nine casino alternative link mindig elérhető a belépéshez. A nine casino review oldalak is dicsérik a platformot. A nine casino app mobilalkalmazása folyamatosan frissül
A nine casino opinie pozitív visszajelzéseket mutat. A nine casino no deposit lehetősége gyors és egyszerű. A nine casino bonus code használata növeli a játékélményt
Официальный сайт Kraken https://kra44-cc.at безопасная платформа для анонимных операций в darknet. Полный доступ к рынку через актуальные зеркала и onion ссылки.
Родителям о главном https://rodkom.org.ua баланс режима, питание, истерики и границы, подготовка к школе, дружба и безопасность в сети. Короткие памятки, чек-листы и практики от специалистов. Только актуальные данные и решения, которые работают в реальной жизни.
Женский портал https://womanclub.kyiv.ua о стиле жизни, красоте и вдохновении. Советы по уходу, отношениям, карьере и саморазвитию. Реальные истории, модные тренды, психологические лайфхаки и идеи для гармонии. Всё, что важно каждой современной женщине.
Женский портал https://womanclub.kyiv.ua о стиле жизни, красоте и вдохновении. Советы по уходу, отношениям, карьере и саморазвитию. Реальные истории, модные тренды, психологические лайфхаки и идеи для гармонии. Всё, что важно каждой современной женщине.
Минимум на вывод — 500 рублей. Удобно.
Слоты с расширяющимися символами — заносы.
Автомобильный журнал https://autodream.com.ua для новичков и энтузиастов: тренды, тест-драйвы, сравнения, разбор комплектаций, VIN-проверки и подготовка к сделке. Практичные гайды по уходу и экономии, гаджеты для авто, законы и штрафы. Делимся опытом, чтобы не переплачивали.
Автомобильный журнал https://autodream.com.ua для новичков и энтузиастов: тренды, тест-драйвы, сравнения, разбор комплектаций, VIN-проверки и подготовка к сделке. Практичные гайды по уходу и экономии, гаджеты для авто, законы и штрафы. Делимся опытом, чтобы не переплачивали.
Промокод на 75 фриспинов — плюс 9к.
Современный женский https://storinka.com.ua портал с полезными статьями, рекомендациями и тестами. Тренды, красота, отношения, карьера и вдохновение каждый день. Всё, что помогает чувствовать себя счастливой и уверенной.
Мужской портал https://kakbog.com о стиле, здоровье, карьере и технологиях. Обзоры гаджетов, тренировки, уход, финансы, отношения и путешествия. Практичные советы и честные разборы каждый день.
Мужской портал https://kakbog.com о стиле, здоровье, карьере и технологиях. Обзоры гаджетов, тренировки, уход, финансы, отношения и путешествия. Практичные советы и честные разборы каждый день.
Современный женский https://storinka.com.ua портал с полезными статьями, рекомендациями и тестами. Тренды, красота, отношения, карьера и вдохновение каждый день. Всё, что помогает чувствовать себя счастливой и уверенной.
vavada casino pl
Nabycie nieruchomosci w Beskidach to szansa na stworzenie wymarzonego miejsca na wakacje lub staly dom.
Dzieki rozwijajacej sie infrastrukturze i rosnacemu zainteresowaniu turystow, ceny dzialek stopniowo wzrastaja. Region ten przyciaga milosnikow gorskich wedrowek i aktywnego wypoczynku.
#### **2. Gdzie szukac najlepszych ofert dzialek?**
Wybor odpowiedniej lokalizacji zalezy od indywidualnych potrzeb i budzetu. Warto sprawdzic profesjonalne strony internetowe, takie jak dzialki-beskidy.pl, ktore prezentuja sprawdzone oferty.
Przed zakupem nalezy dokladnie przeanalizowac dostepnosc mediow i warunki zabudowy. Niektore tereny wymagaja dodatkowych formalnosci, dlatego warto skorzystac z pomocy ekspertow.
#### **3. Jakie korzysci daje posiadanie dzialki w Beskidach?**
Nieruchomosc w gorach to nie tylko inwestycja finansowa, ale rowniez szansa na poprawe jakosci zycia. Mozna tu zbudowac dom letniskowy i cieszyc sie urokami przyrody przez caly rok.
Dodatkowo, region ten oferuje wiele atrakcji, takich jak szlaki turystyczne i stoki narciarskie. Beskidy to idealne miejsce dla tych, ktorzy cenia aktywny tryb zycia i bliskosc natury.
#### **4. Jak przygotowac sie do zakupu dzialki?**
Przed podjeciem decyzji warto skonsultowac sie z prawnikiem i geodeta. Profesjonalna pomoc pozwoli uniknac nieprzyjemnych niespodzianek zwiazanych z formalnosciami.
Wazne jest rowniez okreslenie swojego budzetu i planow zwiazanych z zagospodarowaniem terenu. Wiele osob decyduje sie na kredyt, aby sfinansowac zakup wymarzonej dzialki.
---
### **Szablon Spinu**
**1. Dlaczego warto kupic dzialke w Beskidach?**
- Beskidy to idealne miejsce dla osob szukajacych spokoju i bliskosci natury.
- Dzieki rozwojowi infrastruktury, tereny te staja sie jeszcze bardziej atrakcyjne.
**2. Gdzie szukac najlepszych ofert dzialek?**
- Warto przegladac specjalistyczne portale, ktore skupiaja sie na nieruchomosciach w Beskidach.
- Przed zakupem nalezy zweryfikowac dostepnosc mediow i mozliwosci zabudowy.
**3. Jakie korzysci daje posiadanie dzialki w Beskidach?**
- Posiadanie ziemi w gorach to szansa na zbudowanie wymarzonego domu lub miejsca wypoczynkowego.
- Coraz wiecej osob docenia walory turystyczne i rekreacyjne Beskidow.
**4. Jak przygotowac sie do zakupu dzialki?**
- Wazne jest zasiegniecie porady prawnej przed podpisaniem umowy.
- Niektore oferty umozliwiaja elastyczne formy platnosci, co moze byc korzystne.
Кэшбэк 15% даже на минимальном
уровне.
Всё про технику https://webstore.com.ua и технологии: обзоры гаджетов, тесты, сравнения, ИИ и софт, фото/видео, умный дом, авто-тех, безопасность. Пошаговые гайды, лайфхаки, подбор комплектующих и лучшие приложения. Понятно, актуально, без лишней воды.
Новостной портал https://pto-kyiv.com.ua для тех, кто ценит фактчекинг и ясность. Картина дня в одном месте: политика, экономика, общество, наука, спорт. Ежедневные дайджесты, обзоры рынков, календари событий и авторские колонки. Читайте, делитесь, обсуждайте.
Актуальные новости https://thingshistory.com без перегруза: коротко о событиях и глубоко о смыслах. Репортажи с места, интервью, разборы и аналитика. Умные уведомления, ночной режим, офлайн-доступ и виджеты. Доверяйте проверенным данным и оставайтесь на шаг впереди.
Новостной портал https://pto-kyiv.com.ua для тех, кто ценит фактчекинг и ясность. Картина дня в одном месте: политика, экономика, общество, наука, спорт. Ежедневные дайджесты, обзоры рынков, календари событий и авторские колонки. Читайте, делитесь, обсуждайте.
Всё про технику https://webstore.com.ua и технологии: обзоры гаджетов, тесты, сравнения, ИИ и софт, фото/видео, умный дом, авто-тех, безопасность. Пошаговые гайды, лайфхаки, подбор комплектующих и лучшие приложения. Понятно, актуально, без лишней воды.
Актуальные новости https://thingshistory.com без перегруза: коротко о событиях и глубоко о смыслах. Репортажи с места, интервью, разборы и аналитика. Умные уведомления, ночной режим, офлайн-доступ и виджеты. Доверяйте проверенным данным и оставайтесь на шаг впереди.
Слоты с бонусами за 50х — выгодно.
Вывел 55к на Сбер — всё чётко.
Нужна лестница? изготовление лестниц под ключ в Москве и области: замер, проектирование, производство, отделка и монтаж. Лестницы на металлокаркасе. Индивидуальные решения для дома и бизнеса.
Поиск работы https://employmentcenter.com.ru по актуальным вакансиям городов России, СНГ, стран ЕАЭС: обновления предложений работы ежедневно, рассылка свежих объявлений вакансий на E-mail, умные поисковые фильтры и уведомления в Telegram, Одноклассники, ВКонтакте. Помогаем найти работу мечты без лишних звонков и спама.
Нужно продвижение? Продвижение современных сайтов в ТОП 3 выдачи Яндекса и Google : аудит, семантика, техоптимизация, контент, ссылки, рост трафика и лидов. Прозрачные KPI и отчёты, реальные сроки, измеримый результат.
Нужна лестница? изготовление лестниц под ключ в Москве и области: замер, проектирование, производство, отделка и монтаж. Лестницы на металлокаркасе. Индивидуальные решения для дома и бизнеса.
Поиск работы https://employmentcenter.com.ru по актуальным вакансиям городов России, СНГ, стран ЕАЭС: обновления предложений работы ежедневно, рассылка свежих объявлений вакансий на E-mail, умные поисковые фильтры и уведомления в Telegram, Одноклассники, ВКонтакте. Помогаем найти работу мечты без лишних звонков и спама.
Нужно продвижение? Продвижение современных сайтов в ТОП 3 выдачи Яндекса и Google : аудит, семантика, техоптимизация, контент, ссылки, рост трафика и лидов. Прозрачные KPI и отчёты, реальные сроки, измеримый результат.
Профессиональный агент по недвижимости спб: оценка, подготовка, маркетинг, показы, торг и юрсопровождение до сделки. Фото/видео, 3D-тур, быстрый выход на покупателя.
Играешь на пианино? ноты для писанино Поможем освоить ноты, ритм, технику и красивое звучание. Индивидуальные уроки, гибкий график, онлайн-формат и авторские методики. Реальный прогресс с первого месяца.
Школа фортепиано нотя для писанино для начинающих и продвинутых: база, джазовые гармонии, разбор песен, импровизация. Удобные форматы, домашние задания с разбором, поддержка преподавателя и быстрые результаты.
Играешь на пианино? ноты для писанино Поможем освоить ноты, ритм, технику и красивое звучание. Индивидуальные уроки, гибкий график, онлайн-формат и авторские методики. Реальный прогресс с первого месяца.
Школа фортепиано обучение игры на фортепиано для начинающих и продвинутых: база, джазовые гармонии, разбор песен, импровизация. Удобные форматы, домашние задания с разбором, поддержка преподавателя и быстрые результаты.
Играю в обеденный перерыв, поднял
5к
Слоты с кластерами — мой стиль
Играю с Турции, VPN не нужен, сайт открывается напрямую
Саппорт на русском, не надо гуглить переводчик
Выводил 80к на QIWI — без комиссии
Вывод на Тинькофф — мгновенно, даже ночью
Играю третий месяц, в плюсе на
87к
Играю вечером, после работы — отдых
VIP-менеджер подогнал персональный бонус 50% на
деп
Book of Dead выдал x5000, с 500 рублей стал 2,5 ляма — не верю до сих пор
Бонус на первый деп 200%, отыграл за вечер и вывел
чистыми 8к
Кэшбэк 10% каждую неделю — реально
возвращают, не пустые слова
DD Updates – Fresh content aur quick insights bohot helpful lagay.
Dadasdas Official – Reliable content jo simple language mein deliver hota hai.
Automatizovany system https://rocketbitpro.com pro obchodovani s kryptomenami: boti 24/7, strategie DCA/GRID, rizeni rizik, backtesting a upozorneni. Kontrola potencialniho zisku a propadu.
Automatizovany system https://rocketbitpro.com pro obchodovani s kryptomenami: boti 24/7, strategie DCA/GRID, rizeni rizik, backtesting a upozorneni. Kontrola potencialniho zisku a propadu.
Выездной алкогольный https://bar-vip.ru и кофе-бар на любое мероприятие: авторские коктейли, свежая обжарка, бармен-шоу, оборудование и посуда. Свадьбы, корпоративы, дни рождения. Честные сметы, высокое качество.
Осваиваешь фортепиано? нотя для писанино популярные мелодии, саундтреки, джаз и классика. Уровни сложности, аккорды, аппликатура, советы по технике.
Осваиваешь фортепиано? нотя для писанино популярные мелодии, саундтреки, джаз и классика. Уровни сложности, аккорды, аппликатура, советы по технике.
Центр сертификации https://серт-центр.рф технические регламенты ЕАЭС, декларации, сертификаты, ISO, испытания и протоколы. Сопровождение с нуля до регистрации в Росаккредитации. Индивидуальные сроки и смета. Консультация бесплатно.
Сеть детских садов https://www.razvitie21vek.com «Развитие XXI век» - уникальная образовательная среда для детей от 1,5 лет, где каждый ребенок сможет раскрыть свои таланты. Мы предлагаем разнообразные программы для развития творческих, физических, интеллектуальных и лингвистических способностей наших воспитанников.
Pathway to Success – Helpful tips and guides that inspire exploring fresh avenues today.
Opportunity Hub – A great mix of resources that encourages exploring new options confidently.
Блог для новичков https://life-webmaster.ru запуск блога, онлайн-бизнес, заработок без вложений. Инструкции, подборки инструментов, стратегии трафика и монетизации. Практика вместо теории.
Блог для новичков https://life-webmaster.ru запуск блога, онлайн-бизнес, заработок без вложений. Инструкции, подборки инструментов, стратегии трафика и монетизации. Практика вместо теории.
Создание блога http://life-webmaster.ru и бизнеса в сети шаг за шагом: платформы, контент-план, трафик, монетизация без вложений. Готовые шаблоны и понятные инструкции для старта.
Создание блога life-webmaster.ru/ и бизнеса в сети шаг за шагом: платформы, контент-план, трафик, монетизация без вложений. Готовые шаблоны и понятные инструкции для старта.
TurkPaydexHub Review
TurkPaydexHub se distingue comme une plateforme d'investissement crypto innovante, qui exploite la puissance de l'intelligence artificielle pour fournir a ses clients des avantages decisifs sur le marche.
Son IA analyse les marches en temps reel, detecte les occasions interessantes et applique des tactiques complexes avec une finesse et une celerite inaccessibles aux traders humains, maximisant ainsi les potentiels de rendement.
Курьер заберёт документы - перевод документов с немецкого языка. Самара, перевод документов срочно! Нотариальное заверение. Любые языки. Качество и точность. Доступные цены.
Перевод с финского - перевод документов с заверением. Срочный перевод документов? Самара поможет качественно! Нотариальное заверение. Конфиденциально. Гарантия качества.
Сертификаты переведём быстро - нотариальный перевод документов адреса. Самарское бюро переводов. Документы, нотариус, срочно! Любые языки мира. Качество проверенное. Доступные цены.
Нужен интернет? стабильный интернет алматы провайдер 2BTelecom предоставляет качественный и оптоволоконный интернет для юридических лиц в городе Алматы и Казахстане. Используя свою разветвленную сеть, мы можем предоставлять свои услуги в любой офис города Алматы и так же оказать полный комплекс услуг связи.
Нужны оптовые тиражи рекламные листовки цена с фирменным стилем? Мы поможем оформить заказ любого объёма - сперсональным менеджером,согласованием макетов и доставкой. Специальные условия для юрлиц!
Нужен интернет? монтаж скс алматы провайдер 2BTelecom предоставляет качественный и оптоволоконный интернет для юридических лиц в городе Алматы и Казахстане. Используя свою разветвленную сеть, мы можем предоставлять свои услуги в любой офис города Алматы и так же оказать полный комплекс услуг связи.
Thank you for every other great article. Where else could anybody get that type of info in such an ideal means of writing? I have a presentation next week, and I am at the search for such info.
Купить Samsung S25 в Москве
A Malina Casino új bónuszai tényleg megérik, főleg ha sportfogadást is szeretsz.
A Malina Casino vélemények alapján a támogatás gyorsan válaszol. A Malina Casino review szerint az élő kaszinó része is erős.
A Malina Casino fogadas élő módban is remek. A focis tippekhez sokan ezt a domaint használják → malina-casino-hgr.website.yandexcloud.net. A Malina Casino bewertung szerint jó az ügyfélszolgálat.
A Malina Casino legit kérdésre a legtöbb review igent mond. A Malina Casino sovellus jól fut még régi Androidon is. A Malina Casino recenzja sok szempontot részletesen bemutat. A Malina Casino 7-es promó sokak kedvence lett.
ЗОЖ-журнал https://wellnesspress.ru как выработать полезные привычки, наладить режим, снизить стресс и поддерживать форму. Простые шаги, научные факты, чек-листы и планы. Начните менять жизнь сегодня.
A heti cashback sokszor jól jön, ha sportfogadást és slotokat is játszol.
A bónuszkódok tényleg működnek, csak figyelni kell az aktuális promókat. A Malina Casino testbericht gyakran dicséri a kifizetési sebességet.
A Malina Casino app download után minden gyorsabb. Mobilon sokkal kényelmesebb játszani, én is így használom → malina casino app. A Malina Casino free spins gyakran jön focis események mellé.
A Malina Casino legit kérdésre a legtöbb review igent mond. Sok magyar játékos szereti a Malina Casino pl felületét. A Malina Casino recenzja sok szempontot részletesen bemutat. A Malina Casino sportfogadás a hétvégén mindig aktív.
Перевод без проблем - для чего нужен перевод документов. Нотариальный перевод документов. Самара, срочно, недорого. Справки, дипломы, паспорта. Гарантия принятия.
Перевод с японского - нотариальный перевод документов рядом со мной. Нужен перевод документов? Самарское бюро выполнит быстро! Нотариус, любые языки. Доступные цены. Качество гарантируем.
Перевод с болгарского - перевод документов с другого языка. Перевод документов в Самаре недорого. Нотариальное заверение, срочно. Гарантия принятия в учреждениях. Конфиденциально.
Creative Spark Daily – Find inspiration to start exciting projects and explore new ideas.
Your Creative Path – Motivation and tips for trying new projects and learning daily.
Complete guide to Australian game show history. From the 1950s golden age through contemporary 2025 formats, explore everything in one comprehensive resource. https://australiangameshows.top/
dailytrendspot.click – Trends updated daily, making it easy to discover fresh ideas quickly. Trending Now Daily – Quick updates on the most talked-about trends every day.
dailytrendspot.click – Trends updated daily, making it easy to discover fresh ideas quickly. Trend Inspiration Hub – Discover ideas and inspiration from the latest trends.
Официальный сайт 1вин приятно оформлен, интерфейс не перегружен. Ставки ставятся быстро, всё отображается корректно. Деньги пришли вовремя https://1win-magic.top/
Снимки https://mdgt.top на коридори и идеи за осветление видях там
Не https://mdgt.top знаех как да скрия кабелите в хола, но сайтът предложи отлична декорация
בדיקת רכב לפי מספר חינםcan provide essential information when evaluating oldtimers, renovated classics or collectible vehicles, and it becomes even more important when exploring a global marketplace of classic cars for sale. All around the world, collectors and enthusiasts search for antique automobiles with historical value, and having accurate data at the beginning of the process helps define whether a vehicle has true potential. With online platforms bringing together classic car dealers from multiple countries, buyers can now access global inventories of antique and restored models in one place, making the search for the perfect classic easier than ever. A simple number check helps reveal ownership history, maintenance records and restoration notes, ensuring buyers know exactly what they are looking at. The world of classic cars offers iconic American muscle cars, elegant European antiques and rare Japanese oldtimers, and browsing these selections becomes more efficient when supported by accurate information. Whether someone is planning to buy, rent or simply explore available listings, global classic car marketplaces provide convenient search filters that help compare models from different countries. Enthusiasts often appreciate the ability to view cars by manufacturer, including Porsche, Ford, Chevrolet, Jaguar, Mercedes and many more, helping them narrow down their preferences. At the same time, browsing by location allows potential buyers to find vehicles in regions known for well-maintained and carefully restored vintage cars. With the growth of online classic car platforms, more sellers are showcasing their restored vehicles to a global audience, offering buyers full restoration reports, engine upgrades and high-resolution galleries. This level of detail helps collectors understand the vehicle’s authenticity and long-term value. A free number check becomes an essential part of this evaluation, serving as a foundation for a confident purchase. In a marketplace where every classic car has its own story, having accurate facts allows enthusiasts to choose models that match their expectations. Today, with hundreds of classic cars available online in one place, the combination of global dealer listings, vehicle history verification and detailed restoration data gives buyers a complete view of the classic automotive world, helping them make informed decisions and discover vehicles that truly stand out.
https://carburater.com/
Ціни https://remontuem.if.ua на монтаж душової кабіни ціна івано-франківськ порівняв тут.
Ремонт https://remontuem.if.ua і поради щодо інтер'єр вітальні в світлих тонах знайшов тут.
Огляди https://seetheworld.top про шамоні франція були дуже інформативними.
Огляди https://seetheworld.top про татранська ломниця були детальними.
услуги студии дизайна этапы работы студии дизайна интерьера
Опытный адвокат www.zemskovmoscow.ru/ в москве: защита по уголовным делам и юридическая поддержка бизнеса. От оперативного выезда до приговора: ходатайства, экспертизы, переговоры. Минимизируем риски, действуем быстро и законно.
Опытный адвокат https://www.zemskovmoscow.ru в москве: защита по уголовным делам и юридическая поддержка бизнеса. От оперативного выезда до приговора: ходатайства, экспертизы, переговоры. Минимизируем риски, действуем быстро и законно.
Русскоязычный биткоин форум: новости сети, хард/софт-кошельки, Lightning, приватность, безопасность и юридические аспекты. Гайды, FAQ, кейсы и помощь сообщества без «хайпа».
Mindful Progress Hub – Daily advice for personal growth and intentional living.
лазерный раскрой лазерная обработка металла резка
Mindful Progress Hub – Daily advice for personal growth and intentional living.
фрезерная резка фанеры лазерная резка стекла
Портал Дай Жару https://dai-zharu.ru - более 70000 посетителей в месяц! Подбор саун и бань с телефонами, фото и ценами. Недорогие финские сауны, русские бани, турецкие парные.
Портал Дай Жару https://dai-zharu.ru - более 70000 посетителей в месяц! Подбор саун и бань с телефонами, фото и ценами. Недорогие финские сауны, русские бани, турецкие парные.
בדיקת רכב לפי מספר מהווה שלב חשוב עבור כל מי שמתעניין בכלי רכב המבוססים על טכנולוגיות חדשות, במיוחד כאשר מדובר בהזדמנות ייחודית כמו המרוץ ההיברידי חשמלי הראשון. מרוץ זה מציג חוויה חדשנית שבה כלי רכב היברידיים וחשמליים מציגים את יכולותיהם, ונותן למשתתפים הזדמנות להיות חלק מתהליך שמשפיע על עתיד התחבורה. המרוץ פותח דלת לנהגים מכל הרמות, ומציג טכנולוגיות חדשות לשיפור ביצועים וחיסכון באנרגיה, מה שמוסיף רובד מיוחד לכל מי שמגיע לחוות את האירוע מקרוב. לצד חוויית המרוץ עצמה, משתתפים יכולים להכיר מערכות טעינה מהירה ויעילה, וכל אלה הופכים את האירוע לאחד מהחדשניים ביותר בתחום. עבור מי ששוקל לקחת חלק, ישנה חשיבות גדולה לבדוק את הרכב מראש כדי להבין את ביצועיו ואת התאמתו למרוץ. בדיקה זו מסייעת לזהות בעיות פוטנציאליות שעלולות להשפיע על המסלול, במיוחד כאשר מדובר ברכבים המבוססים על טכנולוגיות חדשות שאינן תמיד מוכרות לציבור הרחב. במרוץ ההיברידי חשמלי הראשון יוכלו המשתתפים ליהנות מסביבה תחרותית אך ירוקה, הכוללת חוויה קבוצתית מעשירה, וכל זאת תוך עידוד חשיבה חדשנית על עתיד התחבורה. האירוע מהווה נקודת מפגש בין חובבי נהיגה, מהנדסים ואנשי טכנולוגיה, ומדגיש את החשיבות של מעבר לעולם היברידי חשמלי בצורה אחראית ומודרנית. עבור חלק מהמשתתפים, ההיכרות עם הטכנולוגיות החדשות במרוץ מובילה להבנה עמוקה יותר של עולם הרכב החכם. עבור אחרים, זו הזדמנות להרגיש את הכוח השקט של מנועים חשמליים ואת האיזון המדויק של מערכות היברידיות. כך או כך, מדובר באירוע שמציג עתיד שבו נהיגה ספורטיבית יכולה להיות ירוקה ומתקדמת, וכל מי שיבחר לקחת חלק ימצא חוויה המשלבת טכנולוגיה, קצב ותודעה סביבתית.
https://toyotahybridrace.co.il/
Shop Australian games online: authentic traditional games, video games, board games, and more. Browse stores and compare prices at https://australiangames.top/
classychoicehub.shop – Classy selection of products, browsing was smooth and enjoyable throughout today. Chic Lifestyle Zone – Tips and ideas to refine your lifestyle and personal image.
classychoicehub.shop – Classy selection of products, browsing was smooth and enjoyable throughout today. Fashion Forward – Trendy tips to keep your look fresh and stylish every day.
Хотите купить https://kvartiratolyatti.ru квартиру? Подбор по району, классу, срокам сдачи и бюджету. Реальные цены, акции застройщиков, ипотека и рассрочка. Юридическая чистота, сопровождение «под ключ» до регистрации права.
Ритуальный сервис https://byalahome.ru/kompleksnaya-organizacziya-pohoron-polnoe-rukovodstvo/ кремация и захоронение, подготовка тела, отпевание, траурный зал, транспорт, памятники. Работаем 24/7, фиксированные цены, поддержка и забота о деталях.
Хотите купить https://kvartiratolyatti.ru квартиру? Подбор по району, классу, срокам сдачи и бюджету. Реальные цены, акции застройщиков, ипотека и рассрочка. Юридическая чистота, сопровождение «под ключ» до регистрации права.
Ритуальный сервис https://byalahome.ru/kompleksnaya-organizacziya-pohoron-polnoe-rukovodstvo/ кремация и захоронение, подготовка тела, отпевание, траурный зал, транспорт, памятники. Работаем 24/7, фиксированные цены, поддержка и забота о деталях.
Кондиционеры в Воронеже https://homeclimat36.ru продажа и монтаж «под ключ». Подбор модели, быстрая установка, гарантия, сервис. Инверторные сплит-системы, акции и рассрочка. Бесплатный выезд мастера.
Лазерные станки https://raymark.ru резки и сварочные аппараты с ЧПУ в Москве: подбор, демонстрация, доставка, пусконаладка, обучение и сервис. Волоконные источники, металлы/нержавейка/алюминий. Гарантия, расходники со склада, выгодные цены.
Кондиционеры в Воронеже https://homeclimat36.ru продажа и монтаж «под ключ». Подбор модели, быстрая установка, гарантия, сервис. Инверторные сплит-системы, акции и рассрочка. Бесплатный выезд мастера.
Mobil cihazda Pinco apk ilə oynamaq çox rahat və təhlükəsizdir. Slot sevənlər üçün Pinco-da yüzlərlə fərqli oyun seçimi var. Hem futbol bahisi, hem də kazino üçün pinco betting online çox əlverişlidir. Canlı futbol matçlarını izləyərək dərhal bahis etmək Pinco-da daha rahatdır.
Pinco aviator oyunu yüksək maraq doğurur. Pinko slotları yüksək RTP göstəricisi ilə tanınır. Kazino bonuslarını maksimum istifadə etmək üçün Pinko çox əlverişlidir.
Pinko menyusu çox sadə və anlaşıqlıdır. Pinko aviator oyununda multiplikatorlar çox dəyişkəndir.
Pinko tətbiqi oyun prosesində donma yaratmır.
פרטי רכב ה-SEAT Ibiza מציעה שילוב מרשים בין עיצוב מודרני, טכנולוגיה מתקדמת וביצועים יציבים שמייצרים חוויית נהיגה יוצאת דופן, ולכן היא נחשבת למועמדת אידיאלית עבור נהגים שמעדיפים רכב יעיל, נוח ואמין. העיצוב החיצוני של SEAT Ibiza מאופיין בקווים חדים, חזית דינמית ותאורה מתקדמת המעניקים לרכב נוכחות מרשימה בכביש, והקבינה הפנימית מספקת שילוב מוצלח של מרחב, פונקציונליות ותחושת פרימיום שלא נפוצה בקטגוריה. בגזרת הטכנולוגיה, Ibiza מצוידת במערכת מולטימדיה מתקדמת עם תמיכה מלאה בסמארטפונים, מסך מגע איכותי וממשק אינטואיטיבי שמקל על כל שליטה, כך שהנהג נהנה משליטה מלאה ומתחושת ביטחון בכל תנאי נהיגה. היא מציעה שילוב מושלם בין זריזות, חיסכון ואמינות שמבטיחים חוויית נהיגה חלקה ושקטה, ולכן היא בחירה נהדרת למי שמחפש רכב זריז אך חסכוני, שמתאים לכל מצב. גם תחום הבטיחות מקבל דגש משמעותי עם מערכות מתקדמות כמו בקרת סטייה מנתיב, זיהוי עייפות ובלימת חירום אוטומטית, וממקמת את Ibiza כאחת המכוניות הבטוחות ביותר בקטגוריה. בסיכום כל היתרונות, ברור ש-Ibiza מספקת תמורה גבוהה למחיר לצד חוויית נהיגה מצוינת, וכך Ibiza ממשיכה לבסס את מעמדה כרכב מבוקש, מתקדם ומשתלם במיוחד.
https://buy-ibiza-online.co.il/
Лазерные станки https://raymark.ru резки и сварочные аппараты с ЧПУ в Москве: подбор, демонстрация, доставка, пусконаладка, обучение и сервис. Волоконные источники, металлы/нержавейка/алюминий. Гарантия, расходники со склада, выгодные цены.
Mobil tətbiqi yükləyib Pinko-da istədiyin oyunu saniyələr içində aça bilərsən. Pinko kazino canlı diler oyunları ilə çox real atmosfer yaradır. Canlı bahisləri sevirsənsə, xüsusilə futbol oyunu zamanı əmsallar sürətlə dəyişir, buna görə də pinco az çox yararlıdır. Kazino oyunlarını mobil cihazdan idarə etmək Pinko-da çox sadədir.
Azerbaycanda mobil kazino axtaranlar Pinko-nu seçir. Pinco kazinoda turnirlər müntəzəm keçirilir. Pinco oyunları gecə-gündüz fasiləsiz işləyir.
Pinko mərc kuponları tez təsdiqlənir. Pinko kazino hadisələri üzrə push-bildirişlər də göndərir.
Pinko tətbiqi oyun prosesində donma yaratmır.
Current weather in Kotor: daytime and nighttime temperatures, precipitation probability, wind speed, storm warnings, and monthly climate. Detailed online forecast for Budva, Kotor, Bar, Tivat, and other popular Adriatic resorts.
Current weather in Kotor: daytime and nighttime temperatures, precipitation probability, wind speed, storm warnings, and monthly climate. Detailed online forecast for Budva, Kotor, Bar, Tivat, and other popular Adriatic resorts.
Interesse par 1xbet? Sur my link, vous trouverez des liens a jour vers les fichiers d'installation de l'application 1xbet, les instructions d'installation, les mises a jour, les exigences systeme et des conseils sur la connexion securisee a votre compte pour un jeu en ligne confortable.
Интернет-магазин RC19 https://anbik.ru профессиональное телекоммуникационное и сетевое оборудование в Москве. Коммутаторы, маршрутизаторы, точки доступа, патч-панели и СКС. Собственный бренд, наличие на складе, консультации и сервис.
Modern Fashion Hub – Curated stylish collections to help you shop with confidence.
Daily Fashion Scoop – Stay updated with the hottest fashion trends and stylish selections.
РВД Казань https://tatrvd.ru рукава высокого давления под заказ и в наличии. Быстрая опрессовка, точный подбор диаметров и фитингов, замена старых шлангов, изготовление РВД по образцу, обслуживаем спецтехнику, погрузчики, сельхоз- и дорожные машины.
студия дизайна интерьера спб https://dizayna-interera-spb.ru
услуги дизайна интерьера студия дизайна интерьера
заказать дизайн интерьера дизайн интерьера
студия дизайна интерьер проект дизайн интерьера отзывы
Как улучшить общение с родными и близкими — практические рекомендации https://gratiavitae.ru/
Перевод с польского - нотариус перевод документов адреса. Срочный нотариальный перевод? В Самаре выполним быстро! Документы любой сложности. Конфиденциально. Гарантия.
Перевод с вьетнамского - нотариальный перевод документов цена. Перевод паспортов, дипломов в Самаре. Нотариальное заверение. Срочно и недорого. Гарантия принятия в учреждениях.
Achieve Your Goals – Motivational tips to keep you on track and confident in achieving success.
Заказываю в DRINKIO уже давно и могу сказать - качество на уровне. Курьеры приезжают быстро, всегда всё упаковано аккуратно. Цены приемлемые, выбор большой. Очень удобно, что не нужно выходить из дома, чтобы всё получить вовремя https://drinkio70.ru/
Achieve Your Goals – Motivational tips to keep you on track and confident in achieving success.
Came across https://pinuponline-bd.com recently and decided to share it. It seems informative and could be useful to someone.
vavada ua — это актуальное зеркало для доступа к популярному онлайн-казино.
Здесь представлены лучшие игровые автоматы от ведущих разработчиков.
Сайт отличается удобным интерфейсом и быстрой работой. Игроки могут зайти на платформу как с компьютера, так и со смартфона.
#### Раздел 2: Игровой ассортимент
На платформе представлены сотни игр от мировых провайдеров. Здесь есть классические слоты, настольные игры и live-дилеры.
Особого внимания заслуживают джекпоты и турниры. Крупные выигрыши разыгрываются в прогрессивных слотах.
#### Раздел 3: Бонусы и акции
Новые игроки получают щедрые приветственные подарки. Первый депозит может быть увеличен на 100% или более.
Система лояльности поощряет постоянных клиентов. Еженедельные турниры с призовыми фондами добавляют азарта.
#### Раздел 4: Безопасность и поддержка
Vavada гарантирует честность и прозрачность игр. Вывод средств происходит быстро и без скрытых комиссий.
Служба поддержки работает в режиме 24/7. Игроки могут связаться с поддержкой через email или мессенджеры.
### Спин-шаблон
#### Раздел 1: Введение в мир Vavada
1. На vavadacasinos.neocities.org собраны лучшие игры для азартных игроков.
2. Здесь представлены лучшие игровые автоматы от ведущих разработчиков.
3. Сайт отличается удобным интерфейсом и быстрой работой.
4. vavadacasinos.neocities.org доступен круглосуточно с любых устройств.
#### Раздел 2: Игровой ассортимент
1. Ассортимент включает в себя множество игр от топовых студий.
2. Здесь есть классические слоты, настольные игры и live-дилеры.
3. Особого внимания заслуживают джекпоты и турниры.
4. Ежедневные розыгрыши привлекают тысячи участников.
#### Раздел 3: Бонусы и акции
1. Каждый новичок может рассчитывать на дополнительные фриспины.
2. Первый депозит может быть увеличен на 100% или более.
3. VIP-игроки получают персональные предложения.
4. Кешбэк и эксклюзивные предложения доступны для VIP-игроков.
#### Раздел 4: Безопасность и поддержка
1. Vavada гарантирует честность и прозрачность игр.
2. Все автоматы проходят проверку на случайность генерации чисел.
3. Служба поддержки работает в режиме 24/7.
4. Игроки могут связаться с поддержкой через email или мессенджеры.
Found this https://jokabetapp.com website recently and wanted to share it here. It contains useful details and is updated regularly.
Just sharing https://parimatch-download.in a website I recently visited. It provides helpful content that might be interesting to some users.
Windows официальная скачать https://licensed-software-1.ru
Sportni yaxshi ko'rasizmi? ufc jonli efir uz Har kuni eng yaxshi sport yangiliklarini oling: chempionat natijalari, o'yinlar jadvali, o'yin kunlari haqida umumiy ma'lumot va murabbiylar va o'yinchilarning iqtiboslari. Batafsil statistika, jadvallar va reytinglar. Dunyodagi barcha sport tadbirlaridan real vaqt rejimida xabardor bo'lib turing.
Windows 10 русская https://licensed-software-1.ru
Pinco kazino az istifadəçilərə sürətli giriş və geniş oyun seçimi təqdim edir. americanrentalcenters.net Platformaya giriş təhlükəsizdir və məlumatlarınız müasir şifrələmə ilə qorunur. Pinco yukle apk ilə canlı mərc daha sürətlidir.
Pinco casino apk download etməklə sürət qazanırsınız. Pinco kazino apk yükləmək üçün rəsmi mənbədən istifadə edin. Pinco casino app istifadəçilərə daha yüksək performans verir
Pinco az oyunlar seçimi hər zövqə uyğundur. Pinco canlı mərc real vaxtda yüksək əmsallar təklif edir. Pinco casino download apk sürətli quraşdırılır. Pinco app download istifadəçilərə rahat menyu təqdim edir.
Pinco kazino az istifadəçilərə sürətli giriş və geniş oyun seçimi təqdim edir. pinco bonus Aktiv oyunçular üçün gündəlik bonuslar və xüsusi kampaniyalar mövcuddur, qeydiyyat isə cəmi bir neçə saniyə çəkir. Pinco oyna az bölməsi həm slot, həm də canlı oyunları əhatə edir.
Pinco yeni giriş ünvanı həmişə aktiv və təhlükəsizdir. Pinco aviator oyunu çox populyardır və yüksək emosiyalar yaşadır. Pinco casino app istifadəçilərə daha yüksək performans verir
Pinco canlı oyunlar real vaxtda yayım keyfiyyəti ilə fərqlənir. Pinco azərbaycan giriş hər zaman açıqdır. Pinco oyna mobil cihazlar üçün optimallaşdırılıb. Pinco casino apk indir daha sabit performans verir.
findpurposeandpeace.shop – Calm and inspiring content helps discover purpose and maintain peace today. Purposeful Actions Daily – Resources for taking mindful steps toward personal goals.
findpurposeandpeace.shop – Calm and inspiring content helps discover purpose and maintain peace today. Purposeful Actions Daily – Resources for taking mindful steps toward personal goals.
Купить квартиру https://kvartiratltpro.ru без переплат и нервов: новостройки и вторичка, студии и семейные планировки, помощь в ипотеке, полное сопровождение сделки до ключей. Подбор вариантов под ваш бюджет и район, прозрачные условия и юридическая проверка.
Sportni yaxshi ko'rasizmi? futbol jonli efir Har kuni eng yaxshi sport yangiliklarini oling: chempionat natijalari, o'yinlar jadvali, o'yin kunlari haqida umumiy ma'lumot va murabbiylar va o'yinchilarning iqtiboslari. Batafsil statistika, jadvallar va reytinglar. Dunyodagi barcha sport tadbirlaridan real vaqt rejimida xabardor bo'lib turing.
Купить квартиру https://kvartiratltpro.ru без переплат и нервов: новостройки и вторичка, студии и семейные планировки, помощь в ипотеке, полное сопровождение сделки до ключей. Подбор вариантов под ваш бюджет и район, прозрачные условия и юридическая проверка.
Планируете купить квартиру https://kupithouse-spb.ru для жизни или инвестиций? Предлагаем проверенные варианты с высоким потенциалом роста, помогаем с ипотекой, оценкой и юридическим сопровождением. Безопасная сделка, понятные сроки и полный контроль каждого шага.
Хотите купить квартиру? https://spbnovostroyca.ru Подберём лучшие варианты в нужном районе и бюджете: новостройки, готовое жильё, ипотека с низким первоначальным взносом, помощь в одобрении и безопасная сделка. Реальные объекты, без скрытых комиссий и обмана.
Планируете купить квартиру https://kupithouse-spb.ru для жизни или инвестиций? Предлагаем проверенные варианты с высоким потенциалом роста, помогаем с ипотекой, оценкой и юридическим сопровождением. Безопасная сделка, понятные сроки и полный контроль каждого шага.
Хотите купить квартиру? https://spbnovostroyca.ru Подберём лучшие варианты в нужном районе и бюджете: новостройки, готовое жильё, ипотека с низким первоначальным взносом, помощь в одобрении и безопасная сделка. Реальные объекты, без скрытых комиссий и обмана.
perplexity ai купить подписку https://uniqueartworks.ru/perplexity-kupit.html
Оценщик ущерба приехал вовремя и сделал качественный отчет: уведомление об осмотре квартиры после залива
Daily Style Market – Discover trendy products organized for easy browsing and selection.
Trend Explorer Hub – Discover the latest stylish products and enjoy an easy shopping journey.
Купить квартиру https://kupikvartiruvspb.ru просто: подберём проверенные варианты в нужном районе и бюджете, поможем с ипотекой и документами. Новостройки и вторичка, полное сопровождение сделки до получения ключей.
Купить квартиру https://kupithouse-ekb.ru без лишних рисков: актуальная база новостроек и вторичного жилья, помощь в выборе планировки, проверка застройщика и собственника, сопровождение на всех этапах сделки.
https://slotuna-official.com/
Купить квартиру https://kupikvartiruvspb.ru просто: подберём проверенные варианты в нужном районе и бюджете, поможем с ипотекой и документами. Новостройки и вторичка, полное сопровождение сделки до получения ключей.
Купить квартиру https://kupithouse-ekb.ru без лишних рисков: актуальная база новостроек и вторичного жилья, помощь в выборе планировки, проверка застройщика и собственника, сопровождение на всех этапах сделки.
https://roulettinocasino-fr.com/
Квартира от застройщика https://novostroycatlt.ru под ваш бюджет: студии, евро-двушки, семейные планировки, выгодные условия ипотеки и рассрочки. Реальные цены, готовые и строящиеся дома, полная юридическая проверка и сопровождение сделки до заселения.
купить меф кокаин гашиш пермь порно большие сиськи
Квартира от застройщика https://novostroycatlt.ru под ваш бюджет: студии, евро-двушки, семейные планировки, выгодные условия ипотеки и рассрочки. Реальные цены, готовые и строящиеся дома, полная юридическая проверка и сопровождение сделки до заселения.
інформаційний портал https://36000.com.ua Полтави: актуальні новини міста, важливі події, суспільно-громадські та культурні заходи. Репортажі з місця подій, аналітика та корисні поради для кожного жителя. Увага до деталей, життя Полтави в публікаціях щодня.
інформаційний портал https://36000.com.ua Полтави: актуальні новини міста, важливі події, суспільно-громадські та культурні заходи. Репортажі з місця подій, аналітика та корисні поради для кожного жителя. Увага до деталей, життя Полтави в публікаціях щодня.
Trendy Finds Daily – Discover the latest fashion and lifestyle essentials for effortless shopping.
перевод документов удаленно апостиль перевод документов
Everyday Style Hub – Browse curated, trendy items that make styling simple and enjoyable.
быстрый перевод документов перевод документов для визы
Экспертиза после затопления позволила документально подтвердить ущерб: если протекает балкон к кому обращаться
https://sportuna-casino-gr.com/
Оценщик провел осмотр и подготовил понятный отчет - https://zaliv-expertiza.ru/
happytrendstore.shop – Cheerful shopping experience, enjoyable to explore latest trends and stylish items today. Happy Finds Daily – Handpicked collections to inspire and motivate your daily choices.
happytrendstore.shop – Cheerful shopping experience, enjoyable to explore latest trends and stylish items today. Your Trendy Picks – Find unique and fun items that make shopping easy and enjoyable.
перевод документов с англ перевод документов удаленно
Simply wish to say your article is as surprising. The clearness on your put up is simply cool and i could assume you're knowledgeable in this subject. Well along with your permission let me to snatch your feed to keep updated with drawing close post. Thank you a million and please keep up the enjoyable work.
Find Female Escorts Brazil
futobol primoy efir ufc jonli efir uz
перевод документов загс платный перевод документов
boks yangiliklari ufc jonli efir uz
I'd like to find out more? I'd like to find out some additional information.
escorts Brasilia
sportuz yangiliklari boks natijalari
Не https://mdgt.top знаех как се чисти йод от кожа, докато не видях съветите там
Affordable Picks Daily – Find practical products at prices that won’t break the bank.
sport yangiliklari jahon chempionati futbol
Комбинация https://mdgt.top сиво и кафяво в кухнята е топ – видях я там
Affordable Picks Daily – Find practical products at prices that won’t break the bank.
Прочитав https://seetheworld.top/ статтю про шавмоні — інформативно.
Замовив https://remontuem.if.ua послугу — дізнався все про штукатурка стін ціна.
Друзі https://seetheworld.top/ порадили для пояна брашов.
Деталі https://remontuem.if.ua про штукатурка стін івано-франківськ знайшов на сайті.
dealhubcentral – Great bargains, I was impressed with how affordable everything is today.
Urban trend finds – Several standout options appeared right away, browsing easy.
valuevaultstore – Found fantastic bargains, loved the quick service.
Urban trend finds – Several standout options appeared right away, browsing easy.
Style & Trend Hub – Browse curated selections effortlessly and enjoy discovering new favorites.
Daily Fashion Hub – Explore popular categories with ease and enjoy a fun browsing experience.
affordableshoppinghub – Great selection at low prices, checkout was fast.
thriftyfindsonline – Great bargains today, checkout was simple and fast.
Browse urban outfits – A couple of standout selections were visible immediately, very convenient.
Discover top fashion finds – Found several attractive and trendy items quickly, browsing smooth.
modernvaluecollection – Found modern items easily, website loads fast and browsing feels smooth. modernpick – Great assortment of items, delivery was seamless and reliable.
modernvaluecollection – Found modern items easily, website loads fast and browsing feels smooth. modernpickhub – Great assortment of items, delivery was reliable and fast.
valuebrightshop – Great deals and very user-friendly, shopping felt effortless.
Скрипт обменника https://richexchanger.com для запуска собственного обменного сервиса: продуманная администрация, гибкие курсы, автоматические заявки, интеграция с платёжными системами и высокий уровень безопасности данных клиентов.
Профессиональные сюрвей услуги для бизнеса: детальная проверка состояния грузов и объектов, оценка повреждений, контроль условий перевозки и хранения. Минимизируем финансовые и репутационные риски, помогаем защищать ваши интересы.
Скрипт обменника https://richexchanger.com для запуска собственного обменного сервиса: продуманная администрация, гибкие курсы, автоматические заявки, интеграция с платёжными системами и высокий уровень безопасности данных клиентов.
Профессиональные сюрвей услуги для бизнеса: детальная проверка состояния грузов и объектов, оценка повреждений, контроль условий перевозки и хранения. Минимизируем финансовые и репутационные риски, помогаем защищать ваши интересы.
brightgiftshub – The site has amazing gift options, very easy to navigate.
joyfulgiftsstore – Loved the gift options, site navigation was very easy.
https://telegra.ph/Lemon-Casino-50-Free-Spins-i-pe%C5%82ny-przewodnik-po-najcz%C4%99%C5%9Bciej-szukanych-bonusach-11-24
Urban fashion hub online – Some standout items appeared instantly, browsing convenient.
Check this style collection – Found several appealing fashion picks quickly, browsing was smooth.
stylefinder – Trendy outfits found easily, site navigation was smooth.
trendemporium – Excellent trendy outfits available, checkout went quickly and easily.
brightshoppingcentral – Very convenient to shop, plenty of options and simple checkout.
brightshoppingdeals – Pleasant experience, site layout made it easy to browse items.
fashionflarehub – Great trendy finds, smooth checkout and fast delivery.
stylehunterhub – Trendy items and quick checkout, very satisfied with the site.
Shop urban fashion – Quickly spotted a handful of stylish pieces, navigation effortless.
Browse latest fashion – Found a couple of eye-catching picks fast, very user-friendly.
pickhubdaily – Loved the product variety, delivery seemed prompt and smooth.
happyfinds – Found quality products easily, shipping was prompt and reliable.
Фитляндия https://fit-landia.ru интернет-магазин товаров для спорта и фитнеса. Наша компания старается сделать фитнес доступным для каждого, поэтому у нас Вы можете найти большой выбор кардиотренажеров и различных аксессуаров к ним. Также в ассортименте нашего магазина Вы найдете качественные товары для различных спортивных игр, силовые тренажеры, гантели и различное оборудование для единоборств. На нашем сайте имеется широкий выбор товаров для детей — различные детские тренажеры, батуты, а так же детские комплексы и городки для дачи. Занимайтесь спортом вместе с Фитляндией
Нежные авторские торты на заказ с индивидуальным дизайном и натуральными ингредиентами. Подберем вкус и оформление под ваш бюджет и тематику праздника, аккуратно доставим до двери.
marketfindscenter – Excellent product range, navigation felt smooth and fast.
dailyglobalfinds – Great selection of items, pages loaded quickly and shopping was easy.
Фитляндия https://fit-landia.ru интернет-магазин товаров для спорта и фитнеса. Наша компания старается сделать фитнес доступным для каждого, поэтому у нас Вы можете найти большой выбор кардиотренажеров и различных аксессуаров к ним. Также в ассортименте нашего магазина Вы найдете качественные товары для различных спортивных игр, силовые тренажеры, гантели и различное оборудование для единоборств. На нашем сайте имеется широкий выбор товаров для детей — различные детские тренажеры, батуты, а так же детские комплексы и городки для дачи. Занимайтесь спортом вместе с Фитляндией
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Special Finds Hub – Explore fashion and lifestyle products that stand out.
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Daily Special Finds – Browse exclusive products and unique picks for everyday style.
trendspotstore – Loved how easy it is to find what I wanted, very smooth browsing.
Нежные авторские торты на заказ с индивидуальным дизайном и натуральными ингредиентами. Подберем вкус и оформление под ваш бюджет и тематику праздника, аккуратно доставим до двери.
trendfusionhub – Browsing the site was effortless, design is very user-friendly.
Dive deeper here: https://girls-live-cams.com
Top fashion picks – Several eye-catching items popped up instantly, browsing enjoyable.
Shop trendy outfits – Some standout pieces were instantly visible, browsing simple.
globalbazaar – Nice assortment of items, shopping experience was smooth and enjoyable.
choiceplanet – Found a variety of items, prices are fair and checkout was smooth.
https://rich513.com/
https://rich513.com/
Full breakdown here: https://erovideochat.pw
Current recommendations: https://erochats.org
homecornerdeals – Pleasant experience, fast page loads and effortless navigation.
besthomefinds – Excellent product range, site layout made browsing very simple.
Updated today: https://livevideochat18.ru
glamhubgifts – Found high-quality gifts easily, prices were fair and very happy.
Read the extended version: https://guyscams.ru
More insights at the link: https://ru.flirt888.com
giftfinderhub – Amazing selection of gifts, pricing is great and products are excellent.
Our highlights: https://ru.flirt888.com
Continue reading here: https://livesex-888.com
Urban style link – Found multiple fashionable items fast, layout user-friendly.
Browse trendy picks – Quickly found multiple appealing items, navigation simple.
urbanstylehub – Loved browsing the latest urban fashion, site navigation was quick and seamless.
urbanpickshub – Loved exploring fashionable urban clothing, navigation was fast and smooth.
Unlock Daily Growth – Explore actionable tips to boost your skills and overall potential.
Growth & Potential Hub – Discover tips and inspiration to develop your skills and reach new heights.
quickfindshop – Pleasant experience, items were easy to locate and order.
globalfindscenter – Very convenient to shop, fast loading and intuitive layout.
brightlivingcorner – Shopping was fast and hassle-free, loved the offers.
happyfindshub – The deals are fantastic, purchasing was quick and easy.
Urban style link – Found multiple fashionable items fast, layout user-friendly.
Explore top fashion picks – Quickly discovered a few appealing items, layout felt clean.
simplegiftfinder – Found perfect gifts easily, site is organized and very user-friendly. giftzonehub – Great assortment of gift items, delivery was reliable and fast.
simplegiftfinder – Found perfect gifts easily, site is organized and very user-friendly. giftcornerhub – Great assortment of items, shipping felt prompt and hassle-free.
https://telegra.ph/Fontan-Casino-Twoja-Brama-do-Elektryzuj%C4%85cej-Rozrywki-i-Wygranych-11-22
https://t.me/s/leon_casino_play
https://www.prom-polimer.ru/
Top picks for you: https://rt.lindachat.ru
All you need to know: https://videochat-18.com
https://t.me/s/leon_casino_play
bestmodernfashion – Wide selection of trendy clothing, navigation felt seamless and natural.
modernstylepicks – Very easy to navigate, ordering was smooth and fast.
cheercornerhub – Excellent products and very responsive customer support.
brightchoicehub – Items were fantastic, customer service was friendly and reliable.
Finally, a metabolism plan that considers gender differences in hormones and fat metabolism. https://metabolicfreedom.top/ metabolic freedom podcast
Shop crisp fashion styles – A handful of trendy outfits popped up instantly, site well-organized.
Check fashion items – A few interesting styles were easy to find immediately, layout clean.
stylefinder – Great variety of outfits today, checkout process was effortless.
modernlifestylecorner.shop – Modern lifestyle products look stylish, browsing categories was simple and Your Modern Guide – Daily guidance for personal growth, creativity, and contemporary living.
trendpick – Found trendy outfits effortlessly, site navigation felt smooth.
modernlifestylecorner.shop – Modern lifestyle products look stylish, browsing categories was simple and Trendy Living Hub – Explore modern solutions and tips for a balanced and stylish lifestyle.
Join legit best crypto signals providers with trusted community reviews. Reviewed groups offer alpha calls with best buy and sell recommendations verified through trustworthy TradingView trading analysis.
Subscription tier comparison reveals value when you buy robux through Premium. Different membership levels offer varying monthly Robux amounts and benefits allowing players to select plans matching their activity level and budget.
https://telegra.ph/Fontan-Casino-Twoja-Nowa-Jako%C5%9B%C4%87-Rozrywki-Online-11-22
Trustworthy alpha comes from crypto signals groups with legit credentials. Join trusted telegram channels offering reviewed best buy and sell recommendations backed by TradingView analysis.
Location research reveals where to buy robux through authorized channels. Official Roblox lists verified retailers and digital platforms ensuring transactions protect account security and Terms of Service compliance.
stylefinderhub – Fast delivery and great selection, loved the fashionable items.
СТО в Люберцах https://sto-cars.ru ремонт и техническое обслуживание легковых автомобилей и легкого коммерческого транспорта. Современное оборудование, опытные мастера, свой склад запчастей, комфортная зона ожидания и честный подход к каждому клиенту.
Старые фунты? https://funtfrank.ru Обменяйте легко и без комиссий! Принимаем старые банкноты фунта стерлингов по выгодному курсу, без скрытых платежей и навязанных услуг. Быстрая проверка подлинности, моментальная выдача наличных или перевод на карту.
stylehunterstore – Fast delivery and very fashionable items, loved everything.
trendchoicehub – Smooth browsing and user-friendly design, products were easy to locate.
Browse urban outfits – A couple of standout selections were visible immediately, very convenient.
trendfindshub – Smooth site layout, fast loading pages, and enjoyable shopping experience.
Top urban picks – Quickly spotted multiple appealing pieces, smooth scrolling experience.
dailystylehub – Great selection of outfits, browsing and checkout felt effortless.
dailystylehub – Great selection of outfits, browsing and checkout felt effortless.
casino fontan
Action tips: https://registraciavsaita.listbb.ru/viewtopic.php?f=3&t=4823
Learn More: https://beacons.ai/npprteamshopz1
Expanded article here: https://mangorpp.getbb.ru/viewtopic.php?f=2&t=1804
All the latest here: https://inbestia.com/usuarios/npprteamshopz
trendhubstore – Found exactly what I needed, the site loads very fast and smooth.
glamhubonline – Items were easy to find, site loads smoothly and efficiently.
Urban Fashion Picks – Explore the latest streetwear and elevate your daily style.
Urban Wardrobe Daily – Tips and trendy fashion finds for updating your everyday style.
Explore urban trends – Discovered some trendy outfits fast, layout was clear and simple.
Check this style collection – Found several appealing fashion picks quickly, browsing was smooth.
trendstylehub – Smooth browsing and fast checkout, really liked the selection.
chicdaily – Loved browsing today’s trends, navigating the site was simple and efficient.
purestylepicks – Great variety, shopping was enjoyable and effortless.
chicdaily – Loved browsing today’s trends, navigating the site was simple and efficient.
stylefinderstore – Excellent items at good prices, made shopping enjoyable.
fashionflarehub – Loved the smooth browsing experience and the deals.
Check this style collection – Found several appealing fashion picks quickly, browsing was smooth.
Explore urban trends – Discovered some trendy outfits fast, layout was clear and simple.
giftnook – Found perfect gift ideas, shipping seems fast and trustworthy.
giftmania – Found wonderful presents, delivery appears very dependable.
stylishfamilypicks – Pleasant shopping experience, easy to find everything I wanted.
bestfamilyfashion – Wide selection, placing an order was simple and fast.
Daily Growth Spot – Explore resources to help you develop skills and confidence every day.
экстренное вытрезвление на дому спб
Flourish & Thrive Daily – Guidance for building positive habits and growing consistently.
savehubonline – Excellent savings and very easy shopping experience.
discountvaulthub – Amazing savings and quick checkout, very happy with my order.
Мне кажется, спорт дал мне дисциплину и уверенность
glamtrend – Found stylish items today, browsing was fast and simple.
trendpick – Found trendy items effortlessly, browsing felt quick and easy.
urbanzonehub – Quick navigation, found several trendy products easily.
urbanfashionstore – Wide variety of urban products, pages loaded quickly and shopping was enjoyable.
Профессиональные электромонтажные работы в квартирах, домах и офисах. Замена проводки, монтаж щитков, автоматов, УЗО, светильников и розеток. Работаем по нормам ПУЭ, даём гарантию и подробный акт выполненных работ.
Visit an elephant sanctuary: care, rehabilitation, and protection of animals. Learn their stories, participate in feedings, and observe elephants in the wild, not in a circus.
SoftStone Offering – Beautiful collection, easy browsing, and delivery arrived promptly.
SoftStone Outlet – Easy-to-browse site, great variety, and shipping was quick.
trendcentralstore – Easy browsing and stylish seasonal items, highly recommend.
trendfinderhub – Easy to find seasonal favorites, shopping was hassle-free.
trendylane – Great selection of trends today, browsing through products was seamless.
экстренное вытрезвление на дому спб
stylefinder – Enjoyed checking out trendy outfits, the website loaded quickly.
Love elephants? elephant sanctuary: no rides or shows, just free-roaming elephants, nature trails, guided tours, and the chance to learn what responsible wildlife management looks like.
An ethical elephant sanctuary: rehabilitation, care, veterinary monitoring, and freedom of movement instead of attractions. By visiting, you support the project and help elephants live in dignified conditions.
Фит
Ловушки для колорадского жука своими руками — экономия огромная
Хочеш зазнати успіху? найкраще онлайн казино: свіжі огляди, рейтинг майданчиків, вітальні бонуси та фрізпіни, особливості слотів та лайв-ігор. Докладно розбираємо правила та нагадуємо, що грати варто лише на вільні кошти.
shoppingcollectionhub – Loved browsing, navigation and checkout were quick and easy.
buyingcornerhub – Found many useful items, navigation was smooth and effortless.
Проблемы со здоровьем? невролог центр: комплексные обследования, консультации врачей, лабораторная диагностика и процедуры. Поможем пройти лечение и профилактику заболеваний в комфортных условиях без очередей.
ORBS Production https://filmproductioncortina.com is a full-service film, photo and video production company in Cortina d’Ampezzo and the Dolomites. We create commercials, branded content, sports and winter campaigns with local crew, alpine logistics, aerial/FPV filming and end-to-end production support across the Alps. Learn more at filmproductioncortina.com
Проблемы со здоровьем? невролог взрослый краснодар: комплексные обследования, консультации врачей, лабораторная диагностика и процедуры. Поможем пройти лечение и профилактику заболеваний в комфортных условиях без очередей.
ORBS Production https://filmproductioncortina.com is a full-service film, photo and video production company in Cortina d’Ampezzo and the Dolomites. We create commercials, branded content, sports and winter campaigns with local crew, alpine logistics, aerial/FPV filming and end-to-end production support across the Alps. Learn more at filmproductioncortina.com
trendspotstore – Loved the variety of items, pages load smoothly every time.
trendfinderstore – Nice variety of fashion, the site loads instantly without lag.
video chat rooms 321 chat online
казіно з бонусами бонусы казино
modatrend – Great assortment, browsing felt quick and smooth.
modafusion – Great collection, site was fast and checkout was simple.
WildSand Trend Store – Beautiful products, intuitive layout, and the package arrived promptly.
EverMountain Shop – Browsing felt easy and all the items looked trendy.
EverMountain Boutique Hub – Fast navigation and items are fashionable and accessible.
Wild Sand Emporium – Easy-to-use site, unique products, and very satisfied with my order.
хочется материалов с реальными цифрами
Daily Ambition Hub – Ideas and encouragement to grow, plan, and achieve your dreams effectively.
Big Dream Inspiration – Creative ideas and guidance to motivate you toward personal and professional success.
Lunar Harvest Studio Picks – Easy to navigate with a clean and organized interface.
Bright Flora Boutique – Items are neatly arranged, making the experience enjoyable.
Lunar Harvest Picks – Loved the clear layout and fast-loading pages.
Bright Flora Online – Navigation is easy, and browsing through items is pleasant.
modafinds – Pleasantly surprised by the fast navigation and wide range.
valuefashionhub – Checkout was smooth and the site was easy to use.
Soft Cloud Favorites – Enjoyable navigation and the site layout is simple to follow.
Soft Cloud Favorites – Enjoyable navigation and the site layout is simple to follow.
trendfinderurban – Loved the products, prices are fair and very competitive.
urbanstyleonline – Products are amazing, prices are very competitive and reasonable.
harbornowhub – Fast-loading pages with clear product displays and easy exploration.
timelessharbortrends – Easy-to-use site with visually appealing and organized products.
ЦВЗ центр https://cvzcentr.ru в Краснодаре — команда специалистов, которая работает с вегетативными расстройствами комплексно. Детальная диагностика, сопровождение пациента и пошаговый план улучшения самочувствия.
Nairabet offers https://nairabet-play.com sports betting and virtual games with a simple interface and a wide range of markets. The platform provides live and pre-match options, quick access to odds, and regular updates. Visit the site to explore current features and decide if it suits your preferences.
trendfinder – Found urban fashion easily, shopping today was smooth and fast.
glamtrend – Found stylish urban products today, browsing felt smooth and effortless.
ЦВЗ центр https://cvzcentr.ru в Краснодаре — команда специалистов, которая работает с вегетативными расстройствами комплексно. Детальная диагностика, сопровождение пациента и пошаговый план улучшения самочувствия.
Nairabet offers https://nairabet-play.com sports betting and virtual games with a simple interface and a wide range of markets. The platform provides live and pre-match options, quick access to odds, and regular updates. Visit the site to explore current features and decide if it suits your preferences.
v
v
FreshWind Online Shop – Beautiful product display and the checkout was simple from start to finish.
Fresh Wind Emporium – Loved the updated collection; clear photos made choosing easy, and the whole process felt smooth.
особенно интересны ошибки новичков
Todo sobre el cafe https://laromeespresso.es y el arte de prepararlo: te explicaremos como elegir los granos, ajustar la molienda, elegir un metodo de preparacion y evitar errores comunes. Prepara un cafe perfecto a diario sin salir de casa.
Todo sobre el cafe https://laromeespresso.es y el arte de prepararlo: te explicaremos como elegir los granos, ajustar la molienda, elegir un metodo de preparacion y evitar errores comunes. Prepara un cafe perfecto a diario sin salir de casa.
Modern Harbor Deals – Items load quickly, and navigation is simple.
Infraestructura y tecnologia https://novo-sancti-petri.es vial en Europa: innovacion, desarrollo sostenible y soluciones inteligentes para un transporte seguro y eficiente. Tendencias, proyectos, ecotransporte y digitalizacion de la red vial.
Modern Harbor Deals – Items load quickly, and navigation is simple.
Infraestructura y tecnologia https://novo-sancti-petri.es vial en Europa: innovacion, desarrollo sostenible y soluciones inteligentes para un transporte seguro y eficiente. Tendencias, proyectos, ecotransporte y digitalizacion de la red vial.
uniquefindshub – Fast and simple shopping experience, pages loaded quickly.
Try & Create Daily – Simple ways to experiment, innovate, and discover new skills.
uniqueitemscorner – Excellent selection, ordering process was quick and effortless.
Try Something New Hub – Inspiring ideas to experiment and create with confidence.
glamhubonline – Loved the items, site loads fast with no delays.
trendspotcorner – Nice selection of trendy items, the site loads quickly every time.
Full Circle Essentials – Smooth browsing experience with well-organized categories.
Full Circle Deals – Finding items is effortless with a simple, neat design.
Rodaballo Al Horno https://rodaballoalhorno.es es un viaje a los origenes de la musica. Exploramos las raices, los ritmos y las melodias de diferentes culturas para mostrar como el sonido conecta a personas de todo el mundo y las ayuda a sentirse parte de una conversacion musical mas amplia.
discountspot – Nice selection of products at great prices, navigating was seamless.
PureField Goods – Very smooth navigation and products are clearly visible.
Rodaballo Al Horno https://rodaballoalhorno.es es un viaje a los origenes de la musica. Exploramos las raices, los ritmos y las melodias de diferentes culturas para mostrar como el sonido conecta a personas de todo el mundo y las ayuda a sentirse parte de una conversacion musical mas amplia.
PureField Studio Shop – Simple to navigate with neatly displayed and accessible products.
dealhunterhub – Found excellent products instantly, navigating the pages was simple.
Todo sobre videojuegos https://tejadospontevedra.es noticias y tendencias: ultimos lanzamientos, anuncios, analisis, parches, esports y analisis de la industria. Analizamos tendencias, compartimos opiniones y recopilamos informacion clave del mundo de los videojuegos en un solo lugar.
Todo sobre videojuegos https://tejadospontevedra.es noticias y tendencias: ultimos lanzamientos, anuncios, analisis, parches, esports y analisis de la industria. Analizamos tendencias, compartimos opiniones y recopilamos informacion clave del mundo de los videojuegos en un solo lugar.
BrightWind Online Shop – Beautiful pieces, an easy buying process, and fast shipping.
Bright Wind Storefront – Nice collection, very responsive site, and quick delivery overall.
Timber Grove Finds – Navigation is effortless, and shopping feels simple.
Timber Grove Picks – The store is well organized, making browsing enjoyable.
trendfusionstore – Items arrived fast and the process was hassle-free.
fashionexpresshub – The items are stylish, and shopping was very straightforward.
happypickdeals – Wide selection and simple checkout, browsing was enjoyable.
topdealcorner – Fast page loads and smooth ordering, very satisfying experience.
NatureRail Shop – Loved the calming vibe, items were easy to explore.
NatureRail Select – Very calming browsing experience with items easy to locate.
dailytrendspot.click – Trends updated daily, making it easy to discover fresh ideas quickly. Trending Now Daily – Quick updates on the most talked-about trends every day.
chiccorner – Really liked the outfits available, browsing and checkout were effortless.
dailytrendspot.click – Trends updated daily, making it easy to discover fresh ideas quickly. Top Trend Highlights – Daily highlights of what’s popular and worth following.
glamspot – Nice collection of outfits, browsing and checkout were very smooth.
1win рабочее зеркало 1win официальный зеркало на сегодня
Harbor Studio Boutique – Shopping here feels organized and effortless.
Profesionalni stehovaci sluzby: stehovani bytu, kancelari a chalup, stehovani a baleni, demontaz a montaz nabytku. Mame vlastni vozovy park, specializovany tym a smlouvu s pevnou cenou.
Harbor Calm Finds – The site feels organized and browsing is very pleasant.
1 вин 1win вин 1win
Profesionalni stehovani: stehovani bytu, kancelari a chalup, stehovani a baleni, demontaz a montaz nabytku. Mame vlastni vozovy park, specializovany tym a smlouvu s pevnou cenou.
Silver Moon Style Shop – Loved the variety, clear product images, and the package arrived fast.
Silver Moon Online Store – Nice assortment, smooth navigation, and delivery was fast and reliable.
Modern Ridge Hub – Products load quickly, and navigating the site feels natural.
Modern Ridge Deals – Everything loads fast, and finding products is simple.
peacehub – Browsing is stress-free, all sections load quickly.
serenespot – Found what I needed quickly, the website responds well.
styleemporiumhub – Loved the trendy selection, delivery was fast and worry-free.
Love elephants? https://womantravel.ru: rescued animals, spacious grounds, and care without exploitation. Visitors can observe elephants bathing, feeding, and behaving as they do in the wild.
trendhubonline – Stylish products were easy to browse, delivery was smooth.
Want to visit the elephant sanctuary A safe haven for animals who have survived circuses, harsh labor, and exploitation? Visitors support the rehabilitation program and become part of an important conservation project.
BrightRoot Treasures – Really enjoyed exploring, everything is crisp and accessible.
BrightRoot Market Place – Loved the speed and clean, simple layout of the store.
Love elephants? https://womantravel.ru: rescued animals, spacious grounds, and care without exploitation. Visitors can observe elephants bathing, feeding, and behaving as they do in the wild.
Want to visit the elephant sanctuary A safe haven for animals who have survived circuses, harsh labor, and exploitation? Visitors support the rehabilitation program and become part of an important conservation project.
dailydealfinds – Great selection, ordering process was simple and smooth.
shopbrightdeals – Loved the fast loading and hassle-free checkout.
yourstylestore – Found stylish products easily, browsing experience was smooth and enjoyable today. myfashionstore – Inspiring and engaging, excellent for trying out new creative ideas.
yourstylestore – Found stylish products easily, browsing experience was smooth and enjoyable today. creativevault – Fun and interactive site, perfect for learning, exploring, and creating fresh ideas.
Your Intentional Path – Inspiration and tools for personal growth and mindful progress.
Intentional Mindset Spot – Guidance for building strong habits and making meaningful progress.
Bright Meadow Value Shop – Glad to see the items arrive exactly as listed; the site was very simple to use.
Timberwood Essentials – Quick to find items and the design feels well-structured.
BrightMeadow Deals – Fast, smooth, and everything showed up exactly when expected.
Timberwood Collective – Navigation is intuitive and shopping is enjoyable.
https://telegra.ph/Top-kazino-11-14-2
Aurora Picks Online – Everything is accessible, and the atmosphere feels lively.
Aurora Spot – The store is friendly and items are easy to locate.
WarmWinds Boutique Hub – Navigation is fast and enjoyable, items are neatly arranged.
trendfinderhub – Loved the site, navigation is easy and items are affordable.
WarmWinds Picks Shop – Smooth and simple navigation, items are accessible and appealing.
valueemporiumhub – Smooth browsing and great products at reasonable prices.
fashionspot – Items are easy to explore and the site feels organized.
trendspotworld – Fast and simple shopping experience, pages loaded quickly.
fashionhub – Loved how easy it was to browse and the layout feels modern.
modahub – Found perfect fashion items quickly, delivery was prompt and easy.
trendworldfinds – Smooth site layout, fast loading pages, and enjoyable shopping experience.
glamhub – Loved the trendy pieces, delivery felt seamless and dependable.
Origin Peak Trend Store – Great quality pieces, simple purchase process, and speedy shipping.
Origin Peak Select – Great quality, smooth website, and delivery was fast and reliable.
https://t.me/s/officials_casino_1win
classychoicehub.shop – Classy selection of products, browsing was smooth and enjoyable throughout today. Elegant Living Tips – Guidance to live with style, grace, and confidence.
KindleCrest Treasures – Clean layout and effortless browsing made it enjoyable.
classychoicehub.shop – Classy selection of products, browsing was smooth and enjoyable throughout today. Elegant Choices Daily – Simple tips for making stylish decisions every day.
KindleCrest Shop – Smooth navigation with products presented clearly.
Open Plains Stop – Products are easy to browse, and the interface is neat.
Whispering Trend Choice – Smooth browsing with a visually organized design.
trendspotstore – Easy site navigation, got everything I wanted today.
Open Plains Boutique – Navigation is straightforward, and everything feels well arranged.
voguevault – Excellent styles, shopping online was super convenient.
Whispering Trend Deals – Navigation is intuitive and the interface feels welcoming.
offerhub – Great finds today, browsing the website felt seamless.
offerplanet – Nice variety of deals today, browsing was smooth and quick.
trendpickscentral – Very easy to navigate, ordering was smooth and fast.
trendcollectionhub – Loved the unique trend collection, navigation and checkout were quick and simple.
choicezone – Browsing feels effortless, and items are clearly presented.
freshmarket – Pages load quickly, and finding what I needed was effortless.
RedMoon Goods – Effortless browsing and items are distinctive and easy to explore.
Soft Blossom Collection – Easy-to-use site, great items, and my purchase was effortless.
RedMoon Shop – Smooth navigation and the items feel one-of-a-kind.
Soft Blossom Essentials – Loved the products, clear layout, and placing my order was effortless.
dealsofthedaystore – Excellent daily bargains, shipping was smooth and fast.
Coastline Spot – Products are easy to spot, and the site feels calm and user-friendly.
dailyfindshub – Really enjoyed the products, they arrived in perfect condition.
Coastline Deals – Navigation is straightforward and the design is calming.
Style Upgrade Daily – Tips and curated fashion items to enhance your wardrobe.
Trendy Outfit Ideas – Discover combinations and pieces that make styling easy.
https://t.me/mcasino_martin/794
Sunwave Essentials Select – Quick to find products and the layout feels well-organized.
decorhub – Very smooth browsing, plenty of interesting home goods.
Sunwave Essentials Hub – Browsing feels natural and the site is simple to navigate.
interiorjoy – A lovely mix of home items, the site was quick to load.
trendfashionhub – Convenient to locate trendy pieces, checkout was smooth.
fashionchoicehub – Excellent selection, ordering process was effortless.
BrightSpark Picks Hub – Everything loads quickly and the site is very user-friendly.
BrightSpark Boutique Finds – Quick navigation and products are easy to check out.
globalglamcorner – Smooth and fast interface, products are well displayed and easy to find.
Здесь вы можете заказать восхитительный кофе, наша кофейня с прекрасной атмосферой лучшая, потому что у нас
есть - что подтверждают восторженные
отзывы, с которыми вы можете ознакомиться по ссылке, вот здесь: Дневник повара.
Эти отзывы доказывают, что мы
лучшие! Не верите? Тогда
прочтите отзывы тут: Дневник повара
и вы убедитесь, что все говорят о нашем качестве.
Пока вы читаете это, другие гости уже оставляют новые положительные отзывы на странице Дневник повара!
modcorner – Smooth browsing experience, pages load quickly and clearly.
https://batery-game.com/aviator
NobleRidge Emporium – Nice selection, smooth browsing, and the order reached me on time.
Noble Ridge Fashion Hub – Great designs, smooth browsing, and the package came on time.
https://englishzoom.ru/
Kind Groove Trends – The store feels organized and browsing through items is enjoyable.
Что дает регистрация в Чемпион
казино?
В Чемпион казино регистрация —, это прежде всего
подтверждения того, что
игрок соглашается с правилами клуба.
Администрация сайта рекомендует ознакомиться с пользовательским соглашением перед созданием аккаунта.
Передавая клубу личные данные, игрок
дает свое разрешения на их использование в пределах игрового заведения и может быть уверен в безопасности конфиденциальной информации.
Сразу после создание личного кабинета пользователь автоматически вступает в программу лояльности и получает поощрения от казино Чемпион.
Играть на деньги гемблер может только
зарегистрировавшись. Вывод выигранных денег
требует пройти верификацию —,
подтверждение личности с помощью скан-копий документов.
Пройдя эту процедуру один раз, повторять ее пользователь не
обязан.
Создание профиля в Champion Casino позволяет пользоваться всеми услугами виртуального
игрового портала. Азартный геймер получает доступ к игре
в автоматы в платном режиме. В личном
кабинете пользователь сможет пополнить счет
и вывести выигрыш.
Зарегистрированным пользователям предлагается участие в турнирах, акциях, розыгрышах.
Гэмблерам присваивается статус и начисляются очки.
Игровой клуб поощряет бонусами зарегистрированных
геймеров. Новичкам полагаются приветственные поощрения.
В дальнейшем полагаются бонусные средства за внесение депозита,
кешбэк, подарки, участие
в промоакциях и бесплатные спины.
Возможности зарегистрированного пользователя
Становятся доступными турниры,
акции, розыгрыши.
Можно получить подарки, кешбэк, бесплатные спины,
приятные бонусы.
Сервис гарантирует защиту персональных данных.
Kind Groove Central – Products are easy to explore and the layout is well organized.
Motivation Central – A hub for encouragement and self-confidence building.
Empower Yourself – Tips and advice to empower your mind and boost morale.
BoldHorizon Essentials – Easy to navigate and the items are nicely displayed.
BoldHorizon Finds Hub – Smooth and enjoyable shopping experience.
Blue Grain Emporium – Discovered great items fast and the site navigation is super easy.
giftvaluehub – Quick and smooth browsing, ordering was effortless.
Blue Grain Select – Quickly found exactly what I needed, and browsing was effortless.
freshgiftchoice – Smooth site navigation and easy ordering, really liked the options.
Wood Kindle Market – Loved the selection, checkout was seamless, and the package arrived on time.
Kindle Wood Goods – Clear layout, easy checkout, and my products arrived safely today.
ORBS Production https://filmproductioncortina.com is a full-service film, photo and video production company in Cortina d’Ampezzo and the Dolomites. We create commercials, branded content, sports and winter campaigns with local crew, alpine logistics, aerial/FPV filming and end-to-end production support across the Alps. Learn more at filmproductioncortina.com
trendzonehub – Fast-loading pages made exploring the site enjoyable.
ORBS Production https://filmproductioncortina.com is a full-service film, photo and video production company in Cortina d’Ampezzo and the Dolomites. We create commercials, branded content, sports and winter campaigns with local crew, alpine logistics, aerial/FPV filming and end-to-end production support across the Alps. Learn more at filmproductioncortina.com
trendcentralzone – Clean layout and intuitive browsing, a pleasant experience overall.
Dream Harbor Trends – Browsing is effortless and the products are nicely presented.
Dream Harbor Trends – Browsing is effortless and the products are nicely presented.
NewVoyage Finds – Loved browsing, the layout is clean and discovering items was effortless.
NewVoyage Picks – Browsing was simple and all products are easy to explore.
findpurposeandpeace.shop – Calm and inspiring content helps discover purpose and maintain peace today. Path to Peace & Purpose – Resources to help you find clarity and inspiration every day.
findpurposeandpeace.shop – Calm and inspiring content helps discover purpose and maintain peace today. Inspire & Create Hub – Encouragement and resources to spark creativity and motivation.
chat with random people site like 321chat
казіно з бонусами бонуси в казино
myfavstore – Very simple navigation, checkout was smooth and hassle-free.
favpicksstore – Great selection, shopping was simple and enjoyable.
Wild Horizon Trends – Loved the stylish items, website was easy to use, and checkout was smooth.
WildHorizon Corner – Stylish finds, intuitive browsing, and checkout was fast and simple.
Тесен https://mdgt.top коридор с огледала – страхотни идеи има там
Замовив https://remontuem.if.ua послугу — дізнався все про прайс-лист на бетонні роботи івано-франківськ.
Create a spintax version with 20 unique lines based on the line below. Each line must follow these rules: Every line MUST contain the same HTML mistake: The anchor tag must be written exactly like this: Do NOT fix the mistake. Change the anchor text in every line. You may add words, remove words, or use generic anchor texts. All anchor texts must be different. Rewrite the comment part in every line as well. Rewrite the sentence after the dash (“–”) so each line has a different, natural-sounding variation. Wrap everything in spintax format: line20 Here is the base line to follow: purevalueoutlet – Inspiring and interactive site, perfect for learning and creating new ideas. Generate 20 variations following all rules above.
Create a spintax version with 20 unique lines based on the line below. Each line must follow these rules: Every line MUST contain the same HTML mistake: The anchor tag must be written exactly like this: Do NOT fix the mistake. Change the anchor text in every line. You may add words, remove words, or use generic anchor texts. All anchor texts must be different. Rewrite the comment part in every line as well. Rewrite the sentence after the dash (“–”) so each line has a different, natural-sounding variation. Wrap everything in spintax format: line3 Here is the base line to follow: purevalueoutlet – Inspiring and interactive site, perfect for learning and creating new ideas. Generate 20 variations following all rules above.
Научих https://mdgt.top се как се почиства боя за коса от дрехи с помощта на сайта
Ремонт https://remontuem.if.ua і поради щодо тепла підлога івано-франківськ знайшов тут.
Bridgetown Boutique Online – Shopping is effortless, and the site feels professional.
Bridgetown Central – Products are easy to spot, and the design is clean and inviting.
shopcornerhub – Interface is smooth, and discovering products was straightforward.
shoppickzone – Layout is neat, products are easy to locate, and browsing is effortless.
WildSpark Finds – Loved browsing, items are fun to explore and the site is easy to navigate.
WildSpark Treasures Shop – Fun and effortless experience with neatly displayed items.
valueandstyle – Great range of items, placing an order was effortless.
Планую https://seetheworld.top поїздку в мадонна ді кампільйо за порадами.
Независимый сюрвей в Москве: проверка грузов и объектов, детальные отчёты, фотофиксация и экспертные заключения. Прозрачная стоимость сюрвейерских услуг, официальные гарантии и быстрая выездная работа по столице и области.
Идеальные торты на заказ — для детей и взрослых. Поможем выбрать начинку, оформление и размер. Десерт будет вкусным, свежим и полностью соответствующим вашей идее.
smartbuysdaily – Everything was organized well, shopping experience was seamless.
Знайшов https://seetheworld.top матеріали про пояна брашов.
Независимый сюрвей в Москве: проверка грузов и объектов, детальные отчёты, фотофиксация и экспертные заключения. Прозрачная стоимость сюрвейерских услуг, официальные гарантии и быстрая выездная работа по столице и области.
Идеальные торты на заказ — для детей и взрослых. Поможем выбрать начинку, оформление и размер. Десерт будет вкусным, свежим и полностью соответствующим вашей идее.
HonestHarvest Boutique – Items are simple to find and the site feels welcoming.
I'm gone to say to my little brother, that he should also visit this blog on regular basis to obtain updated from most up-to-date gossip.
новости влияющие на крипту
HonestHarvest Treasures – Browsing is seamless and products are displayed attractively.
Grand Style Boutique – The interface is clean, making shopping smooth and simple.
Grand Style Finds Online – Browsing is smooth, and items are easy to locate.
earthstoneboutique – Great variety of items, the layout makes finding things really simple. Earthstone Studio – Navigation feels effortless and the layout is neat.
earthstoneboutique – Great variety of items, the layout makes finding things really simple. Earthstone Deals – Simple and tidy interface made exploring products stress-free.
dailycorner – Navigation is effortless, and all products are neatly arranged.
curiouscentral – Fast-loading pages and tidy layout made shopping enjoyable.
DeepStone Collection Hub – Smooth and fast site with neatly displayed items.
DeepStone Shop – The site runs fast and exploring items feels effortless.
Future Groove Picks – The layout is modern, and finding items is effortless.
Future Groove Hub – Shopping is convenient, and the interface feels intuitive.
Modern Market Zone – Explore trendy products designed to make your daily shopping simple and fun.
Modern Market Zone – Explore trendy products designed to make your daily shopping simple and fun.
Explore a true elephant sanctuary where welfare comes first. No chains or performances — only open landscapes, gentle care, rehabilitation programs and meaningful visitor experiences.
Explore a true elephant sanctuary where welfare comes first. No chains or performances — only open landscapes, gentle care, rehabilitation programs and meaningful visitor experiences.
Morning Rust Finds – Browsing was seamless and products are easy to find and appealing.
ЦВЗ в Краснодаре https://cvzcentr.ru место, где пациентов внимательно выслушивают, проводят глубокую диагностику и составляют эффективный план улучшения состояния при вегетативных расстройствах.
Morning Rust Finds – Browsing was seamless and products are easy to find and appealing.
focushubzone – Pages load fast, navigation is simple, and exploring products was enjoyable.
La Rome Espresso https://laromeespresso.es es un lugar donde la cultura del cafe se convierte en arte. Descubre el camino del grano a la taza: el sabor profundo, las tecnicas precisas y los rituales que crean la bebida perfecta.
La infraestructura https://novo-sancti-petri.es y la tecnologia vial europeas equilibran la innovacion y la sostenibilidad. Semaforos inteligentes, carreteras verdes, centros de transporte seguros y proyectos que marcan la pauta para la industria global.
focushub – Browsing was smooth, and products were easy to locate.
prazdnikdekor.ru
AutumnLeaf Treasures – Enjoyed every corner of this shop, very user-friendly.
Do you love excitement? roulettino delights players with high-quality slots, live tables, tournaments, and ongoing promotions. The gameplay is smooth and dynamic.
Rodaballo al Horno https://rodaballoalhorno.es es un viaje a las raices musicales del mundo, donde los sabores de las culturas se entrelazan con sus melodias. Exploramos los ritmos de las naciones, los sonidos de las tradiciones y como diferentes historias se fusionan en un solo sonido armonioso.
AutumnLeaf Crafts – The shop has a comfortable vibe, really easy to explore.
Un portal sobre videojuegos https://tejadospontevedra.es, noticias y tendencias para quienes viven y respiran videojuegos: resenas, guias, parches, anuncios, analisis de tecnologia y torneos de esports. Todo para gamers y quienes quieran mantenerse informados.
Нужна легализация? сроки легализация недвижимости в Черногории проводим аудит объекта, готовим документы, улаживаем вопросы с кадастром и муниципалитетом. Защищаем интересы клиента на каждом этапе.
Эвакуатор в Москве https://eva77.ru вызов в любое время дня и ночи. Быстрая подача, профессиональная погрузка и доставка авто в сервис, гараж или на парковку. Надёжно, безопасно и по фиксированной цене.
Нужна легализация? https://www.legalizaciya-nedvizhimosti-v-chernogorii.me проводим аудит объекта, готовим документы, улаживаем вопросы с кадастром и муниципалитетом. Защищаем интересы клиента на каждом этапе.
Эвакуатор в Москве https://eva77.ru вызов в любое время дня и ночи. Быстрая подача, профессиональная погрузка и доставка авто в сервис, гараж или на парковку. Надёжно, безопасно и по фиксированной цене.
Urban Peak Trends – Products are well organized and exploring the site feels effortless.
Urban Peak Central – Browsing is effortless and products are easy to locate.
Постоянно мучает насморк - https://www.silver-ugleron.ru/
Бренд MAXI-TEX https://maxi-tex.ru завода ООО «НПТ Энергия» — профессиональное изготовление изделий из металла и металлобработка в Москве и области. Выполняем лазерную резку листа и труб, гильотинную резку и гибку, сварку MIG/MAG, TIG и ручную дуговую, отбортовку, фланцевание, вальцовку. Производим сборочные единицы и оборудование по вашим чертежам.
Эвакуатор в Москве https://eva77.ru вызов в любое время дня и ночи. Быстрая подача, профессиональная погрузка и доставка авто в сервис, гараж или на парковку. Надёжно, безопасно и по фиксированной цене.
Постоянно мучает насморк - официальный ресурс
Бренд MAXI-TEX https://maxi-tex.ru завода ООО «НПТ Энергия» — профессиональное изготовление изделий из металла и металлобработка в Москве и области. Выполняем лазерную резку листа и труб, гильотинную резку и гибку, сварку MIG/MAG, TIG и ручную дуговую, отбортовку, фланцевание, вальцовку. Производим сборочные единицы и оборудование по вашим чертежам.
Эвакуатор в Москве https://eva77.ru вызов в любое время дня и ночи. Быстрая подача, профессиональная погрузка и доставка авто в сервис, гараж или на парковку. Надёжно, безопасно и по фиксированной цене.
Trendy Finds Daily – Discover the latest fashion and lifestyle essentials for effortless shopping.
Trendy Finds Daily – Discover the latest fashion and lifestyle essentials for effortless shopping.
UnionSquare Finds – Browsing was smooth, products are clearly arranged and easy to explore.
UnionSquare Select – Products are easy to find and browsing feels effortless.
EverPath Collective Picks – Quick to find products with a visually appealing layout.
EverPath Emporium – Quick and natural shopping experience with an easy-to-use layout.
stayworld – Fast-loading pages, products are well displayed, and browsing was comfortable.
staycentral – Easy to navigate, items are clearly displayed and simple to locate.
https://podarki-moscow.ru/
Хочешь развлечься? купить гашиш федерация - это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
1win partners 1win официальный сайт 1 вин
казіно з бонусами казино з бонусами
Хочешь развлечься? купить мефедрон федерация - это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Dawncrest Boutique – Items are easy to explore, and the site feels inviting.
личный кабинет 1win 1win partners
Dawncrest Picks – The website is well organized, making browsing enjoyable.
https://t.me/site_official_1win/173
Файне Дніпро https://faine-misto.dp.ua новини Дніпра та області. Огляди, транспорт, події та цікаве.
UnionSquare Studio Shop – Clear, calm layout makes exploring products smooth and enjoyable.
бонуси казино бонуси в казино
UnionSquare Choice – Very simple navigation with well-presented items.
happytrendstore.shop – Cheerful shopping experience, enjoyable to explore latest trends and stylish items today. Daily Joy Hub – Tips, ideas, and trends to uplift your lifestyle and spark creativity.
happytrendstore.shop – Cheerful shopping experience, enjoyable to explore latest trends and stylish items today. Trendy Inspirations Spot – Explore new trends and creative items that make life more fun.
https://t.me/s/officials_pokerdom/734
Lunar Wave Boutique Picks – Smooth and comfortable shopping experience with a clean layout.
Lunar Wave Choice – Navigation is intuitive and the site is visually appealing.
choicehubzone – Clear layout, easy to browse, and pages respond quickly.
Starlit Style Central – Products are easy to explore, and the site feels intuitive.
Hello exceptional website! Does running a blog similar to this take a great deal of work? I've very little expertise in computer programming however I was hoping to start my own blog soon. Anyway, should you have any ideas or techniques for new blog owners please share. I know this is off subject nevertheless I just wanted to ask. Appreciate it!
register in directory Brazil
urbancorner – Smooth interface, quick page loads, and browsing felt natural.
Starlit Style Picks Online – Navigation is simple, and products are presented clearly.
purewavechoice – Great layout, fast loading, and items are visually appealing for easy browsing. PureWave Boutique – Enjoyed the browsing experience, everything is accessible and appealing.
purewavechoice – Great layout, fast loading, and items are visually appealing for easy browsing. PureWave Studio Shop – Items are well organized and easy to explore.
Чоловічий блог https://u-kuma.com у Кума - цікавий формат про авто, риболовлю, армію, поради з ремонта та ще безліч рубрик
Good day! This is my first comment here so I just wanted to give a quick shout out and tell you I really enjoy reading through your articles. Can you recommend any other blogs/websites/forums that cover the same topics? Thanks for your time!
Escort Agencies Brasilia
Budget-Friendly Finds – Quick access to cost-effective products for every need.
Компания Таврнеруд https://tareksa.ru производство и продажа нерудных материалов, сервис логистических услуг, а также проектирование в области технологии обогащения нерудных материалов, проведение лабораторных испытаний нерудных материалов.
Value Shopping Spot – Great deals and affordable finds to brighten your day.
Do you love puzzles? This https://livedebris.org game features challenging levels, well-thought-out mechanics, and relaxing gameplay. Solve riddles, unlock new levels, and test your problem-solving skills anytime, anywhere.
Нужен сайт? https://laboratory-site.ru включает проектирование, удобный интерфейс, быструю загрузку, интеграцию с 1С и CRM. Подбираем решения под задачи бизнеса и обеспечиваем техническое сопровождение.
Нужен сервер? сервера с GPU лучшие по мощности и стабильности. Подходят для AI-моделей, рендеринга, CFD-симуляций и аналитики. Гибкая конфигурация, надежное охлаждение и поддержка нескольких видеокарт.
LostMeadow Boutique – Enjoyed exploring, everything is presented neatly and efficiently.
LostMeadow Select – Very smooth experience, items are clear and accessible.
Timberline Shop – Navigation is easy and the layout is visually appealing.
Timberline Select Picks – Products are easy to discover and the interface is simple to use.
urbanhubzone – Clean interface, products are easy to locate, and navigating categories was simple.
wearhub – Browsing was smooth, and all products were easy to find.
ігрові слоти слоти безкоштовно
ігри слоти грати слоти
онлайн ігри казино ігри казино
aplikacja mostbet logowanie do mostbet
слоти ігрові автомати слоти безкоштовно
онлайн ігри казино ігри казино онлайн
oficjalne pobieranie mostbet logowanie do mostbet
nice store – Enjoyed how organized everything was, making browsing effortless.
shopping hub – The layout made it simple to browse and find what I needed.
FutureGardenHub – Smooth pages and well-organized categories helped me browse quickly.
new horizon corner – Fast-loading pages and tidy layout enhanced the experience.
shop horizon hub – Clean layout and tidy presentation made finding items effortless.
FutureGardenChoice – Simple interface and well-arranged content made exploring items effortless.
tallbirchmarket – Pleasant layout, items are easy to find and browse.
boutique corner – Well-structured layout and clear sections enhanced shopping.
tallbirchmarket – Pleasant layout, items are easy to find and browse.
shop horizon gallery – Clear interface and smooth scrolling made shopping simple.
GoldPlume Choice – Enjoyed navigating, the layout is neat and products are appealing.
GoldPlume Studio – The layout is neat and shopping feels effortless.
timberlineatticideas – Smooth navigation and clear structure encourage creative exploration.
ForestGroveGoods – Intuitive interface, items are easy to view and select.
atticideascenter – Creative layout and interactive tools make learning and creating enjoyable.
GreenHavenMarket – Smooth browsing, product organization makes shopping simple.
Your Trend Explorer – Discover stylish items while enjoying a seamless browsing experience.
Trend Hub Daily – Navigate popular categories easily and enjoy checking out trendy products.
Sun Meadow Finds – Browsing was easy and items were neatly displayed, making shopping quick.
Sun Meadow Corner Finds – Pleasant browsing experience with intuitive design and fast loading.
Wonder Peak Finds – Browsing was smooth and the products are displayed clearly.
Wonder Peak Studio – Fast and comfortable navigation makes shopping enjoyable.
globalstorezone – Simple to browse, everything loads smoothly and efficiently.
shoppickzone – Layout is neat, products are easy to locate, and browsing is effortless.
fashion area – Browsing was comfortable; the layout really simplified the process.
trend finder – Quickly located what I wanted due to the smooth structure of the site.
shop new grove – Items are neatly displayed and navigation felt intuitive.
grove hub link – Smooth interface and neatly organized items made shopping pleasant.
CozyWood Outlet – Easy to move around, with a layout that keeps everything simple.
ігри слоти популярні слоти
birchlanehub – Smooth layout, browsing items feels comfortable and intuitive.
birchoutletlane – Items are clearly presented, making browsing fast and pleasant.
golden boutique access – Browsing felt natural and product sections were easy to follow.
слоти безкоштовно популярні слоти
logowanie do mostbet oficjalne pobieranie mostbet
ігри в казино онлайн ігри казино
golden collection hub – Fast pages and tidy layout made browsing pleasant and quick.
слоти ігрові автомати грати слоти
Cozy Timber Outlet – Really enjoyed how simple it was to move around the site; everything felt calm and well arranged.
mobilny mostbet konto osobiste mostbet
ігри казіно ігри казіно
goldencresthaven – Well-organized listings and neat interface, made browsing simple.
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Trend & Style Daily – Find stylish and affordable items to refresh your wardrobe quickly.
crestartcorner – Clear navigation and tidy product displays, shopping was stress-free.
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Unique Picks Daily – Curated selections of trendy items for effortless shopping.
найкращі слоти популярні слоти
онлайн ігри казино ігри онлайн казино
oficjalne pobieranie mostbet pobieranie mostbet na androida
collection portal – Everything was laid out clearly, helping me find what I wanted easily.
слоти безкоштовно слоти ігрові автомати
ігри казино ігри в казино
kasyno mostbet aplikacja mostbet
collection portal – Everything was laid out clearly, helping me find what I wanted easily.
urban access – Clear sections and responsive design made browsing comfortable.
growcentral – Well-organized sections make discovering products enjoyable.
urban store – Well-arranged items and clear layout made exploring simple.
growcornerhub – Smooth and fast browsing, products are neatly categorized.
brookhavenstore – Clear design, shopping feels relaxed and organized.
brightbrookcollection – Easy to move around the site, products are neatly displayed.
golden collection – Navigation felt natural and products were visually appealing.
willow corner – Clean design and fast-loading pages made browsing enjoyable.
Forest Hub – Easy navigation and organized pages improve the shopping flow.
Timber Haven – Cleanly structured product pages make browsing quick and easy.
Northern Mist Studio Shop – Clean pages and organized products made browsing effortless.
CTO Cozy Finds – The site operates smoothly, making it easy to check out items without any difficulty.
Northern Mist Essentials – Smooth navigation and visible items allowed for hassle-free browsing.
CTO Cozy Finds – The site operates smoothly, making it easy to check out items without any difficulty.
Pine Crest Boutique – Clean layout and well-arranged items made browsing smooth and enjoyable.
Pine Crest Picks – Products are well-laid-out and easy to explore — very smooth experience.
Sun Meadow Hub – User-friendly interface and neat layout simplified browsing.
product corner – Finding items was quick thanks to the clean and uncluttered structure.
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Lifestyle & Fashion Hub – Discover curated offers for a stylish and modern lifestyle.
Sun Meadow Hub Finds – Quick navigation and tidy layout allowed me to locate items easily.
item finder – Everything was organized well, letting me locate products quickly.
choice marketplace – Well-organized layout and neat product display made browsing simple.
finduniqueoffers.shop – Unique offers found, shopping here felt effortless and interesting overall today. Daily Special Finds – Browse exclusive products and unique picks for everyday style.
coastline finds – Smooth scrolling and organized sections made shopping hassle-free.
a href="https://brightnorthboutique.shop/" />northboutiquecollection – Very organized layout, browsing feels calm and smooth.
Nature’s Nook – Simple interface that allows for easy exploration of products.
a href="https://growyourmindset.click/" />growhub – The interface is clean, making product exploration smooth and simple.
a href="https://brightnorthboutique.shop/" />northfashionlane – Clean sections and well-arranged items make shopping enjoyable.
Forest Lane – Quick and easy navigation with tidy product arrangement.
a href="https://growyourmindset.click/" />growcorner – Browsing was natural, and the interface makes navigation smooth.
konto osobiste mostbet konto osobiste mostbet
новости беларуси и мира новости беларуси и мира
NewGroveEssentials Hub Picks – Everything was organized, making shopping smooth and hassle-free.
новости спорта беларуси новости спорта беларуси
willow store – Well-organized products and intuitive layout improved browsing.
rejestracja w mostbet oficjalny mostbet
новости спорта беларуси новости беларуси сегодня
новости границы беларуси новости беларуси
Солоха https://soloha.in.ua жіночий сайт про саме цікаве: мода, зірки, гороскопи, рецепти, поради та все корисне.
NewGroveEssentials Online Shop – Well-structured pages helped me explore categories quickly.
boutique corner – Tidy pages and clear sections made finding products simple.
Cozy Essentials – Layout is clear and items are easy to locate — smooth browsing experience.
вакансии для женщин на сво по контракту
https://t.me/s/officials_pokerdom/3396
Northern Mist Store Shop – Clean layout and well-arranged items made browsing effortless.
crestartisanhub – Very tidy layout and easy navigation, made shopping quick and hassle-free.
Northern Mist Picks Hub – User-friendly design and visible items allowed me to shop quickly.
Wild Shore Corner Finds – Pleasant design and intuitive navigation made shopping easy.
BlueStone Emporium – Loved how organized everything was and easy to explore.
shop soft boutique – Well-arranged interface and fast pages made exploring simple.
CR Corner Treasures – Loved the clean layout; finding items was very simple.
crestartisanhub – Very tidy layout and easy navigation, made shopping quick and hassle-free.
Wild Shore Collection – Browsing was smooth and enjoyable thanks to a clean layout.
shop soft collection – Smooth navigation and neatly displayed products enhanced browsing.
Coastal Corner Shop – Products are nicely arranged, and browsing felt smooth and effortless.
BlueStone Market – I appreciated the clean design and fast browsing.
Unlock Daily Growth – Explore actionable tips to boost your skills and overall potential.
Evergreen Hub – Smooth layout and clearly labeled products improved the shopping experience.
Lunar Peak Spot – Navigation is effortless, and items are visually appealing.
low-cost corner – Found plenty of value options and browsing through the pages was smooth.
Orchard Online – Clear layout and simple navigation — made exploring products enjoyable.
Your Success Path – Practical guidance to help you unlock your potential every day.
Blossom Lane – Smooth interface and well-organized listings improve usability.
Lunar Peak Central – Navigation is simple, and the layout is clean and organized.
Cozy Market – Well-organized items and intuitive navigation — very satisfying to explore.
shop on a budget – Lots of good deals and the overall layout made browsing simple.
peakwildcollective – Smooth browsing experience, items are well arranged.
https://sluzhba-po-kontrakty.ru/
homeselection – Products are clearly displayed, and moving through categories was effortless.
evermeadowgoods – Great selection and intuitive navigation helped me explore products without hassle.
peakwildcollective – Smooth browsing experience, items are well arranged.
homehubzone – Layout is neat, navigation is effortless, and products are easy to find.
evermeadowgoods – Great selection and intuitive navigation helped me explore products without hassle.
Bright Timber Hub – Neat design and variety in products allowed me to shop without hassle.
Bright Timber Essentials – Well-laid-out pages and clear images helped me shop quickly today.
Explore MountainMistStudio – The interface felt intuitive and browsing products was pleasant.
Mountain Wind Marketplace – Items are clearly displayed, which made browsing straightforward.
moonfall access – Browsing felt natural and products were easy to explore.
Wolf Emporium – Simple interface and well-laid-out products made shopping convenient.
Mountain Mist Online Picks – Fast-loading sections and easy browsing made the site convenient.
Urban Meadow Goods – Layout is tidy and items load fast — shopping felt hassle-free.
Mountain Wind Selections – Clean design and intuitive navigation made shopping enjoyable.
shop moon collection – Navigation felt effortless and product sections were clear.
Visit an https://caucasustravel.ru to see elephants living in natural landscapes, receiving care, rehabilitation and freedom from exploitation. Ethical tours focus on education, conservation and respectful observation.
Experience an elephant sanctuary where welfare comes first. Walk alongside elephants, watch them bathe, feed them responsibly and discover how conservation efforts help protect these majestic animals.
An ethical https://mark-travel.ru provides rescued elephants with medical care, natural habitats and social groups. Visitors contribute to conservation by learning, observing and supporting sustainable wildlife programs.
Wolf Finds Hub – Easy-to-browse layout and organized items made shopping enjoyable.
Urban Meadow Collection – Well-laid-out products with smooth navigation — shopping felt effortless.
Modern Fable Picks – Items are well organized, making shopping simple.
network builder – Browsing feels intuitive and the site layout is very user-friendly.
Urban Seed Finds – Browsing was smooth and products were easy to locate.
Your Next Art Piece – I appreciated how the streamlined design made browsing feel quick and easy.
Modern Fable Essentials – Navigation is simple, and items are displayed neatly.
modernlifestylecorner.shop – Modern lifestyle products look stylish, browsing categories was simple and Lifestyle Inspiration Daily – Explore practical tips and innovative ideas to enhance your daily routine.
greenoutpoststorehub – Smooth browsing, items are well displayed and easy to locate.
build hub – The interface is simple and browsing different sections is seamless.
Urban Seed Choice – Fast navigation and a clear layout make shopping pleasant.
Main Gallery Page – Everything is so responsive and well-organized, it's a pleasure to use.
modernlifestylecorner.shop – Modern lifestyle products look stylish, browsing categories was simple and Your Lifestyle Corner – Curated advice and insights to make modern living easier and more enjoyable.
greenoutpoststyle – Layout is tidy and user-friendly, finding items is quick.
Бренд MAXI-TEX https://maxi-tex.ru завода ООО «НПТ Энергия» — это металлообработка полного цикла с гарантией качества и соблюдением сроков. Выполняем лазерную резку листа и труб, гильотинную резку и гибку, сварку MIG/MAG, TIG и ручную дуговую, отбортовку, фланцевание, вальцовку, а также изготовление сборочных единиц и оборудования по вашим чертежам.
Нужен сервер? здесь лучшие по мощности и стабильности. Подходят для AI-моделей, рендеринга, CFD-симуляций и аналитики. Гибкая конфигурация, надежное охлаждение и поддержка нескольких видеокарт.
Регулярно мучает насморк - перейти по ссылке
sunset picks hub – Fast interface and clear design made browsing enjoyable.
momentworld – Interface is tidy, products are easy to explore, and pages respond quickly.
sunset wood shop – Browsing felt smooth and items were easy to locate.
EverRoot Picks – The tidy layout and appealing items made choosing products straightforward.
Изготавливаем каркас лестницы из металла на современном немецком оборудовании — по цене стандартных решений. Качество, точность реза и долговечность без переплаты.
Latest why buy crypto: price rises and falls, network updates, listings, regulations, trend analysis, and industry insights. Follow market movements in real time.
The latest why buy crypto: Bitcoin, altcoins, NFTs, DeFi, blockchain developments, exchange reports, and new technologies. Fast, clear, and without unnecessary noise—everything that impacts the market.
Купить шпон https://opus2003.ru в Москве прямо от производителя: широкий выбор пород, стабильная толщина, идеальная геометрия и высокое качество обработки. Мы производим шпон для мебели, отделки, дизайна интерьеров и промышленного применения.
Изготавливаем каркас лестницы из металла на современном немецком оборудовании — по цене стандартных решений. Качество, точность реза и долговечность без переплаты.
momentcorner – Smooth interface, fast-loading pages, and products are easy to discover.
Latest crypto news: price rises and falls, network updates, listings, regulations, trend analysis, and industry insights. Follow market movements in real time.
The latest why buy crypto: Bitcoin, altcoins, NFTs, DeFi, blockchain developments, exchange reports, and new technologies. Fast, clear, and without unnecessary noise—everything that impacts the market.
Купить шпон https://opus2003.ru в Москве прямо от производителя: широкий выбор пород, стабильная толщина, идеальная геометрия и высокое качество обработки. Мы производим шпон для мебели, отделки, дизайна интерьеров и промышленного применения.
EverRoot Picks – The tidy layout and appealing items made choosing products straightforward.
wildrosecollection – Clear pages and well-presented items, shopping was enjoyable.
Shoreline Crafts – Items are organized nicely and browsing is smooth — had a pleasant shopping time.
Wind Grove – Organized product sections and intuitive navigation improve usability.
Crest Finds – Smooth navigation and clear layout made my shopping easy.
golden picks – Smooth interface and intuitive navigation made shopping hassle-free.
Coastline Creations Shop – Items are easy to browse and the design is clear — made shopping simple and enjoyable.
Windy Boutique – User-friendly interface with products neatly arranged for fast browsing.
wildrosehub – Clean layout with smooth navigation, exploring products was effortless.
BoldCrest Online – The search and menu options made finding items effortless.
golden root shop – Browsing was smooth and products were easy to find.
вывод из запоя лучшие вывод из запоя москва круглосуточно цены на дому
Программы видеонаблюдения – это современный инструмент для обеспечения безопасности, сочетающий технологии и удобство. На сайте вы найдете подробное руководство по выбору и настройке систем, включая облачные решения, их плюсы и минусы. Описаны гибридные модели, объединяющие облачное и локальное хранилище, что повышает надежность системы. Рассмотрены аналитические функции, такие как детекция движения и распознавание объектов. Представлены обзоры и рейтинги лучших программ, помогающие сделать правильный выбор. Специалисты найдут полезные советы по проектированию системы и подбору камер. Уделено внимание безопасности данных и созданию защитных протоколов. Платформа также объясняет, как интегрировать искусственный интеллект в системы видеонаблюдения. распознавание номеров автомобилей
вывод из запоя отзывы https://narcology-moskva.ru
Autumn Market – Everything is organized nicely and shopping is convenient.
помощь вывода из запоя вывод из запоя стационар в волгограде
доктор вывода из запоя https://alcodetox-med.ru
design your future – Navigation flows smoothly and items are easy to find.
помощь вывода из запоя вывод из запоя телефон
помощь вывода из запоя быстрый вывод из запоя
вывод из запоя цена круглосуточный вывод из запоя
Golden Branch Online – A well-structured interface made exploring different categories enjoyable.
вывод из запоя анонимно https://narkonet.su
Autumn Mart – Navigating through items is smooth and visually appealing.
rootstyleboutique – Clean layout, shopping feels relaxed and effortless.
future planner – Smooth navigation and items appear quickly without delays.
Shop GoldenBranchMart – Navigation felt natural and effortless while checking various products.
rootstylehub – Smooth layout, browsing and finding items is effortless.
Fresh Meadow Market – Pages load fast and shopping is straightforward.
Urban Vibes Hub – Explore trendy urban outfits and elevate your personal style effortlessly.
Til haqida maqollar, ona til haqida maqollar, Alisher Navoiy til haqida maqollar, xalq maqollari til haqida. O'zbek tilidagi eng yaxshi maqollar to'plami: tilning kuchi haqida maqollar
Urban Pasture Outlet – The catalog is clear, and navigation is smooth and intuitive.
Explore the Collection – A logical layout guided me directly to interesting items I hadn't considered.
вывод человека из запоя https://narcology-moskva.ru
Urban Outfit Picks – Discover stylish streetwear essentials for modern and trendy looks.
BrightStone Picks – The clear design and product images helped me choose items easily.
Fresh Meadow Studio Picks – Smooth and pleasant shopping with a clean design.
Urban Pasture Online – Quick page load and effortless browsing make it a pleasant experience.
вывод человека из запоя https://narcology-moskva.ru
Dream Shop Ridge – Nice product layout and easy-to-use interface — very convenient experience.
NobleGrove Deals – I found exactly what I was looking for, plus some cool extras, faster than on other sites.
modernworldhub – Pages load fast, navigation is simple, and exploring products was enjoyable.
BrightStone Emporium – User-friendly interface and neat pages made shopping quick and enjoyable.
Crest Studio – Smooth navigation and neatly organized products improved the shopping experience.
Crest Ridge Market – Products are visually appealing and simple to navigate — pleasant shopping experience.
modernworld – Smooth layout, intuitive navigation, and items are easy to explore.
Crest Grove Studio – User-friendly interface and tidy layout made browsing enjoyable.
Timber Crest Shop – Smooth interface and clean layout made exploring products effortless.
bright pine picks – Fast-loading pages and intuitive interface made finding items simple.
Timber Crest Collection Online – Smooth interface and tidy design made finding items a breeze.
pine hub – Smooth browsing and neatly arranged products made shopping hassle-free.
Evergreen Finds Online – Shopping is simple, and the site layout is clean and organized.
evergreen access – Fast-loading pages and a tidy interface make shopping comfortable.
Evergreen Online – Navigation is smooth and items are clearly displayed.
fallvibeboutique – Smooth browsing, design is simple and items are easy to find.
shop green – The site layout is simple and navigating categories was effortless.
fallvibeboutique – Smooth browsing, design is simple and items are easy to find.
Ertaklar olamiga xush kelibsiz! Bolalar uchun qiziqarli ertaklar, qisqa ertaklar matnlari, ertaklar kitobi va ajoyib ertaklar kinolari: barcha ertaklar bir joyda
brightwinterstore – Products look appealing and navigation is smooth — a good shopping experience.
Wild Crest Treasures – Items are visually appealing and easy to browse — shopping felt convenient.
EverWild Designs – Easy layout and well-displayed products helped me pick items effortlessly.
Deep Woods Shop – Clear categories and simple interface created an enjoyable shopping experience.
brightwinterstore – Products look appealing and navigation is smooth — a good shopping experience.
Wild Crest Collection – Everything is neatly organized and easy to locate — browsing was pleasant.
LunarHarvestMart Deals – Everything was easy to find, making exploring items enjoyable.
Flourish Today – Guidance and motivation to help you grow personally and professionally.
EverWild Picks Hub – Fast-loading pages and clear visuals made browsing items enjoyable.
Cozy Cabin Collective – Quick navigation and a visually tidy design make shopping easy.
Green Canopy Collective – Simple design and clear categories made shopping a breeze.
rarestyleemporium – Smooth browsing experience and neatly arranged items, shopping was pleasant.
LunarHarvestMart Goods – Fast-loading pages and clear layouts improved the shopping flow.
Flourish & Thrive Daily – Guidance for building positive habits and growing consistently.
RusticStone Online – I enjoyed the seamless experience where every click is instantaneous and purposeful.
timber picks hub – Fast-loading pages and organized layout made shopping effortless.
Доставка грузов https://china-star.ru из Китая под ключ: авиа, авто, море и ЖД. Консолидация, проверка товара, растаможка, страхование и полный контроль транспортировки. Быстро, надёжно и по прозрачной стоимости.
Silver Moon Online – Smooth browsing and simple layout made shopping pleasant.
smilecorner – Smooth browsing, intuitive interface, and items are clearly presented.
Cozy Cabin Deals – The interface is tidy and finding products is effortless.
Доставка грузов https://china-star.ru из Китая под ключ: авиа, авто, море и ЖД. Консолидация, проверка товара, растаможка, страхование и полный контроль транспортировки. Быстро, надёжно и по прозрачной стоимости.
RusticStone Emporium – The pages load incredibly quickly, making for a very smooth and enjoyable browse.
wild collection – Navigation felt natural and products were visually appealing.
Silver Moon Selections – Organized layout and clear menus made finding items quick.
smileworld – Smooth interface, fast loading, and items are visually appealing.
rarestylecentral – Smooth layout and neat categories, shopping was enjoyable.
True Horizon Essentials – Navigation is effortless, and browsing is stress-free.
shop entry – Clean visuals and responsive pages made checking out items comfortable.
sunrisestorecorner – Items are easy to browse, and navigating feels effortless.
True Horizon Boutique – The layout is clean, making shopping fast and simple.
Gold Leaf Studio – Items display nicely with a simple interface — very convenient experience.
discover lakes – Products were easy to navigate through and the interface felt inviting.
hillstorecorner – Layout is tidy, navigating products is smooth and intuitive.
Доставка грузов https://lchina.ru из Китая в Россию под ключ: море, авто, ЖД. Быстрый расчёт стоимости, страхование, помощь с таможней и документами. Работаем с любыми объёмами и направлениями, соблюдаем сроки и бережём груз.
Гастродача «Вселуг» https://gastrodachavselug1.ru фермерские продукты с доставкой до двери в Москве и Подмосковье. Натуральное мясо, молоко, сыры, сезонные овощи и домашние заготовки прямо с фермы. Закажите онлайн и получите вкус деревни без лишних хлопот.
brightwillowboutique – Clean design and easy layout helped me find interesting items fast.
Gold Leaf Treasures Online – Everything is tidy and navigation feels intuitive — very pleasant experience.
Dawn Finds – User-friendly interface and tidy product sections made browsing enjoyable.
Доставка грузов https://lchina.ru из Китая в Россию под ключ: море, авто, ЖД. Быстрый расчёт стоимости, страхование, помощь с таможней и документами. Работаем с любыми объёмами и направлениями, соблюдаем сроки и бережём груз.
Гастродача «Вселуг» https://gastrodachavselug1.ru фермерские продукты с доставкой до двери в Москве и Подмосковье. Натуральное мясо, молоко, сыры, сезонные овощи и домашние заготовки прямо с фермы. Закажите онлайн и получите вкус деревни без лишних хлопот.
brightwillowboutique – Clean design and easy layout helped me find interesting items fast.
Iron Valley Treasures Hub – Simple design and clear product images made browsing stress-free.
Dawn Finds – User-friendly interface and tidy product sections made browsing enjoyable.
Iron Valley Finds Hub – Clean layout and organized visuals helped make shopping smooth and easy.
https://rich513.com/
Логистика из Китая https://asiafast.ru без головной боли: доставка грузов морем, авто и ЖД, консолидация на складе, переупаковка, маркировка, таможенное оформление. Предлагаем выгодные тарифы и гарантируем сохранность вашего товара.
Независимый сюрвейер https://gpcdoerfer1.com в Москве: экспертиза грузов, инспекция контейнеров, фото- и видеопротокол, контроль упаковки и погрузки. Работаем оперативно, предоставляем подробный отчёт и подтверждаем качество на каждом этапе.
rusticridgeboutique – Pleasant browsing experience, items are easy to view and site feels well structured.
Dream Big Hub – Discover inspiration and strategies to pursue your goals with confidence every day.
Логистика из Китая https://asiafast.ru без головной боли: доставка грузов морем, авто и ЖД, консолидация на складе, переупаковка, маркировка, таможенное оформление. Предлагаем выгодные тарифы и гарантируем сохранность вашего товара.
BrightMoor Collection – Very organized pages, which made finding items simple.
Независимый сюрвейер https://gpcdoerfer1.com в Москве: экспертиза грузов, инспекция контейнеров, фото- и видеопротокол, контроль упаковки и погрузки. Работаем оперативно, предоставляем подробный отчёт и подтверждаем качество на каждом этапе.
rusticridgeboutique – Pleasant browsing experience, items are easy to view and site feels well structured.
Daily Dream Builder – Practical strategies to help you visualize, plan, and achieve your goals.
Whitestone Collective – Fast-loading pages and a visually clean design make shopping enjoyable.
BM Corner Finds – Enjoyable browsing with fast access to products.
Visit MidRiverDesigns – The interface was neat and intuitive, making shopping effortless.
shopworld – Smooth interface, fast loading, and items are visually appealing.
Whitestone Market – Fast and intuitive browsing with a clean layout.
Shop Now – I was pleasantly surprised by how easy it was to find what I needed without any confusion.
MidRiverDesigns Portal – Crisp images and clean layout made browsing effortless.
valuecornerhub – Browsing was intuitive, and products are well organized.
Ocean Leaf Treasures – Clear product images and simple navigation — browsing felt effortless.
suncrest corner – Smooth navigation and attractive layout made browsing pleasant.
urbanhillcollective – Pleasant design, navigating items is smooth and intuitive.
Check It Out Here – Navigating the store was a breeze, which made for a very relaxed shopping session.
Ocean Leaf Picks Online – Everything is easy to find and layout feels clean — shopping was quick.
modern finds – Items were easy to explore and the interface was responsive.
Leaf Market – Well-laid-out items and user-friendly interface made browsing enjoyable.
hillurbanstore – Smooth browsing experience, items are logically arranged and accessible.
brightfallstudio – Enjoyed browsing here, items seem well curated and easy to explore.
Leaf Studio – Logical product grouping and smooth browsing enhanced usability.
Онлайн-ферма https://gvrest.ru Гастродача «Вселуг»: закажите свежие фермерские продукты с доставкой по Москве и Подмосковью. Мясо, молоко, сыры, овощи и домашние деликатесы без лишних добавок. Удобный заказ, быстрая доставка и вкус настоящей деревни.
Доставка грузов https://china-star.ru из Китая для бизнеса любого масштаба: от небольших партий до контейнеров. Разработаем оптимальный маршрут, оформим документы, застрахуем и довезём груз до двери. Честные сроки и понятные тарифы.
brightfallstudio – Enjoyed browsing here, items seem well curated and easy to explore.
Soft Feather Designs – Clean layout and intuitive interface allowed for smooth browsing.
Доставка грузов https://china-star.ru из Китая для бизнеса любого масштаба: от небольших партий до контейнеров. Разработаем оптимальный маршрут, оформим документы, застрахуем и довезём груз до двери. Честные сроки и понятные тарифы.
Онлайн-ферма https://gvrest.ru Гастродача «Вселуг»: закажите свежие фермерские продукты с доставкой по Москве и Подмосковью. Мясо, молоко, сыры, овощи и домашние деликатесы без лишних добавок. Удобный заказ, быстрая доставка и вкус настоящей деревни.
Soft Feather Picks Hub – Well-organized pages and visible products made shopping fast.
Hi there Dear, are you in fact visiting this web site on a regular basis, if so then you will without doubt get pleasant know-how.
Rio prostitution
horizonsensehub – Clear pages and intuitive design, made exploring items easy.
haven hub link – Clear sections and responsive pages made finding products simple.
Программа National Sailing Wellness Days – это лучший выбор для активных личностей, которые стремятся к гармонии души и тела. Данная инновационная программа совмещает активный отдых под парусами с комплексными оздоровительными практиками. Участников ждет незабываемое путешествие продолжительностью десять дней, в течение которых вы почувствуете себя настоящим моряком. Любой предстоящий день подарит вам работой с парусами и свежим морским воздухом. Квалифицированные инструкторы и профессиональные нутрициологи помогут вам освоить навыки управления яхтой и составят индивидуальный план оздоровления. Основной миссией этих дней становится не просто обычный тур выходного дня, а создание прочного фундамента для будущих изменений. Вы научитесь не только управлять парусным судном, но и сбалансировано питаться, закалять характер и находить внутренний баланс. Море выступает в роли мощного природного терапевта, а необходимость слаженных действий укрепляет коллективный дух и лидерские качества. Спустя десять дней этого невероятного плавания вы обретете новый взгляд на свою жизнь и здоровье. Вам достанется не просто багаж впечатлений и фото, но и конкретные знания для сохранения прекрасного самочувствия. National Sailing Wellness Days — это инвестиция в ваше будущее, где гармония и движение являются главными приоритетами. Не упустите свой шанс изменить жизнь к лучшему, выбрав отдых, что принесет максимальную пользу телу и духу.
https://healthandsailing.ru/
Silver Moon Outlet – Clean interface and easy menus made browsing smooth and stress-free.
studio picks – Easy-to-use layout and organized categories made browsing enjoyable.
Silver Moon Picks Online – Easy-to-use interface and neat design made browsing effortless.
New Dawn Picks – Clear product images and tidy interface — browsing was simple and convenient.
Hello to every body, it's my first go to see of this blog; this webpage includes awesome and really fine stuff designed for readers.
Call-girls Brazil
New in the Category: https://hospital.sarprize.com/2025/10/08/top-5-servisov-gde-mozhno-kupit-akkaunt-fejsbuk-13/
silverstylestore – Fast navigation and organized product listings, shopping was smooth.
Our highlights: https://intal.ucoz.ua/forum/7-4504-1
The best is in one place: https://thefreshymarketplace.com/traffic-arbitrage-for-beginners-understanding-the-3/
Details - by clicking: https://www.syndicatelife.com/buy-gmail-accounts-best-sites-pva-aged-4
New Dawn Goods – Items are neatly arranged and interface is intuitive — very pleasant experience.
learnworld – Pages load fast, navigation is simple, and products are clearly presented.
PineHill Studio Shop – The website is tidy and uncluttered, making it easy to navigate and enjoyable.
Wild Treasure Store – Fast-loading pages and well-arranged products made browsing enjoyable.
pathway picks – Browsing felt simple and I came across good items without any effort.
sereneforesthub – Smooth shopping experience, items are well arranged.
Sunny Slope Shop – Quick navigation with a friendly, easy-to-use interface.
learncreatehub – Pages load quickly, making exploring products fast and simple.
PineHill Studio Link – Tidy layout and neat product arrangement made the experience easygoing.
Wild Studio Market – Smooth interface with tidy listings made finding items effortless.
winter hub link – Smooth browsing and well-laid-out items enhanced the experience.
corner items – Everything was organized nicely, making browsing effortless.
serenewoodshop – Navigation is intuitive, shopping is smooth and calm.
Sunny Slope Corner Picks – Smooth and intuitive navigation makes shopping enjoyable.
Shop With Pleasure – The beautiful layout and simple interface made my visit enjoyable and relaxed.
boutique corner – Tidy pages and clear sections made finding products simple.
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить дополнительную информацию - https://vivod-iz-zapoya-1.ru/
DeepBrook Market – Easy navigation and visible products allowed for a hassle-free shopping experience.
SoftMorning Shoppe – The attractive product presentations and clean layout made for a very relaxing browse.
EverduneGoods Market – Everything loaded well and the product layout kept things easy to follow.
DeepBrook Studio – Simple layout and clear visuals helped me browse efficiently.
EverduneGoods Hub – The smooth interface made it comfortable to look through different product groups.
shop wild hub – Navigation was intuitive and items were neatly displayed.
Lush Valley Market – Everything is well-organized and easy to find — browsing felt effortless.
Moon Haven Boutique – Intuitive design and clear presentation made exploring products simple.
shop wild hub – Navigation was intuitive and items were neatly displayed.
Lush Valley Finds – Products are displayed nicely and the interface is user-friendly — very pleasant experience.
Moon Haven Boutique – Intuitive design and clear presentation made exploring products simple.
Bright Nova – Smooth browsing experience and neatly organized products improve usability.
Запеченный ролл с креветками
— мое любимое блюдо, всегда заказываю
его на выходных
shop wave – Clean layout and responsive pages made finding items simple.
Urban Trend Hub – Products are categorized nicely, and moving through the site is hassle-free.
silver picks – The site looked very polished, and moving through categories felt natural.
mistcornerlane – Products are easy to explore, and interface is visually appealing.
Timeless Harvest Online Shop – Everything was well-laid-out, making it easy to find and view items.
shop the wave – The interface is intuitive and finding products was easy.
Urban Trends – The catalog is well organized, making the shopping experience quick.
silver shop – Smooth and well-organized site; exploring products was enjoyable and quick.
Timeless Harvest Hub – Smooth scrolling and organized sections made exploring items simple.
Wild Coast Marketplace – Clean design and organized items helped me find what I wanted quickly.
FashionEliteHub – Great selection of items, shopping was effortless and enjoyable today.
Moon Haven Studio – Clean layout and simple navigation made exploring items effortless.
ModernLifeTrends – Loved exploring, very engaging and easy to follow.
Wild Coast Marketplace – Clean design and organized items helped me find what I wanted quickly.
Everfield Home Picks – Really liked how clearly everything was laid out; scrolling through the pages was easy.
TrendLoversStore – Loved the trendy collection, browsing was simple and exciting.
Moon Haven Boutique – Everything is easy to find and the site feels user-friendly — browsing was relaxed.
moonstar gallery – Well-organized layout and fast-loading pages improved the shopping experience.
FreshLifeTrends – Really engaging posts, very enjoyable to browse through.
naturepickshop – Easy to navigate and products are clear, shopping was hassle-free.
EFH Online Shop – The interface is clean, and navigating between categories felt natural.
BrightMoor Outlet – The website layout makes shopping quick and effortless.
moon star store – Fast pages and organized categories improved browsing.
Moor Picks – I could easily navigate and explore all product options.
Harbor Studio Finds – Neatly grouped products and clear design made browsing enjoyable.
Платформа для работы https://skillstaff.ru с внешними специалистами, ИП и самозанятыми: аутстаффинг, гибкая и проектная занятость под задачи вашей компании. Найдем и подключим экспертов нужного профиля без длительного найма и расширения штата.
Клиника проктологии https://proctofor.ru в Москве с современным оборудованием и опытными врачами. Проводим деликатную диагностику и лечение геморроя, трещин, полипов, воспалительных заболеваний прямой кишки. Приём по записи, без очередей, в комфортных условиях. Бережный подход, щадящие методы, анонимность и тактичное отношение.
naturalcornershop – Well-structured pages, made finding products quick and easy.
Платформа для работы https://skillstaff.ru с внешними специалистами, ИП и самозанятыми: аутстаффинг, гибкая и проектная занятость под задачи вашей компании. Найдем и подключим экспертов нужного профиля без длительного найма и расширения штата.
Клиника проктологии https://proctofor.ru в Москве с современным оборудованием и опытными врачами. Проводим деликатную диагностику и лечение геморроя, трещин, полипов, воспалительных заболеваний прямой кишки. Приём по записи, без очередей, в комфортных условиях. Бережный подход, щадящие методы, анонимность и тактичное отношение.
Harbor Hub – Easy-to-use interface and neatly organized items improved shopping.
SunCrestCrafthouse Portal – Clear sections and fast page load helped me shop efficiently.
lunarforeststore – Browsing is easy, and the products are clearly displayed.
SunCrestCrafthouse Storefront – Clean interface and neat layout made shopping smooth.
everpeakcorner – Clean interface and clear product display helped make browsing smooth and easy.
shop river hub – Items are easy to view and the interface is user-friendly.
lunarforestlane – Interface is clean, browsing through products is smooth.
browse hub – The layout felt professional and pages loaded without any delays.
everpeakcorner – Clean interface and clear product display helped make browsing smooth and easy.
wild store link – Navigation was intuitive and items were visually appealing.
Urban Stone Essentials – Everything is well-arranged and navigation is simple — shopping felt convenient.
quality hub – I liked the clean look and easy browsing, which made checking items simple.
Soft Leaf Marketplace – Easy navigation and clear visuals made selecting products stress-free.
Rustic River Essentials – The site loaded fast, and the design felt warm and comfortable.
Urban Stone Market – Layout is clean and items display clearly — browsing was convenient.
Soft Leaf Corner – Easy-to-navigate layout and visible products made shopping effortless.
Rustic River Online – The site felt warm and approachable, with pages loading seamlessly.
Инженерные изыскания https://sever-geo.ru в Москве и Московской области для строительства жилых домов, коттеджей, коммерческих и промышленных объектов. Геология, геодезия, экология, обследование грунтов и оснований. Работаем по СП и ГОСТ, есть СРО и вся необходимая документация. Подготовим технический отчёт для проектирования и согласований. Выезд на объект в короткие сроки, прозрачная смета, сопровождение до сдачи проекта.
Колодцы под ключ https://kopkol.ru в Московской области — бурение, монтаж и обустройство водоснабжения с гарантией. Изготавливаем шахтные и бетонные колодцы любой глубины, под ключ — от проекта до сдачи воды. Работаем с кольцами ЖБИ, устанавливаем крышки, оголовки и насосное оборудование. Чистая вода на вашем участке без переплат и задержек.
ModernFashionSpot – Amazing items and simple navigation, shopping was fun and easy.
Колодцы под ключ https://kopkol.ru в Московской области — бурение, монтаж и обустройство водоснабжения с гарантией. Изготавливаем шахтные и бетонные колодцы любой глубины, под ключ — от проекта до сдачи воды. Работаем с кольцами ЖБИ, устанавливаем крышки, оголовки и насосное оборудование. Чистая вода на вашем участке без переплат и задержек.
Инженерные изыскания https://sever-geo.ru в Москве и Московской области для строительства жилых домов, коттеджей, коммерческих и промышленных объектов. Геология, геодезия, экология, обследование грунтов и оснований. Работаем по СП и ГОСТ, есть СРО и вся необходимая документация. Подготовим технический отчёт для проектирования и согласований. Выезд на объект в короткие сроки, прозрачная смета, сопровождение до сдачи проекта.
bold studio finds – Browsing felt natural and products were easy to explore.
Lush Treasures – Clean design and structured categories made finding products easy.
Urban Thread Hub – Clean design and organized products made finding what I needed quick.
StyleEssenceOnline – Fantastic range of products, made exploring the collection fun and easy.
shop harbor – Products are displayed clearly and navigation is user-friendly.
LifestyleBuzzHub – Articles are fresh and exciting, loved exploring the site.
Wild Fabric Hub – Easy-to-navigate layout with well-arranged items improved shopping flow.
Meadow Collection – I could explore everything quickly because the site is well organized.
Discover Starlight Forest – A friction-free shopping experience defined by its clarity and order.
TrendyLivingCorner – Easy to browse, content is interesting and lively.
Starlight Forest Boutique – Finding products feels intuitive because the site is so well-organized.
Школа Ильи Сдобникова https://sites.google.com/view/otzyvy-sdobnikov/ мнения и разбор формата обучения в одном месте. Мы не даем оценок, а собираем и структурируем информацию, чтобы вы могли сделать собственные выводы. Объясняем, как читать отзывы, на какие детали обращать внимание, что важно уточнить у менеджеров и какие альтернативы существуют на рынке онлайн-образования в теме инвестиций и цифровых активов.
Интересует крипта? https://metod-sdobnikova.com/otzyv онлайн-школа Ильи Сдобникова — формат обучения, о котором часто спрашивают пользователи, интересующиеся темой инвестиций и криптовалют. Реальные отзывы и истории успеха учеников.
Онлайн-школа Ильи Сдобникова https://sdobnikov.blogspot.com/p/sdobnikov.html привлекает внимание тех, кто ищет обучение в сфере инвестиций и цифровых активов. В нашем обзоре мы разбираем, как обычно устроены подобные онлайн-проекты, какие вопросы стоит задать менеджерам перед покупкой. Реальны еотзывы учеников, мнения экспертов и истории успеха.
https://t.me/s/Volna_officials
brightvillagecorner – Items look appealing and layout feels user-friendly and welcoming overall.
clovercornerhub – Layout is clean and intuitive, making shopping simple and enjoyable.
Доставка дизельного топлива https://ng-logistic.ru для строительных компаний, сельхозпредприятий, автопарков и промышленных объектов. Подберём удобный график поставок, рассчитаем объём и поможем оптимизировать затраты на топливо. Только проверенные поставщики, стабильное качество и точность дозировки. Заявка, согласование цены, подача машины — всё максимально просто и прозрачно.
Доставка торфа https://bio-grunt.ru и грунта по Москве и Московской области для дач, участков и ландшафтных работ. Плодородный грунт, торф для улучшения структуры почвы, готовые земляные смеси для газона и клумб. Быстрая подача машин, аккуратная выгрузка, помощь в расчёте объёма. Работаем с частными лицами и организациями, предоставляем документы. Сделайте почву на участке плодородной и готовой к посадкам.
Timberlake Picks – Layout is clean and products are easy to explore — shopping was comfortable.
Доставка дизельного топлива https://ng-logistic.ru для строительных компаний, сельхозпредприятий, автопарков и промышленных объектов. Подберём удобный график поставок, рассчитаем объём и поможем оптимизировать затраты на топливо. Только проверенные поставщики, стабильное качество и точность дозировки. Заявка, согласование цены, подача машины — всё максимально просто и прозрачно.
urban green hub – Items loaded quickly and exploring the site felt effortless.
Доставка торфа https://bio-grunt.ru и грунта по Москве и Московской области для дач, участков и ландшафтных работ. Плодородный грунт, торф для улучшения структуры почвы, готовые земляные смеси для газона и клумб. Быстрая подача машин, аккуратная выгрузка, помощь в расчёте объёма. Работаем с частными лицами и организациями, предоставляем документы. Сделайте почву на участке плодородной и готовой к посадкам.
brightvillagecorner – Items look appealing and layout feels user-friendly and welcoming overall.
cloverhubshop – Smooth layout, products are well organized and simple to browse.
trend zone – Smooth navigation and nicely presented items made checking out the site pleasant.
Timberlake Collections – Clean layout and a nice variety of items made browsing easy and enjoyable.
shop urban leaf – Well-organized categories and neat presentation made browsing enjoyable.
trendy picks – Good atmosphere here; items were arranged well and the browsing was effortless.
Fresh Pine Marketplace – The layout is tidy, and products load quickly, making shopping hassle-free.
новости беларуси граница новости беларуси 2025
Анонимная торговая площадка кракен маркетплейс использует escrow систему для защиты сделок, PGP шифрование для конфиденциальных сообщений и многофакторную аутентификацию.
Tall Pine Essentials – The organized interface helped me explore products without hassle.
Геосинтетические материалы https://stsgeo.ru для строительства купить можно у нас с профессиональным подбором и поддержкой. Продукция для укрепления оснований, армирования дорожных одежд, защиты гидроизоляции и дренажа. Предлагаем геотекстиль разных плотностей, георешётки, геомембраны, композитные материалы.
Fresh Pine Studio Hub – Clean design and fast-loading items made selection quick.
новости спорта беларуси беларусь новости правда
Криптографически защищенный кракен сайт онион версии v3 содержит 56 символов перед расширением точка onion и математически связан с публичными ключами серверов через эллиптические кривые.
Геосинтетические материалы https://stsgeo.ru для строительства купить можно у нас с профессиональным подбором и поддержкой. Продукция для укрепления оснований, армирования дорожных одежд, защиты гидроизоляции и дренажа. Предлагаем геотекстиль разных плотностей, георешётки, геомембраны, композитные материалы.
Bloom Workshop – Smooth layout and clearly displayed items improved the shopping flow.
Soft Blossom Collections – The aesthetic was light and airy, making exploring items feel effortless.
boutique corner – Well-structured layout and neat presentation enhanced the shopping experience.
TallPineEmporium Online Shop – Clear product arrangement and tidy pages helped me shop efficiently.
New Harbor Flowers – Smooth browsing and appealing images enhanced the overall experience.
Home at Future Harbor – The layout is very organized, which helped me quickly find items.
meadowcornerstore – Well-structured pages and easy navigation, shopping was quick.
Soft Blossom Portal – The site’s calm aesthetic and tidy layout made navigation simple and relaxing.
wooden hub – Items loaded quickly and sections were easy to navigate.
SimpleBuyCenter – Found everything easily, checkout was fast and hassle-free.
Future Harbor Market – Efficient layout and clear product organization made browsing easy.
Доставка грузов https://avalon-transit.ru из Китая «под ключ» для бизнеса и интернет-магазинов. Авто-, ж/д-, морские и авиа-перевозки, консолидация на складах, проверка товара, страхование, растаможка и доставка до двери. Работаем с любыми партиями — от небольших отправок до контейнеров. Прозрачная стоимость, фотоотчёты, помощь в документах и сопровождение на всех этапах логистики из Китая.
SmartShoppingHub – Found exactly what I wanted, smooth navigation and quick checkout.
Доставка грузов https://avalon-transit.ru из Китая «под ключ» для бизнеса и интернет-магазинов. Авто-, ж/д-, морские и авиа-перевозки, консолидация на складах, проверка товара, страхование, растаможка и доставка до двери. Работаем с любыми партиями — от небольших отправок до контейнеров. Прозрачная стоимость, фотоотчёты, помощь в документах и сопровождение на всех этапах логистики из Китая.
meadowcollectionstore – Smooth navigation and neatly arranged products, shopping felt pleasant.
Moonlit Garden Goods – Clean layout with well-organized products — very pleasant browsing.
river collection – Intuitive navigation and visually appealing items improved shopping.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Разобраться лучше - https://vivod-iz-zapoya-1.ru/
wildleafmarket – Smooth interface, products are clearly visible and simple to explore.
Moonlit Studio – Layout is tidy and everything is easy to explore — shopping felt comfortable.
Shop With Ease – The logical categories and good selection made my visit both quick and successful.
TrendyMarketHub – Great products and smooth checkout, very satisfied with my order.
shop river collection – Quick loading and clearly displayed items improved shopping.
revival picks – The arrangement helped me find things fast and enjoy the visit.
studiowildcorner – Pleasant layout, items are easy to locate and browse.
UrbanMist Online – I appreciated how the intuitive design made sorting through the large selection so easy.
top picks – I appreciated how clean and fast the site was, making product browsing simple.
LivingTrendStore – Loved the stylish items, quick checkout and hassle-free experience.
revival picks – The arrangement helped me find things fast and enjoy the visit.
marketplace link – Enjoyed the speed and simplicity; products appeared without any lag.
Lush Grove Picks – Simple navigation and clear visuals helped me find items without hassle.
River Outlet Hub – Clear layout and neatly arranged items made browsing effortless.
7K и Ramenbet поскромнее, а здесь ощущение настоящего большого
казино. Джекпот растёт на глазах, скоро кто-то сорвёт куш!
Lush Grove Corner Hub – The site is user-friendly, making product browsing smooth.
Кухня с интегрированной розеткой в столешнице — блендер включаю, ничего не тянется.
soft summer collection – Fast-loading pages and organized layout made browsing pleasant.
River Studio – Well-arranged items and simple navigation made finding products fast.
Wild Ridge Collection – Browsing was fast and pleasant thanks to clean structure.
boutique corner – Well-structured layout and clear sections improved the shopping experience.
Интересная статья о выборе материала для натяжного потолка!
Я всегда думал, что ПВХ практичнее
для кухни из-за влагостойкости, но тканевый вариант звучит уютнее для спальни.
Обязательно учту это при следующем ремонте.
MoonView Market – The site layout was neat and contemporary, with a smooth browsing experience.
Everwild Essentials – The site is straightforward and items load quickly — shopping felt smooth.
Wild Ridge Collection – Browsing was fast and pleasant thanks to clean structure.
MoonView Hub – Modern aesthetic paired with neat product presentation made browsing smooth.
SmartChoiceCorner – Navigation is smooth and everything is well-organized, very satisfying experience.
Everwild Online – Well-presented items and easy browsing — made exploring the site simple.
Стоит посмотреть: гороскоп на сегодня астана
cloud picks – Neatly displayed items and smooth scrolling made browsing effortless.
BrightGroveHub Deals – Crisp interface and smooth flow kept the experience enjoyable.
EasyPickHub – Site layout is clear and simple, making browsing very easy.
Полная статья здесь: лучшие диеты для похудения
waveemporiumhub – User-friendly interface, shopping flows naturally and comfortably.
cloud store – Well-arranged items and simple layout made exploring products easy.
Visit BrightGroveHub – The site structure made it easy to explore without confusion.
truewavestyle – Very organized design, products are easy to browse and locate.
wild collection – Browsing felt effortless and items were displayed clearly.
shop here – Found the browsing experience simple and well-organized from the moment I entered.
harbor picks – Easy-to-use site with organized products improved the shopping experience.
Petal Paradise – Easy-to-use website with tidy product organization.
Coastline Market – Simple design and visible product photos helped me find what I wanted fast.
clean layout store – The site’s clean setup made going through products a breeze.
Savanna Online Market – Products looked attractive and navigating through categories was effortless.
Актуальная кракен тор ссылка для входа публикуется на форуме Dread в даркнете с верификацией через PGP подпись администрации маркетплейса.
ModernUrbanMarket – Enjoyed exploring the products, site is easy to use and visually nice.
Подробная инструкция зайти на кракен включает настройку VPN перед Tor для дополнительного уровня анонимности и скрытия факта использования сети.
Strona internetowa mostbet – zaklady sportowe, zaklady e-sportowe i sloty na jednym koncie. Wygodna aplikacja mobilna, promocje i cashback dla aktywnych graczy oraz roznorodne metody wplat i wyplat.
Petal Corner – Clear, user-friendly interface with neatly listed products.
Coastline Picks – Easy-to-read layout and neat visuals made shopping quick and easy.
Strona internetowa mostbet – zaklady sportowe, zaklady e-sportowe i sloty na jednym koncie. Wygodna aplikacja mobilna, promocje i cashback dla aktywnych graczy oraz roznorodne metody wplat i wyplat.
Golden Savanna Outlet – The display looked appealing and navigating through the pages was smooth.
shop harbor hub – Browsing felt natural and products were easy to explore.
Future Trends Finds – Items are easy to find and layout is clean — shopping was pleasant.
UrbanLifestyleTrends – Navigation is effortless, and product variety is excellent.
trends corner – Clean design and well-structured sections enhanced shopping.
Mountain Sage Collection – Smooth interface and organized categories made discovering items effortless.
Future Wood Collection – Everything is neatly arranged and browsing is straightforward — very convenient.
groveemporium – Fast loading and tidy layout, made finding products effortless.
Odkryj mostbet casino: setki slotow, stoly na zywo, serie turniejow i bonusy dla aktywnych graczy. Przyjazny interfejs, wersja mobilna i calodobowa obsluga klienta. Ciesz sie hazardem, ale pamietaj, ze masz ukonczone 18 lat.
расклад Таро онлайн предоставляет точный прогноз по вашей проблеме одной картой. Вы можете задать вопрос о работе, любви или финансах, и без задержек получить свой расклад. Наш сервис предлагает простой и удобный интерфейс, с подробным описанием символики и значений. Гадание одной картой онлайн поможет сделать правильный выбор, позволяя принимать решения с уверенностью. Выберите вопрос, сконцентрируйтесь и тяните карту, чтобы понять направление событий. Каждая карта имеет уникальное значение, которое помогает понять перспективу. Вы можете использовать расклад в любое время суток, без необходимости посещать гадалку или эзотерический центр. Начните гадание Таро онлайн и узнайте свой ответ, чтобы принимать решения осознанно.
https://russiantaro.ru/
Mountain Sage Collection – Smooth interface and organized categories made discovering items effortless.
Got a breakdown? https://locksmithsinwatford.com service available to your home or office.
EverForest Link – Lots to browse through, and the interface felt responsive throughout.
Хочешь айфон? iphone store спб выгодное предложение на новый iPhone в Санкт-Петербурге. Интернет-магазин i4you готов предложить вам решение, которое удовлетворит самые взыскательные требования. В нашем каталоге представлена обширная коллекция оригинальных устройств Apple. Каждый смартфон сопровождается официальной гарантией производителя сроком от года и более, что подтверждает его подлинность и надёжность.
Гадание онлайн дарит уверенность и понимание в личной жизни, сеансы проводятся с максимальной концентрацией на вашем запросе, дает советы по восстановлению доверия и счастья в паре, расклады проводятся через интернет без визита в офис, вы можете задать любой вопрос о личной жизни, каждое гадание проходит с учетом индивидуальной энергетики клиента, быстрый и точный метод для важных вопросов, консультации помогают понять текущую ситуацию, доступно как разовое гадание, так и серия сеансов, все вопросы решаются дистанционно, без лишней суеты, вы получите профессиональную помощь и ясные ответы, выбирайте удобное время для сеанса, расклады дают возможность увидеть истинные чувства, вы получите поддержку и уверенность в своих решениях, не нужно тратить время на дорогу, вы получите детальный разбор ситуации, Валерия Карат помогает вернуть любовь и доверие, каждое решение учитывает уникальные обстоятельства, помогает принять верное решение без сомнений, опыт и знания помогают найти ответы на любые вопросы, онлайн гадание помогает с выбором партнера, карьерой и личными решениями.
https://valeriakarat.ru/
shop stream hub – Navigation was intuitive and items were neatly displayed.
Хочешь айфон? айфон цена выгодное предложение на новый iPhone в Санкт-Петербурге. Интернет-магазин i4you готов предложить вам решение, которое удовлетворит самые взыскательные требования. В нашем каталоге представлена обширная коллекция оригинальных устройств Apple. Каждый смартфон сопровождается официальной гарантией производителя сроком от года и более, что подтверждает его подлинность и надёжность.
grovecraftstore – Clean layout with well-presented products, shopping felt hassle-free.
PositiveVibesOnly – Creative insights that brighten your knowledge journey.
EverForest Home – The products looked diverse, and the navigation experience was smooth.
Полная версия по ссылке: https://medim-pro.ru/kupit-sanatorno-kurortnuyu-kartu-rebenku/
stonefindslane – Products are easy to browse, site feels neat and organized.
stream picks hub – Fast-loading pages and organized layout made shopping effortless.
Читать больше на сайте: https://medim-pro.ru/kupit-medkomissiyu-na-rabotu/
InspirationDaily – Fresh content to keep your curiosity alive.
https://buffalobossbabes.com/
stonecollectionstore – Pleasant browsing experience, everything is logically placed.
Soft Feather Market Hub – Intuitive layout and well-organized products made shopping convenient.
timber picks – Easy-to-use site with well-organized categories for fast shopping.
new season shop – Loved the refreshing look; everything was organized enough to make browsing smooth.
Soft Feather Hub – Easy-to-browse layout and appealing product presentation enhanced the experience.
Wild Meadow Picks – Neat layout and smooth navigation made exploring products enjoyable.
timberford corner – The layout is tidy and finding products was quick and effortless.
fresh picks – Great layout with clear sections that made browsing comfortable.
Looking for a chat? emerald chat karma system A convenient Omegle alternative for connecting with people from all over the world. Instant connection, random chat partners, interest filters, and moderation. Chat via video and live chat with no registration or payment required.
Everhill Goods Online – Items display nicely with simple navigation — browsing was effortless.
Looking for a chat? emerald chat no signup A convenient Omegle alternative for connecting with people from all over the world. Instant connection, random chat partners, interest filters, and moderation. Chat via video and live chat with no registration or payment required.
Wild Meadow Marketplace – Simple layout and visible items helped me browse effortlessly.
true pine shop – Browsing was effortless and products were clearly displayed.
EverCrestWoods Store – Browsing was smooth thanks to the clean category structure.
Everhill Online Store – Fast-loading items with an intuitive layout — browsing was enjoyable.
true pine collection – Navigation felt natural and products were visually appealing.
EverCrestWoods Catalog – Everything was laid out clearly, helping me browse without confusion.
Silver Maple Hub – User-friendly interface and neat presentation simplified my browsing.
TrendOutletShop – Fantastic prices and fast order processing today.
Silver Maple Goods – Clear layout and simple menus helped me locate everything easily.
ShopGlobalTrends – Found some amazing offers today, really quick checkout process.
shop wave picks – Items were simple to view and the layout was clean.
шлюхи курск шлюхи онлайн
Оформление медицинских анализов https://medim-pro.ru и справок без очередей и лишней бюрократии. Запись в лицензированные клиники, сопровождение на всех этапах, помощь с документами. Экономим ваше время и сохраняем конфиденциальность.
Оформление медицинских анализов https://medim-pro.ru и справок без очередей и лишней бюрократии. Запись в лицензированные клиники, сопровождение на всех этапах, помощь с документами. Экономим ваше время и сохраняем конфиденциальность.
shop wave picks – Items were simple to view and the layout was clean.
leafsoftlane – Items are easy to browse, and navigating feels effortless.
Autumn Mist Storefront – The layout felt inviting, and the items had clear explanations.
Grand Craft Studio – User-friendly interface with clearly arranged products enhanced the shopping experience.
softleafcornerstore – Very organized, products are easy to find and explore.
Grand Craft Hub – Clean pages and logical product arrangement made shopping seamless.
Autumn Mist Storefront – The layout felt inviting, and the items had clear explanations.
Golden Hill Art – Well-organized items and intuitive navigation — shopping was simple and enjoyable.
sunridge store – Browsing was easy and products were well organized.
shop creations – The aesthetic is soft and appealing, and the product layout makes browsing effortless.
Golden Hill Boutique – Well-presented products with clear navigation — shopping felt effortless.
Lunar Wood Finds – Easy-to-use interface and fast-loading products made shopping hassle-free.
sunridge selection – Navigation is simple and items are displayed nicely.
inspired goods – Navigation was smooth and the visual style made browsing relaxing.
Lunar Wood Emporium – Clean design and quick product load made shopping stress-free.
shop moon hub – Items loaded quickly and navigation felt straightforward.
shop moonfield – Items loaded quickly and navigating the site felt intuitive.
harborlookstore – Fast-loading pages with tidy product sections, browsing was quick.
golden collection – Navigation felt natural and products were visually appealing.
Urban Finds – Simple interface and organized items made shopping convenient.
StyleLoversHub – Loved the layout, pages loaded quickly and browsing was comfortable.
GrowBeyondLimits – Truly motivating content, gave me new ideas to develop my skills.
field corner – Clean design and fast-loading pages made shopping enjoyable.
harborlooklane – Organized pages and easy-to-follow sections, shopping felt fast.
Rustic River Finds – Everything is neatly displayed and navigation is straightforward — shopping felt effortless.
Urban Finds – Simple interface and organized items made shopping convenient.
StyleTrendCenter – Nice interface with smooth scrolling and easy navigation.
Shop DreamHavenOutlet – The site looked neat and made scrolling through options fast.
collectiveoakemporium – Products are displayed neatly, and navigating is hassle-free.
GrowLimitlessly – Great insights, makes skill-building feel exciting and achievable.
Rustic River Shop – Items are easy to find and the interface feels smooth — very pleasant experience.
DreamHavenOutlet Picks – The well-spaced design helped create a comfortable scrolling experience.
brightoakboutique – Clean interface, products are easy to locate and explore.
Visit EverHollow Bazaar – Fast navigation overall, and the categories made perfect sense as I explored.
pure wave picks – Fast-loading pages and a neat look made the whole experience pleasant.
green goods hub – Browsing feels intuitive and pages respond quickly.
wildgroveemporium – Items are well arranged and navigation feels intuitive — nice overall experience.
Explore EverHollow – Pages transitioned smoothly, and the category layout was straightforward.
wave deals – The pages looked sharp and the navigation was nice and straightforward.
forest market – Browsing was smooth and I found great products quickly.
wildgroveemporium – Items are well arranged and navigation feels intuitive — nice overall experience.
future gallery finds – Smooth scrolling and clear presentation enhanced the shopping experience.
grove hub corner – Clear sections and responsive pages made exploring products simple.
Sun Wind Artisan – Neatly arranged products and simple interface enhanced the shopping experience.
Urban Finds – Shopping here felt intuitive and straightforward.
Bright Deals Store – Products are organized and finding items is simple — I had a pleasant shopping time.
Sun Wind Boutique – Simple interface with clearly displayed products made shopping convenient.
Urban Studio – Browsing items was effortless and everything was neatly arranged.
Bright Choice Market – Nice arrangement of items and effortless browsing — overall good experience.
Электрокарниз — это идеальное решение для современного интерьера, которое можно найти по ссылке электрокарнизы купить в москве Прокарниз.
Наиболее заметным плюсом электрокарниза является его удобство.
leafsilvermarket – Items are neatly categorized, shopping feels intuitive.
leafsilverhub – Smooth navigation, items are well organized and easy to find.
DeterminationHub – Easy-to-follow tips, makes goal-setting feel achievable.
QuickFindDeals – Great value options featured, and the interface felt simple and structured.
The best undress ai for digital art. It harnesses the power of neural networks to create, edit, and stylize images, offering new dimensions in visual creativity.
fresh picks – Browsing felt fluid and items were easy to explore.
Управляемые шторы позволяют effortlessly контролировать освещение в вашем доме. шторы автоматические с электроприводом — это идеальное сочетание стиля и функциональности.
Управляемые шторы также обеспечивают дополнительную безопасность в домах с детьми и животными.
BrightPetal Boutique – Simple layout and clear photos made finding what I wanted effortless.
DealSpotToday – Plenty of solid discounts and the layout made comparing items effortless.
DeterminedMinds – Encouraging guidance, very simple to follow and effective.
EverWillow Browse – The shop feels friendly, with items arranged in a way that’s simple to explore.
harvest picks – Browsing felt natural and all products were displayed clearly.
BrightPetal Crafts Hub – Simple design and good photos helped me make choices easily.
stone picks – Neatly arranged products and smooth interface made browsing effortless.
EverWillow Crafts Online – Pleasant sections and easy-to-find categories made the experience enjoyable.
shop stone hub – Navigation was intuitive and items were neatly displayed.
Установите электронные жалюзи на окна Prokarniz, и наслаждайтесь комфортом и простотой управления светом в вашем доме.
Автоматические жалюзи на окна с электроприводом становятся все более популярными. Эти инновационные устройства предлагают комфорт и удобство.
Во-первых, такая система управления позволяет регулировать уровень света в помещении. Управление жалюзи осуществляется через дистанционный пульт, что делает использование более комфортным.
Кроме того, такие жалюзи помогают экономить энергию. Их рациональное использование помогает сохранять оптимальную температуру в помещении.
Подводя итог, можно сказать, что автоматические жалюзи с электроприводом – это отличный выбор для современных интерьеров. Эти устройства не только практичны, но и привносят стиль в любой интерьер.
Feather Studio – Clear interface with tidy product arrangement enhanced the experience.
Explore LunarBranchStore – The neat sections and fast load times improved the experience.
Feather Studio – Clear interface with tidy product arrangement enhanced the experience.
a href="https://pureforeststudio.shop/" />forestlanehub – Clear layout with intuitive sections, shopping felt natural.
Lunar Branch Collection – Smooth interface and clear design made shopping comfortable.
Find Hot Deals – Pages load quickly, and navigating through offers feels effortless.
Удобно и стильно: рулонные шторы с пультом управления цена Prokarniz для вашего дома!
Популярность рулонных штор с электроприводом растет среди современных дизайнеров. Они предоставляют уникальную комбинацию удобства и эстетики, что делает их идеальными для различных стилей интерьера.
Главное достоинство рулонных штор с электроприводом - это возможность управления с помощью пульта. Такая система управления делает использование штор невероятно удобным и простым.
Широкий ассортимент моделей и тканей рулонных штор с электроприводом позволяет выбрать подходящий вариант для любого интерьера. Это дает возможность подобрать идеальный вариант как для классического, так и для современного стиля.
Заказать рулонные шторы с электроприводом можно в специализированных магазинах или через интернет. Не забудьте проверить качество и репутацию компании перед покупкой, чтобы гарантировать долговечность продукции.
Find Today’s Offers – Fast load times and finding discounts was simple.
GV Corner – Browsing was quick and stress-free with the neat website layout.
Journey Builder – Smooth experience overall; messages felt authentic and helpful.
deltafabricshub – Very easy to browse, products are displayed neatly and clearly.
Golden Vine Goods – Well-structured categories allowed me to find items quickly.
CreateYourPath Guide – Really enjoyed browsing through this today; everything felt refreshingly clear.
brightfabricstore – Smooth navigation and the items are well organized throughout the site.
Удобство и стиль в интерьере обеспечит купить электрокарнизы в москве Prokarniz, который легко управляется с пульта.
Установка электрокарниза не требует сложных манипуляций и может быть выполнена самостоятельно.
Free video chat emerald chat online find people from all over the world in seconds. Anonymous, no registration or SMS required. A convenient alternative to Omegle: minimal settings, maximum live communication right in your browser, at home or on the go, without unnecessary ads.
Soft Forest Treasures – Clean interface and easy-to-see products made shopping stress-free.
Free video chat emerald chat site find people from all over the world in seconds. Anonymous, no registration or SMS required. A convenient alternative to Omegle: minimal settings, maximum live communication right in your browser, at home or on the go, without unnecessary ads.
Soft Forest Designs – Organized interface and smooth navigation made finding items simple.
LearnWithEase – The tutorials were simple and engaging, I learned a lot today.
FreshLookBoutique – Great presentation of clothing pieces and navigating felt light and enjoyable.
MoonGrove Online – Fast-loading pages and a clean layout made the browsing experience enjoyable.
Откройте для себя удобство и стиль, которые предлагают купить автоматические рулонные шторы прокарниз, идеально подходящие для любого интерьера.
Рулонные шторы с автоматическим управлением становятся все более популярными среди современных интерьеров. Их удобство и функциональность порадуют даже самых требовательных пользователей .
Важным аспектом является простота в эксплуатации автоматических рулонных штор . Процесс управления этими шторами стал легким благодаря использованию кнопок и пультов.
Кроме того, многие модели автоматических штор предлагают различные функции . Возможность настройки добавляет функциональности и комфорта .
Выбор дизайна автоматических штор очень важен для гармонии в интерьере. Важно, чтобы они сочетались с другими элементами декора .
ValuableLearning – Really enjoyed the guides, made learning new things effortless and fun.
FreshStyleMarket – The outfits looked great and navigating the site felt light and simple.
Latest Offers Online – Smooth experience and the deals are clearly presented.
MoonGrove Picks – Everything loaded immediately, with a tidy design that made exploring easy.
Discount Finds Portal – Quick loading and finding bargains was effortless.
Умные шторы — это инновационное решение для вашего дома, которое позволяет легко управлять светом и конфиденциальностью. Узнайте больше о автоматические шторы для умного дома Прокарниз!
Это актуально для жителей мегаполисов с их ярким светом.
Эти изделия способны работать в связке с другими устройствами в системе «умный дом».
Умные шторы способствуют повышению энергоэффективности вашего дома.
Монтаж умных штор может быть выполнен самостоятельно или с помощью специалистов.
Wild Spire Collection Online – Fast loading and clear structure made discovering products effortless.
Pathway Inspiration – Found the tone uplifting and the visuals pleasantly simple.
Wild Spire Hub – User-friendly interface and tidy layout simplified the shopping experience.
Creative Path Spot – Took a quick look and liked how everything flowed naturally.
Shop EverMapleCrafts – Nicely presented items made the browsing experience feel relaxed.
Установите жалюзи оконные с электроприводом Prokarniz для удобства управления светом и обеспечения уюта в вашем доме.
Современные автоматические жалюзи на окна с электроприводом предлагают отличное сочетание стиля и комфорта.
Gift Hub Online – Browsing was simple and the gift selection was very appealing.
Brightline Market – Shopping was effortless thanks to the clear images and neat design.
EverMapleCrafts Store – Products were arranged neatly, making it easy to explore everything.
Style Trend Market – Enjoyable scrolling experience and lots of standout clothing choices.
Pure Gifts Online – Fast-loading site and attractive gift items throughout.
Brightline Crafts Shop – The clear design and product clarity made my shopping smooth.
DreamDiscoverer – Loved the uplifting content, navigating was comfortable.
ValueFinderHub – Great selection of products, and browsing through the site was effortless.
Favorites Explorer – Layout is neat and finding items was simple and enjoyable.
Style Trend Market – Enjoyable scrolling experience and lots of standout clothing choices.
Если вы хотите добавить стиль и комфорт в свой дом, автоматические горизонтальные жалюзи +7 (499) 638-25-37 — отличное решение!
Если вы не уверены в своих силах, лучше обратиться к специалистам.
DreamDiscoverer – Loved the uplifting content, navigating was comfortable.
Discover Top Favorites – Very straightforward layout and enjoyable experience overall.
BudgetSpotHub – Products displayed nicely, browsing felt fast and simple.
FashionTrendsOnline – Fast delivery, trendy items, and excellent quality.
Silver Hollow Essentials – Items are presented in a clean and polished way, with descriptions that make sense.
TrendyStopOnline – Loved the variety of items, browsing was smooth and hassle-free.
willowlaneemporium – Fast-loading pages with tidy product sections, browsing felt quick.
Откройте для себя электро жалюзи прокарниз, которые обеспечат идеальный контроль света и уюта в вашем доме.
Вы можете настроить жалюзи как на ручное управление, так и использовать дистанционный пульт.
FashionForwardWorld – Stylish collections and fast service, highly recommended.
Silver Hollow Online – Elegant visuals paired with clear descriptions make browsing simple and enjoyable.
TrendyShopOnline – Attractive and trendy items with clean design and easy browsing.
Moonglade Marketplace – The website is organized, making shopping simple and enjoyable.
Gifts & More – Liked the selection available; everything was organized neatly.
willowtrendstore – Clear sections with easy navigation, shopping felt natural.
Moonglade Online – Easy-to-use navigation and neat pages made shopping pleasant.
GiftBox Ideas – Enjoyed the selection and appreciated how clear the layout was.
Pure Gift Picks Hub – Smooth navigation and a well-laid-out product display.
МЕД ЗДЕСЬ медицинский портал – площадка с данными о патологиях и клинических состояниях, где собраны развернутые сведения о внутренних органах, болезнях и возможных осложнениях. Пользователи находят здесь структурированную информацию о проявлениях и стадиях болезней, что помогает быстрее ориентироваться в медицинских вопросах. На ресурсе представлены обзоры наиболее частых заболеваний, каждый из которых подготовлен с учетом достоверных научных данных. Особое внимание уделено факторам, влияющим на течение болезни, что делает информацию полезной для изучения здоровья. В материалах портала рассматриваются острые и хронические состояния, включая системные заболевания, что обеспечивает широкий охват тем. Пользователи могут ознакомиться с подходами к диагностике, а также узнать о вариантах лечения, которые используются в современной медицине. Важную роль в представленных материалах играют советы специалистов, которые помогают формировать объективное восприятие медицинской информации. Для удобства читателей данные изложены простым и понятным языком, что дает возможность изучать анатомию и патологии даже без специальной подготовки. На портале МЕД ЗДЕСЬ также представлены материалы о функциях систем организма, которые помогают формировать общее представление о здоровье. Благодаря сочетанию понятного изложения ресурс становится удобным инструментом для изучения здоровья.
https://medzdes.ru/
Gift Outlet Hub – Pleasant layout and shopping felt enjoyable and simple.
BrightPeak Goods – Easy layout and clear product photos made decision-making quick.
Style Selection Center – Easy to navigate and discovering products was enjoyable.
современные мобильные УЗИ системы – важная часть оснащения медкабинета, который позволяет быстро и точно проводить исследования. Оборудование такого класса используется в кардиологии и терапии, поскольку реалистичность ультразвуковой визуализации имеет решающее значение в процессе лечебного планирования. Компактные УЗИ сканеры от GE Ultrasound разработаны с учетом высоких требований специалистов, что делает их практичным выбором для врачей. Благодаря эргономичному дизайну оборудование удобно использовать как в небольших кабинетах, так и в отделениях скорой помощи, где важны скорость и удобство. Принцип работы современных УЗИ систем основан на интеллектуальных алгоритмах визуализации, благодаря чему врач получает четкое изображение органов и тканей. GE Ultrasound также предлагает различные режимы сканирования, что позволяет адаптировать устройство под индивидуальные задачи специалиста. Оборудование поддерживает функции автоматизации анализа, что помогает получить максимальную эффективность обследования. Медицинские специалисты отмечают, что современные УЗИ аппараты показывают себя особенно хорошо в условиях, где нужно обеспечить непрерывную работу. Помимо компактных УЗИ систем, комплектация медкабинетов включает вспомогательное терапевтическое оборудование, создавая полный комплекс функциональных возможностей для клиники. GE Ultrasound делает акцент на качественном сервисном сопровождении, что особенно важно в сфере, где оборудование напрямую влияет на безопасность и здоровье пациентов. Благодаря сочетанию гибкости, функциональности и высокой детализации такие устройства становятся основой современного диагностического процесса. Использование этих решений позволяет клиникам создать среду для принятия точных и быстрых решений, делая партнерство с GE Ultrasound важным шагом для развития медицинского центра.
https://mdclinics.ru/
Fashion Deal Market – Pages loaded quickly and the selection covered lots of good looks.
профессиональные ультразвуковые ванны – универсальное оборудование, которое используется для качественного удаления загрязнений с широкого спектра предметов. Ультразвуковая ванна основана на принципе образования микровибраций в жидкости, благодаря которому загрязнения отделяются даже из труднодоступных мест. Такое оборудование широко применяется в медицине и стоматологии, так как оно экономит время. Благодаря универсальности ультразвуковых ванн пользователи могут очищать хрупкие предметы, что делает их незаменимыми в профессиональных сервисных центрах. Конструкция ультразвуковой ванны может включать усиленную рабочую емкость с защитным покрытием, а также встроенные преобразователи высокой мощности, которые обеспечивают согласованность частотных импульсов. Принцип работы аппарата основан на том, что ультразвуковые волны формируют кавитационные зоны в жидкости, которые при схлопывании чистят даже труднодоступные участки изделий. Благодаря такой технологии очистка становится максимально деликатной и безопасной, так как оборудование потребляет минимум ресурсов. Ультразвуковые ванны особенно удобны для тех, кто ценит автоматизацию процесса, поскольку они позволяют запустить цикл без постоянного контроля. Помимо стандартных моделей существуют варианты с настройкой интенсивности ультразвука, что обеспечивает точную настройку под конкретные задачи. Профессиональные ультразвуковые ванны также отличаются повышенным ресурсом работы, благодаря чему они хорошо подходят для интенсивной работы в производственных условиях. В итоге ультразвуковые ванны являются экономичным решением для тех, кто хочет получать стабильное качество очистки, при этом сохраняя оптимальный баланс затрат и результата.
https://natcopharm.ru/
BrightPeak Harbor Store – The website layout is neat and made finding items very easy.
OpportunitySpot – Items are displayed nicely, and the site is easy to use.
Perfect Outfit Picks – Easy to browse, with all items clearly displayed.
ModernStyleSpot – Stylish products and smooth navigation throughout the site.
Free video chat Emerald Chat platform find people from all over the world in seconds. Anonymous, no registration or SMS required. A convenient alternative to Omegle: minimal settings, maximum live communication right in your browser, at home or on the go, without unnecessary ads.
Urban Trendy Deals – Found lots of cool pieces and the site ran efficiently throughout.
OpportunityFinder – Great selection of items and the site is very easy to browse.
TrendStyleVault – Items are attractive, moving through pages was effortless.
Pine Crest Collection – Smooth scrolling and tidy pages helped me check items quickly.
PineCrestModern Storefront – The interface was tidy, allowing me to browse items comfortably.
Golden Ridge Gallery Site – Overall experience was smooth, with a neat layout that made exploring satisfying.
ContempoHomeCollection – Stylish and functional decor, very easy to navigate and enjoy.
Gold Shore Selection – Pleasant navigation made discovering items effortless.
All the details at the link: https://digitalmarketingsalarytex09114.blog-ezine.com/38902343/nppr-team-shop-your-ultimate-hub-for-social-media-marketing-mastery
DayAway Shop Online – Pleasant user experience and items are easy to explore.
Must-Read Collection: https://notariaunicapaime.com.co/2025/10/08/buy-facebook-accounts-from-1-cent-only/
Visit Golden Ridge Gallery – Smooth page transitions and a clear arrangement made exploring enjoyable.
ThriveLearningHub – Great resources here, everything was well organized and easy to explore.
Fresh Picks Online – Fast-loading pages and an intuitive browsing experience.
Gold Shore Treasures – The layout is clean, making product discovery simple and fast.
ModernHomeVibes – Loved the stylish items, browsing and purchasing was very smooth.
DayAway Selections – Layout is tidy and finding items was simple and fast.
ThriveEduSpot – Found informative materials easily and the pages loaded quickly.
Explore Fresh Daily – Very user-friendly interface with enjoyable browsing experience.
TrendSpot – Items are displayed nicely, and browsing is intuitive.
CityStyle Choice – Stylish products and the layout made browsing effortless and enjoyable.
LifestyleTreasureHub – Lovely selection, browsing felt intuitive and comfortable.
StyleSpot – Great selection of clothing, navigating pages is smooth.
StyleChoice Hub – Quick navigation and stylish pieces made browsing very comfortable.
Modern Home Gallery – Very tidy site today, with easy access to all décor categories.
ModernLifestyleSpot – Items are stylish, browsing felt fast and effortless.
Free video chat http://emerald-chat.app and a convenient alternative to Omegle. Instant connections, live communication without registration, usernames, or phone numbers. Just click "Start" and meet new people from all over the world, whenever you like and whatever your mood.
ModernHome Trends – The décor selection looked great, and navigating through pages felt effortless.
autumnmarketcentral – Neatly organized pages and smooth navigation made shopping effortless.
CreateAndBelieve Picks – The layout was clean and exploring products was straightforward.
Fresh Find Center – Pleasant experience with organized and accessible product listings.
Soft Pine Hub – User-friendly interface and tidy layout simplified browsing and selection.
Believe & Craft Market – Smooth navigation and nicely organized inspirational products.
Fresh Selection Online – Very clear interface and easy to browse through items.
Soft Pine Marketplace Online – Clear structure and intuitive menus made browsing effortless.
autumnlookhub – Fast-loading pages with intuitive navigation, shopping felt natural.
Soft Summer Portal – Soft colors and easy navigation made exploring items stress-free.
Sunlit Valley Essentials – Intuitive layout and clear sections made exploring easy.
Explore Soft Summer – Easy-on-the-eyes visuals made checking products enjoyable and stress-free.
SunlitValleyMarket Online Shop – Well-laid-out sections and clear visuals made browsing enjoyable.
FashionSpotlight – Loved exploring the products, and the site feels intuitive.
DailyEduSpot – Engaging and helpful materials, easy to browse through.
Adventure Choice Store – Pleasant browsing and the product range felt both fun and useful.
LivingDiscoverVault – Nice assortment of items, site navigation is simple and user-friendly.
StyleExplorer – Loved the variety, site navigation felt effortless.
LearnSmartToday – Informative sections with a clear layout made exploring easy.
Adventure Choice Store – Pleasant browsing and the product range felt both fun and useful.
StyleTrend Hub – The page design felt fresh, and checking out different products was hassle-free.
LivingTrendsHub – Great range of products, site is easy to navigate and browsing felt smooth.
ModernTrend Online – Neatly arranged listings with fast loading and easy category access.
Explore Fashion Trends – Easy to browse, well-organized products, and fast-loading pages.
Best Season Outlet – Easy to navigate with lots of attractive seasonal products.
Explore Fashion Trends – Easy to browse, well-organized products, and fast-loading pages.
Season Store Online – Smooth navigation and a well-presented selection of seasonal items.
DailyChoiceStore – Attractive layout, very convenient for shopping.
NewValuePicks – The website is fast and browsing was quite pleasant.
a href="https://evertrueharbor.shop/" />EverTrue Picks – Nicely organized sections made the experience smooth and stress-free.
DailyEssentialsHub – Wide range of products, browsing was smooth and simple.
Style Essentials Hub – Everything displayed neatly, making shopping smooth and easy.
UrbanVaultSpot – Nice variety of fashion items, moving through pages was smooth.
NewValuePicks – The website is fast and browsing was quite pleasant.
Expand details: https://podcasts.apple.com/th/podcast/puzzlefree/id1697682168?i=1000737823170
a href="https://evertrueharbor.shop/" />Explore EverTrue Harbor – The site flowed naturally, and everything was laid out in an easy-to-understand way.
The most useful for you: https://podcasts.apple.com/zw/podcast/puzzlefree/id1697682168?i=1000737822998
Smart Trend Market – Great user-friendly design paired with easy access to every product section.
Global Trend Stop – Smooth performance and a diverse selection kept me browsing longer.
Motivational Corner – Pleasant layout and articles are easy to read.
ChicVaultUrban – Products are attractive, moving through the site was effortless.
BrightPineFields Products – Neatly organized items made the shopping process smooth.
Проверенный кракен даркнет маркетплейс работает через Tor браузер с полной анонимностью пользователей и системой эскроу защиты для безопасных сделок между покупателями и продавцами.
Fashion Corner Hub – Clean layout and modern design made browsing enjoyable.
Trend Choice Online – The store presents items attractively and page transitions are smooth and quick.
Keep Motivated Hub – Navigation is intuitive and the content encourages engagement.
Bright Pine Fields Collection – The uncluttered format helped me move around without hassle.
FindOutMoreLink – Enjoyed how clean everything looked and how quickly the pages loaded.
Bright Fashion Hub – Very responsive site with an attractive lineup of fashion items.
Review sites frequently rank software to help you find the best ai music generator for your budget.
система кохлеарной имплантации Nurotron Venus– высокоточное решение, созданное для людей всех возрастных групп, испытывающих значительные нарушения слухового восприятия. Система Nurotron Venus имеет подтверждение качества CE, что гарантирует соответствие высоким требованиям безопасности. Эта технология позволяет существенно расширить возможности слухового восприятия, что особенно важно для социальной активности и коммуникации. Существенным плюсом Nurotron Venus является точная передача звуковых частот, которая обеспечивает комфортное восприятие речи при разных уровнях окружения. Благодаря компактному и удобному речевому процессору пользователи могут комфортно носить систему даже при длительном использовании. Важной особенностью является простота индивидуальной настройки, что позволяет получить максимально естественный слуховой отклик. Кроме того, Nurotron Venus предлагает длительный срок службы компонентов, что делает систему оптимальным выбором для активного образа жизни. Для пользователей, ведущих активную жизнь, система открывает возможности для комфортного общения. Технология Venus также обеспечивает плавное привыкание к новым звукам, благодаря чему адаптация проходит более естественно и эффективно. Таким образом, Nurotron Venus — это эффективное решение, которое помогает получить доступ к разнообразному слуховому спектру, обеспечивая все условия для улучшения слухового опыта.
https://van-mourik-medical.ru/
TodayDiscoverySpot – Helpful sections throughout, with a layout that made browsing simple.
The technology behind every modern ai music generator relies on deep learning neural networks trained on vast audio libraries.
minecraftshopcentral – Smooth pages and intuitive navigation, shopping was quick and pleasant.
Программа National Sailing Wellness Days – это лучший выбор для активных личностей, которые ищут действенные методы для восстановления сил. Данная инновационная программа предлагает гармоничное сочетание морского приключения и персонального роста. Вас ожидает удивительное приключение продолжительностью десять дней, в течение которых вы откроете для себя красоту морских просторов. Ежедневно вас будет ожидать управлением яхтой и полезными физическими нагрузками. Опытные капитаны и дипломированные диетологи расскажут о главных принципах здорового образа жизни и правильного питания на борту. Главной целью программы является не просто временный отдых от городской суеты, а создание прочного фундамента для будущих изменений. Вы научитесь не только управлять парусным судном, но и правильно питаться, слушать свое тело и противостоять стрессам. Море выступает в роли мощного природного терапевта, а совместная работа под парусами развивает коммуникабельность и ответственность. По окончании этого удивительного путешествия вы обретете новый взгляд на свою жизнь и здоровье. Вам достанется не просто багаж впечатлений и фото, но и четкий план действий для дальнейшего самосовершенствования. Программа National Sailing Wellness Days — это вклад в ваше долголетие, где здоровье и активность становятся неотъемлемой частью каждого дня. Используйте эту возможность начать все с чистого листа, став участником программы, которая задаст новый вектор развития.
https://healthandsailing.ru/
Геосинтетические материалы https://stsgeo-spb.ru для строительства и благоустройства в Санкт-Петербурге и ЛО. Интернет-магазин геотекстиля, георешёток, геосеток и мембран. Работаем с частными и оптовыми заказами, быстро доставляем по региону.
Интернет-магазин https://stsgeo-krd.ru геосинтетических материалов в Краснодар: геотекстиль, георешётки, геоматериалы для дорог, фундаментов и благоустройства. Профессиональная консультация и оперативная доставка.
nobleartstore – Fast-loading site with neat product sections, picking items was simple.
Геосинтетические материалы https://stsgeo-spb.ru для строительства и благоустройства в Санкт-Петербурге и ЛО. Интернет-магазин геотекстиля, георешёток, геосеток и мембран. Работаем с частными и оптовыми заказами, быстро доставляем по региону.
Интернет-магазин https://stsgeo-krd.ru геосинтетических материалов в Краснодар: геотекстиль, георешётки, геоматериалы для дорог, фундаментов и благоустройства. Профессиональная консультация и оперативная доставка.
StyleFinder – Loved the fashionable items, browsing through the site was smooth.
GlobalTrendFinds – Wide variety of items and moving through the site was simple.
Comfort Living Hub – Solid selection and quick navigation made the visit worthwhile.
TrendSpot – A nice selection of stylish products with easy navigation.
FreshDailyItems – Good variety of products, simple browsing experience.
Строительные геоматериалы https://stsgeo-ekb.ru в Екатеринбурге с доставкой: геотекстиль, объемные георешётки, геосетки, геомембраны. Интернет-магазин для дорожного строительства, ландшафта и дренажа. Консультации специалистов и оперативный расчет.
Urban Wild Grove Online Shop – Well-organized pages and modern design ensured smooth browsing.
Grow & Connect Hub – Clear layout and information was easy to locate quickly.
Bright Choice Finds – Nicely arranged items and a user-friendly flow kept shopping stress-free.
TrendVaultDiscover – Good deals with simple navigation and enjoyable browsing.
Home Harmony Hub – Lots of charming items and the site performed smoothly.
Строительные геоматериалы https://stsgeo-ekb.ru в Екатеринбурге с доставкой: геотекстиль, объемные георешётки, геосетки, геомембраны. Интернет-магазин для дорожного строительства, ландшафта и дренажа. Консультации специалистов и оперативный расчет.
BuySmartDaily – Clean design, quick and easy navigation.
Share & Grow Online – Found the resources very useful, and browsing was simple.
Shop Urban Wild Grove – Smooth interface and tidy sections made browsing simple and enjoyable.
ChoiceMarket Today – The shop layout looked tidy, and exploring different sections felt pleasant.
Uwielbiasz hazard? nv casino: rzetelne oceny kasyn, weryfikacja licencji oraz wybor bonusow i promocji dla nowych i powracajacych graczy. Szczegolowe recenzje, porownanie warunkow i rekomendacje dotyczace odpowiedzialnej gry.
InnovativeThoughtHub – Creative posts with a user-friendly interface and smooth scrolling.
Нужна работа в США? цена курса диспетчера грузоперевозок в америке онлайн для новичков : работа с заявками и рейсами, переговоры на английском, тайм-менеджмент и сервис. Подходит новичкам и тем, кто хочет выйти на рынок труда США и зарабатывать в долларах.
Нужна работа в США? dispatcher academy : работа с заявками и рейсами, переговоры на английском, тайм-менеджмент и сервис. Подходит новичкам и тем, кто хочет выйти на рынок труда США и зарабатывать в долларах.
BrightMountainMall Store – Enjoyed how organized the pages were while exploring products.
CreativeThoughtsNetwork – Found some inspiring ideas and the site flowed very nicely.
Bright Mountain Select – The pages felt well-arranged, making shopping feel seamless.
FreshStyleSpot – Stylish items and browsing experience was very comfortable.
Нужна работа в США? курс диспетчера грузоперевозок для снг для новичков : работа с заявками и рейсами, переговоры на английском, тайм-менеджмент и сервис. Подходит новичкам и тем, кто хочет выйти на рынок труда США и зарабатывать в долларах.
Нужна работа в США? сколько зарабатывает трак диспетчер в сша : работа с заявками и рейсами, переговоры на английском, тайм-менеджмент и сервис. Подходит новичкам и тем, кто хочет выйти на рынок труда США и зарабатывать в долларах.
Creative Gems Store – Layout feels clean and browsing through the selection was easy.
TrendSpotFresh – Loved the collections, browsing was seamless and enjoyable.
Рабочее кракен зеркало обновляется каждые два месяца для предотвращения блокировок и обеспечения непрерывного доступа к маркетплейсу всех пользователей.
Коэффициенты на баскетбол по четвертям просто огонь
Value Collection Shop – Good mix of affordable picks and the navigation worked flawlessly.
Unique Finds Hub – The layout is clean and exploring products was simple.
Quiet Plains Shop – Really liked the clean interface today, and products were easy to explore.
ValueHub Online – Browsing was smooth, and the overall product quality seems promising.
Quiet Plains Outlet – A soft, minimal design that made looking through the catalog effortless.
Blue Harbor Highlights – Everything popped up without delay, and the product layout felt intuitive.
Промокод драгон мани ACTIV2025 даёт +200% и 100 фс
FindDailyDeals – Clean visuals, navigation was straightforward.
BH Bloom Shop – The page speed was solid and the product arrangement felt very natural.
BestDailyFinds – Simple interface, finding products was fast.
stylishbayhub – Well-laid-out interface, browsing products felt effortless.
stylishbaystore – Clean layout and intuitive design, made shopping enjoyable.
TrendChoiceMarket – Stylish items showcased neatly with effortless browsing.
SmartShopOutlet – Products are well-organized and browsing experience is smooth.
Simply desire to say your article is as astounding. The clarity in your post is just spectacular and i could assume you are an expert on this subject. Fine with your permission let me to grab your feed to keep updated with forthcoming post. Thanks a million and please keep up the rewarding work.
escort catalog Brasilia
Creative Vision Hub – Smooth experience with creative suggestions that caught my eye.
FreshTrend Online – Enjoyed the modern feel here, easy to check out items without hassle.
TrendFinderOnline – Browsing was effortless and the products were displayed clearly.
SmartSavingsOutlet – Affordable finds and browsing the site feels comfortable.
BudgetFriendlyHub – Affordable products with great quality, very happy with my finds.
Trendy Outfit Store – Great mix of fashion picks and a neat website layout made it easy to browse.
Inspired Creativity Hub – Easy to explore and content was engaging and motivating.
FreshTrend Fashion – Everything feels crisp and trendy, with a user-friendly flow.
QualityAndSavings – High-quality items at excellent prices, I’m delighted with my purchase.
Срочный вызов электрика https://vash-elektrik24.ru на дом в Москве. Приедем в течение часа, быстро найдём и устраним неисправность, заменим розетки, автоматы, щиток. Круглосуточный выезд, гарантия на работы, прозрачные цены без скрытых доплат.
Срочный вызов электрика https://vash-elektrik24.ru на дом в Москве. Приедем в течение часа, быстро найдём и устраним неисправность, заменим розетки, автоматы, щиток. Круглосуточный выезд, гарантия на работы, прозрачные цены без скрытых доплат.
TAB Picks Online – Stylish items laid out clearly, browsing was simple and fast.
Modern Style Finds – Browsing felt effortless and the clothing selection was impressive.
Rainforest Trend Shop – Great user experience today, with a clean layout and responsive browsing.
PureHarborStudio Portal – Organized sections and clear visuals made it easy to find items.
TAB Picks Hub – Nice range of items, site performance was quick and smooth.
Rainforest Deals Hub – Nice selection overall, and navigating the categories felt natural.
PureHarborStudio Deals – Smooth navigation and clear arrangement made browsing effortless.
pinehillstudio – The layout feels clean and simple, making browsing surprisingly pleasant today.
timelessharveststore – Really enjoyed scrolling here, everything looked organized and easy to understand.
rusticriverstudio – Pages loaded fast and the visuals gave the shop a warm inviting vibe.
softblossomstudio – Loved the gentle aesthetic, it made my browsing experience feel calm and smooth.
moonviewdesigns – The site felt refreshing and modern, items were neatly displayed overall.
everforestdesign – Nice selection here, navigation felt intuitive and everything loaded without hesitation.
autumnmistemporium – The shop has a cozy vibe, and product details looked clear and helpful.
everhollowbazaar – Browsing was smooth, categories were easy to explore and made sense right away.
everwillowcrafts – The store feels friendly and thoughtfully arranged, making browsing enjoyable today.
moongrovegallery – Really liked how polished everything looked, pages loaded instantly and cleanly.
silverhollowstudio – The design is elegant and items appear well-presented with clear descriptions.
goldenridgegallery – Smooth experience overall, I found browsing quick and surprisingly relaxing today.
softsummershoppe – The gentle theme made the shop feel welcoming, easy on the eyes while browsing.
evertrueharbor – Enjoyed visiting the site, everything looked organized and straightforward to explore.
urbanwildgrove – The shop feels modern and tidy, navigation was easy and frustration-free.
blueharborbloom – Pages loaded fast and the product layout felt natural and visually appealing.
wildfieldmercantile – Browsing was enjoyable, items looked well-arranged and details were simple to read.
silvergardenmart – The store gives a reliable impression, everything felt smooth from start to finish.
timberpathstore – Nice overall feel, categories were easy to jump through without any confusion.
evernovaemporium – Loved the aesthetic here, browsing felt seamless and pleasantly well-organized today.
Today's Top Stories: https://markets.financialcontent.com/buffnews/article/abnewswire-2025-12-4-the-ultimate-guide-to-buying-facebook-advertising-accounts-what-must-be-known/
Uwielbiasz hazard? nv casino online login: rzetelne oceny kasyn, weryfikacja licencji oraz wybor bonusow i promocji dla nowych i powracajacych graczy. Szczegolowe recenzje, porownanie warunkow i rekomendacje dotyczace odpowiedzialnej gry.
Gates of Olympus https://gatesofolympus.win is a legendary slot from Pragmatic Play. Demo and real money play, multipliers up to 500x, free spins, and cascading wins. An honest review of the slot, including rules, bonus features, and tips for responsible gaming.
View on the website: http://lyfmap.com/blog/question/secret-strategies-to-buy-facebook-business-manager-conquer-your-industry/
Онлайн курс курс Truck Dispatcher: обучение с нуля до уверенного специалиста. Стандарты сервиса, документооборот, согласование рейсов и оплата. Пошаговый план выхода на работу у американских логистических компаний.
pinehillstudio – The layout feels clean and simple, making browsing surprisingly pleasant today.
timelessharveststore – Really enjoyed scrolling here, everything looked organized and easy to understand.
rusticriverstudio – Pages loaded fast and the visuals gave the shop a warm inviting vibe.
softblossomstudio – Loved the gentle aesthetic, it made my browsing experience feel calm and smooth.
moonviewdesigns – The site felt refreshing and modern, items were neatly displayed overall.
everforestdesign – Nice selection here, navigation felt intuitive and everything loaded without hesitation.
autumnmistemporium – The shop has a cozy vibe, and product details looked clear and helpful.
everhollowbazaar – Browsing was smooth, categories were easy to explore and made sense right away.
everwillowcrafts – The store feels friendly and thoughtfully arranged, making browsing enjoyable today.
moongrovegallery – Really liked how polished everything looked, pages loaded instantly and cleanly.
silverhollowstudio – The design is elegant and items appear well-presented with clear descriptions.
goldenridgegallery – Smooth experience overall, I found browsing quick and surprisingly relaxing today.
softsummershoppe – The gentle theme made the shop feel welcoming, easy on the eyes while browsing.
evertrueharbor – Enjoyed visiting the site, everything looked organized and straightforward to explore.
urbanwildgrove – The shop feels modern and tidy, navigation was easy and frustration-free.
blueharborbloom – Pages loaded fast and the product layout felt natural and visually appealing.
wildfieldmercantile – Browsing was enjoyable, items looked well-arranged and details were simple to read.
silvergardenmart – The store gives a reliable impression, everything felt smooth from start to finish.
timberpathstore – Nice overall feel, categories were easy to jump through without any confusion.
evernovaemporium – Loved the aesthetic here, browsing felt seamless and pleasantly well-organized today.
TrendPicksDaily – User-friendly design, fast site loading, very accessible.
шарики на день рождения остаются одним из самых популярных способов добавить ярких эмоций для любого торжества. Такие украшения позволяют подчеркнуть стиль мероприятия, делая праздник более памятным. Существует множество вариантов воздушных шаров, и каждый из них подходит для семейного торжества. Например, шары, наполненные гелием идеально подходят для наполнения пространства воздушностью и легкостью. Они могут быть в форме цифр, что позволяет создать тематическое оформление. Кроме того, популярностью пользуются металлизированные модели, которые отличаются большей долговечностью. Их часто выбирают для оформления детских праздников. Для любителей нежных оттенков подойдут легкие воздушные оттенки, которые создают мягкий визуальный эффект. Если вы хотите сделать праздник более выразительным, можно использовать арки и колонны, которые помогают оформить входную группу. Такие решения часто применяются как для домашних праздников, так и для мероприятий в кафе или студиях. Особое внимание стоит уделить сочетанию оттенков, ведь правильно подобранные цвета помогают сохранить целостность оформления. Важно учитывать возраст именинника, тематику праздника и освещение. Для маленьких детей отлично подходят яркие тематические наборы, а для взрослых — эстетичные цветовые сочетания. Не менее значимым элементом подготовки является выбор надежных моделей, поэтому следует отдавать предпочтение качественному латексу. Благодаря большому разнообразию шаров можно легко подобрать оформление под любой стиль, а при желании использовать персонализированные элементы для придания украшениям персонального характера. Правильное сочетание шаров, форм и цветов помогает превратить обычный день рождения в запоминающийся праздник, которое оставит приятные эмоции. Воздушные шары — это доступный и эффектный вариант оформления, подходящий для праздников любого формата.
https://www.panram.ru/partners/news/vozdushnye-shary-na-den-rozhdeniya-vidy-idei-i-sovety/
Today, I went to the beach front with my children. I found a sea shell and gave it to my 4 year old daughter and said "You can hear the ocean if you put this to your ear." She placed the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
Brasilia Sex Guide
HotTrendsToday – Attractive design, finding new items is effortless.
GFC Fashion Market – Good mix of clothing options, and navigation was simple.
Global Chic Store – Loved the overall vibe, and everything appeared quickly.
Top Deals Market – Easy navigation with many attractive deals visible immediately.
HomeGoodsVault – Wide selection of items and site navigation is seamless.
Discover Deals Picks – Quick navigation and great deals displayed clearly throughout.
SimpleLivingShop – Great variety of products, browsing felt smooth and comfortable.
Хочешь сайт в ТОП? накрутка пф яндекса для быстрого роста позиций сайта. Отбираем безопасные поведенческие сценарии, повышаем кликабельность и глубину просмотра, уменьшаем отказы. Тестовый запуск без оплаты, подробный отчёт по изменениям видимости.
Хочешь ТОП? сео продвижение сайта санкт-петербург как инструмент усиления SEO: эмуляция реальных пользователей, рост поведенческих факторов, закрепление сайта в ТОПе. Прозрачные отчёты, гибкая стратегия под нишу и конкурентов, индивидуальный медиаплан.
быстрая доставка праздничных воздушных шаров помогает сделать подготовку к мероприятию более удобной и приятной, ведь воздушные шары являются одним из самых эмоциональных и универсальных способов передать атмосферу радости для любого события. Они используются для создания праздничных композиций, позволяя легко преобразить зал, дом или открытую площадку. Разнообразие форм, цветов и размеров дает возможность подбирать индивидуальный стиль, превращая каждое торжество в особенный момент. Многие выбирают воздушные гелиевые композиции, которые эффектно смотрятся в интерьере и позволяют создавать красивые фотозоны. Такие шары могут быть в форме цифр и фигур, что дает возможность создать акцентные зоны. Для более выразительного оформления часто используют фольгированные шары, отличающиеся высокой прочностью и привлекательным блеском. Они становятся центром любой композиции и прекрасно сочетаются с шариками в классических цветах. Для тех, кто предпочитает мягкие тона, подойдут спокойные оттенки, создающие уютную атмосферу. Чтобы оформить крупные мероприятия, используют композиции на стойках, которые помогают структурировать пространство. Такие решения подходят для дней рождения, свадеб, корпоративов, выпускных и любых других торжеств, делая оформление выразительным. Цветовая гамма играет важную роль, поэтому важно учитывать стиль мероприятия. Например, для детских праздников идеально подходят красочные тематические наборы, а для взрослых — строгие цветовые сочетания. Дополнительным преимуществом является возможность создавать индивидуальные дизайны, что делает праздник еще более значимым. Воздушные шары способны преобразить любую площадку. Благодаря удобной доставке и большому выбору вариантов вы можете организовать праздник без хлопот. Независимо от повода, воздушные шары остаются символом праздника, способным подарить ощущение волшебства каждому гостю.
https://www.c-inform.info/news/id/112683
Modern Fashion Hub Deals – Stylish options throughout, and the site ran smoothly while browsing.
Комплексное продвижение сайта в сша: анализ конкурентов, стратегия SEO, локальное продвижение в городах и штатах, улучшение конверсии. Прозрачная отчетность, рост позиций и трафика из Google и Bing.
Современный офисы под ключ под ключ. Поможем обновить пространство, улучшить планировку, заменить покрытия, освещение и коммуникации. Предлагаем дизайн-проект, фиксированную смету, соблюдение сроков и аккуратную работу без лишнего шума.
ModernStyle Hub – Instant load times and a refined collection made the visit worthwhile.
TrendSetterHub – Loved the fast delivery and the items are super stylish, shopping was effortless.
Ставил ночью на австралийский футбол — всё приняли
TAB Style Hub – Loved the trendy selection, navigation through the site was effortless.
ModernStyleHub – Fashionable items came fast, and the overall shopping experience was great.
Rainy City Trend Hub – Items displayed nicely and the overall browsing flow felt comfortable.
TAB Online Store – Loved the mix of items, browsing experience was very straightforward.
Rainy City Showcase – Everything loaded quickly, and the well-structured layout made exploring enjoyable.
Нужно остекление? остекление балконов в самаре цены: тёплое и холодное, ПВХ и алюминий, вынос и объединение с комнатой. Бесплатный замер, помощь с проектом и документами, аккуратный монтаж и гарантия на конструкции и работу.
Online platform hypertrade swap for active digital asset trading: spot trading, flexible order settings, and portfolio monitoring. Market analysis tools and convenient access to major cryptocurrencies are all in one place.
Нужен керосин? авиационный керосин купить оптом сертифицированное топливо по ГОСТ, поставки для аэропортов, авиапредприятий и вертолётных площадок. Помощь в подборе марки, оформление документов и быстрая доставка.
Нужен манипулятор? кран манипулятор москва организуем подачу спецтехники на стройку, склад или частный участок. Погрузка, разгрузка, перевозка тяжёлых и негабаритных грузов. Оперативный расчёт стоимости и выезд в день обращения.
срочный заказ воздушных шаров — идеальный вариант для яркого оформления вашего мероприятия. Воздушные шары давно стали универсальным элементом декора, который подходит и для уютных домашних торжеств, и для больших мероприятий. Современные композиции из шаров впечатляют разнообразием форм и оттенков, что позволяет выбрать идеальный вариант под тему праздника. Для детских мероприятий чаще всего выбирают красочные гирлянды и фигуры, а во взрослых сценариях оформления чаще используются нежные оттенки и блестящий хром. Шары помогают создать многослойный и выразительный декор, которую можно адаптировать под фотозону, входную зону или оформление стола. Многие выбирают шары за их универсальность и доступность, ведь декор можно создать как из нескольких элементов, так и из масштабных арок и гирлянд. Также стоит отметить устойчивость и надежность современных шаров, что особенно важно для мероприятий на весь день. Во время выбора композиции важно учитывать цветовое решение, формат и настроение, чтобы итоговый декор гармонично вписался в пространство и подчеркнул атмосферу. При нехватке времени оптимально заказать оформление у опытных декораторов, которые быстро подготовят композицию и установят ее на месте. Красиво оформленные композиции из шаров задают атмосферу праздника, превращая обычное помещение в стильное и праздничное пространство.
https://parmanews.ru/novost/companynews/118583/
Comprehensive uae consulting: feasibility studies, market analysis, strategy, optimization of costs and processes. We help you strengthen your position in Dubai, Abu Dhabi and other Emirates.
школа трак диспетчинга в сша для русскоязычных онлайн обучение диспетчера грузоперевозок в сша для начинающих
толстый кот краби трансфер краби
GFC Style Market – Loved how fast the site moved, plus the style range was impressive.
GFC Style Market – Loved how fast the site moved, plus the style range was impressive.
wildorchardlane – Fast navigation with tidy pages, browsing felt natural and quick.
Growth Hub Online – Simple navigation and highly useful content throughout.
orchardtrendstore – Well-structured pages and easy-to-find items, shopping felt effortless.
Discover Growth Portal – Well-laid-out pages with very useful information.
Профессиональное интернет маркетинговое агентство: аудит, позиционирование, digital-стратегия, запуск рекламных кампаний и аналитика. Поможем вывести бренд в онлайн, увеличить трафик и заявки из целевых каналов.
Профессиональная перевозка больных из больницы домой подъем на этаж, помощь при пересадке, фиксирующие носилки, заботливое отношение. Организуем транспортировку в больницы, реабилитационные центры и домой.
Нужна ботулинотерапия? диспорт для лица цена в косметологии помогаем смягчить мимику, освежить взгляд и предупредить появление новых морщин. Осмотр врача, противопоказания, грамотное введение и контроль результата на приёме.
Silver Garden Mart Site – The pages worked smoothly, leaving a professional and consistent impression.
Aw, this was a very nice post. Taking the time and actual effort to generate a top notch article… but what can I say… I put things off a lot and never seem to get nearly anything done.
Rio Sex Guide
Silver Garden Collections – Everything ran smoothly, and the store felt organized and reliable.
EverydayLivingShop – Lovely assortment of products, browsing felt natural and fast.
SimpleLivingFinds – Items look great, navigating through pages was easy.
Нужен бетон? куплю бетон с доставкой о выгодной цене с доставкой на объект. Свежий раствор, точное соблюдение пропорций, широкий выбор марок для фундамента, стяжек и монолитных работ. Быстрый расчет, оперативная подача миксера.
Trading platform hyperliquid dex list combines a user-friendly terminal, analytics, and portfolio management. Monitor quotes, open and close trades, and analyze market dynamics in a single service, available 24/7.
Use hyperliquid aggregator to manage cryptocurrencies: a user-friendly dashboard, detailed statistics, and trade and balance tracking. Tools for careful risk management in a volatile market.
яркие воздушные шары с быстрой доставкой — это только малая часть того, что предлагает универсальный онлайн-портал для молодожёнов Смоленска. Здесь собраны лучшие идеи для подготовки торжества, а также проверенные контакты свадебных специалистов, чтобы каждая пара смогла создать атмосферу, отражающую их стиль. На портале вы найдете все о параде невест в Смоленске, который ежегодно собирает лучшие свадебные команды и фотографов. Это событие стало главной визитной карточкой городских свадебных мероприятий. Для тех, кто планирует торжество, портал предлагает подборку профессиональных фотографов для свадеб, а также рекомендации по подбору локаций и стиля. Специальные материалы помогут определиться, какой ресторан или банкетный зал выбрать. Представлены обзоры популярных площадок, чтобы каждая пара могла подобрать идеальный вариант. На портале также доступны сообщества смолянок, обсуждающих важные темы, где можно узнать реальные отзывы с теми, кто уже прошел путь подготовки к свадьбе. А свежие городские события помогут оставаться в курсе всего, что может заинтересовать будущих молодожёнов. Сайт создан как центр помощи при планировании торжества, поэтому здесь собрано все для создания стильного торжества: от подбора украшений до вариантов сценариев. Благодаря удобной структуре и регулярному обновлению информации портал стал главным помощником будущих супругов, помогая делать важный день по-настоящему особенным.
https://svadba67.ru/
InnerStrengthGuide – Pleasant visuals, clear navigation, and motivating resources.
Живое видео в лайве с минимальной задержкой, удобно ловить движения кэфов
EmpowerHub – Positive layout, simple navigation, and uplifting site vibe.
The best deepnude ai services for the USA. We'll explore the pros and cons of each service, including speed, available effects, automation, and data privacy. Undress people in just a few clicks.
Modern Product Market – The smooth flow of the site made checking out products very easy.
TrendCorner Market – A clean, neat interface and interesting pieces across categories.
Trend Buy Finds – Items showcased nicely, exploring the site was quick and easy.
VIP escort in London, more details here: escort london elite Confidentiality and high level of service.
SoftGroveCorner Catalog – Everything was easy to locate thanks to the tidy interface.
Trend & Buy Picks – Nice display of items, navigation was clear and simple.
Flora Collection Store – Great mix of nature-inspired products and a friendly, flowing interface.
SoftGroveCorner Finds – Everything was easy to find and the site layout felt smooth.
Rare Botanical Picks – Nice floral-themed pieces, and the smooth layout made exploring pleasant.
Consistent engagement maintains when you buy tiktok likes and likes regularly across content. Uniform interaction signals establish reliable engagement patterns supporting algorithmic promotion decisions.
Официальная кракен ссылка из всплывающего окна содержит все актуальные онион адреса и клир-зеркала для множественных точек доступа к маркету.
Независимая верификация подтверждает проверенная кракен ссылка через сравнение адресов минимум в трех различных источниках и обязательную GPG проверку цифровых подписей администрации.
ChoiceCornerOnline – Excellent selection and very easy to find exactly what I needed.
GMC Marketplace – Easy to navigate thanks to the clean organization across the site.
Simple phrasing allows tiktok likes buy quick discovery. Clear service descriptions facilitate efficient matching between providers and creators seeking specific engagement types.
SmartChoiceSpot – Excellent options and very easy to navigate, found everything I wanted.
Daily Fresh Deals – Good daily highlights with a layout that keeps navigation clear.
GMC Product Hub – Clear sections throughout, so locating what I needed took no time.
Новинний портал Ужгорода https://88000.com.ua головні події міста, політика, економіка, культура, спорт та життя городян. Оперативні новини, репортажі, інтерв'ю та аналітика. Все важливе про Ужгород в одному місці, зручно з телефону та комп'ютера.
Fresh Update Market – Everything is arranged in a clean way, and navigating feels effortless.
Официальный kraken onion адрес версии v3 содержит 56 символов для максимальной криптографической защиты соединения внутри распределенной Tor сети анонимизации.
Обновленный kra48 адрес обеспечивает стабильное соединение с маркетплейсом через автоматическое перенаправление на актуальный защищенный онион адрес в сети.
Новинний портал Ужгорода https://88000.com.ua головні події міста, політика, економіка, культура, спорт та життя городян. Оперативні новини, репортажі, інтерв'ю та аналітика. Все важливе про Ужгород в одному місці, зручно з телефону та комп'ютера.
A cozy hotel in Kolasin for mountain lovers. Ski slopes, trekking trails, and local cuisine are nearby. Rooms are equipped with amenities, Wi-Fi, parking, and friendly staff are available to help you plan your vacation.
A cozy Kolasin Montenegro hotels for mountain lovers. Ski slopes, trekking trails, and local cuisine are nearby. Rooms are equipped with amenities, Wi-Fi, parking, and friendly staff are available to help you plan your vacation.
Hi i am kavin, its my first time to commenting anyplace, when i read this paragraph i thought i could also make comment due to this brilliant post.
Find Female Escorts Brazil
Timber Path Collections – Easy-to-use layout and well-structured categories enhanced the browsing experience.
Timber Path Online – Clear structure and responsive navigation made exploring the store effortless.
Global Season Shop – Loved the seasonal selections here, everything was easy to explore.
TSZ Fashion Picks – Trendy products arranged neatly, navigation was simple and fast.
GSS Shop Seasons – Everything was neatly arranged, making the seasonal browsing smooth.
TSZ Style Shop – Stylish products displayed nicely, exploring items was simple and quick.
Rare Line Essentials – Smooth navigation paired with interesting items made exploring fun.
Rare Picks Corner – Items were well-presented, and moving between categories was easy.
FreshItemsHub – Clean layout, easy-to-find products, and a seamless interface.
FreshDailyFinds – Clear interface, enjoyable browsing, and well-organized product pages.
Линия на бокс и ММА одна из самых широких
CalmMarketplaceOnline – Effortless browsing and quick delivery, highly recommend.
SimpleTradeSpot – Fast delivery and seamless navigation, I’ll definitely return for more.
v
v
RiverLeaf Collections – Pleasant experience exploring the site, everything loaded quickly.
RiverLeaf Treasure – Very smooth experience, exploring the site felt effortless and pleasant.
ExploreOpportunities Shop – Clear categories with responsive pages made exploring effortless.
FreshDaily Finds – Great new picks and a user-friendly flow throughout the site.
Opportunities Hub Picks – Organized sections and easy-to-follow layout for quick browsing.
Fresh Picked Store – Everything displays clearly, and navigating the categories is quick and easy.
SLC Living Goods – Relaxing design and intuitive navigation made browsing enjoyable.
TimelessFinds – Smooth browsing experience with stylish items clearly displayed.
SLC Lifestyle Store – Minimalist setup that helped me find what I wanted without hassle.
ChicVault – Attractive products and smooth navigation make exploring enjoyable.
Pure Harbor Picks – Navigation was simple and I could locate items effortlessly.
Trend Choice Shop Online – Nice selection of products, navigation around the site was simple.
Casino utan registrering https://casino-utan-registrering.se bygger pa en snabbare ide: du hoppar over kontoskapandet och gar direkt in via din bank-ID-verifiering. Systemet ordnar uppgifter och transaktioner i bakgrunden, sa anvandaren mots av en mer stromlinjeformad start. Det gor att hela upplevelsen far ett mer direkt, tekniskt och friktionsfritt upplagg utan extra formular.
Explore PureHarborStudio – The site felt intuitive and navigating products was easy.
Trend Choice Online – Well-organized items, moving between pages was very smooth.
I casino crypto https://crypto-casino-it.com sono piattaforme online che utilizzano valute digitali per transazioni rapide e sicure. Permettono di vedere in pratica i vantaggi della blockchain: trasparenza dei processi, assenza di intermediari, trasferimenti internazionali agevoli e un’interfaccia moderna, pensata per un’esperienza tecnologica degli utenti.
Casino utan svensk licens https://casinos-utan-licens.se ar onlineplattformar som drivs av operatorer med licens fran andra europeiska jurisdiktioner. De erbjuder ofta ett bredare utbud av tjanster och anvander egna regler for registrering och betalningar. For spelare innebar detta andra rutiner for sakerhet, verifiering och ansvarsfullt spelande.
Free Online Jigsaw Puzzle https://podcasts.apple.com/ro/podcast/the-benefits-of-puzzles/id1698189758?i=1000738880405 play anytime, anywhere. Huge gallery of scenic photos, art and animals, customizable number of pieces, autosave and full-screen mode. No registration required – just open the site and start solving.
RiverLeaf Outlet – Well-organized product sections and quick-loading pages enhanced browsing.
EverNova Browse – The visual appeal was great, and everything was laid out in a way that felt natural.
Leaf Market Spot – The site felt calm and easy to move through, with clear product display.
Shop EverNova – I liked the stylish design, and the whole browsing experience felt effortless.
Free Online Jigsaw Puzzle https://el.gravatar.com/smsspy play anytime, anywhere. Huge gallery of scenic photos, art and animals, customizable number of pieces, autosave and full-screen mode. No registration required – just open the site and start solving.
шары с гелием с доставкой — это удобный способ оформить событие без лишних хлопот, выбрав подходящую композицию. Мы предлагаем широкий выбор тематических шаров, которые подойдут для детского праздника или декора фотозоны. Благодаря надежной фиксации каждого шара композиции сохраняют форму и яркость на протяжении долгого времени, позволяя наслаждаться ими как можно дольше. Наши специалисты помогут собрать индивидуальный комплект, ориентируясь на ваши предпочтения. Варианты включают фольгированные шары с фигурами персонажей, а также наполненные конфетти. Мы работаем так, чтобы заказ приходил точно ко времени, поэтому каждый заказ тщательно проверяется перед отправкой. Курьер привозит шары уже надутыми гелием, что позволяет сразу использовать их для оформления. Наш сервис ориентирован на тех, кто ценит скорость, поэтому каждая заявка обрабатывается без задержек. Мы предлагаем эксклюзивные коллекции, чтобы ваш праздник стал ярким и запоминающимся. Если вам нужны композиции для предложения руки и сердца, у нас есть подходящие варианты. Для больших мероприятий доступны оформление залов, которые выполняются в согласованный срок. Мы стремимся сделать так, чтобы ваше событие выглядело идеально, а гелиевые шары становились основой праздничного настроения. Заказывая у нас, вы получаете бережную доставку, способные украсить любой праздник.
https://altsvadba.ru/
A cozy swissotel Kolasin for mountain lovers. Ski slopes, trekking trails, and local cuisine are nearby. Rooms are equipped with amenities, Wi-Fi, parking, and friendly staff are available to help you plan your vacation.
трансы волгоград Социальный климат в Волгограде, как и во многих российских регионах, характеризуется неоднозначностью. С одной стороны, есть люди, готовые к принятию и поддержке, а с другой – сильны консервативные взгляды, которые создают напряжение и дискомфорт для тех, кто не соответствует общепринятым нормам. В таких условиях важную роль играют онлайн-сообщества, где транс-персоны могут найти единомышленников, поделиться опытом и получить необходимую информацию.
A cozy hotel Bjanka Kolasin for mountain lovers. Ski slopes, trekking trails, and local cuisine are nearby. Rooms are equipped with amenities, Wi-Fi, parking, and friendly staff are available to help you plan your vacation.
RiverLeaf Store – User-friendly layout, browsing through products was effortless.
GiftMarketplace – Clean design, organized categories, and smooth navigation experience.
RiverLeaf Goods – Effortless browsing, and the marketplace felt welcoming today.
AllGiftShop – Clean pages, easy-to-browse layout, and wide selection of items.
STB Trendy Finds – Lots of appealing discounts, and the interface felt very responsive.
STB Fresh Trends – Good mix of updated trends, and browsing took almost no effort.
JungleSelectHub – Smooth navigation with an excellent range of items, truly a pleasant experience.
RainforestGoods – Easy-to-use site and a wide selection of items, very happy with my visit.
Explore Hub Picks – Easy navigation and clearly organized content enhanced the experience.
ExploreOpportunities Online – Clean layout and easy access to all resources made browsing enjoyable.
ClassicVault – Fast pages and well-organized items make shopping smooth and enjoyable.
ElegantFinds – Fast site performance with well-presented fashion products.
доставка праздничных шаров в Москве могут дополнить любой праздник, однако если вы хотите порадовать ребенка чем-то особенным, обратите внимание на наш онлайн-магазин игрушек для детей, где собраны востребованные товары для детей разных возрастов. Мы предлагаем большой выбор развивающих и игровых наборов, включающий коллекции по мотивам известных мультфильмов, а также игрушки для малышей. Каждая позиция проходит отбор по безопасности, чтобы родители могли быть уверены в безопасности товаров. Мы следим за тем, чтобы ассортимент удовлетворял запросы детей и взрослых, предлагая игрушки для развития моторики, а также подарочные комплекты. Наша задача — предоставить приятные условия покупки, чтобы каждый мог выбрать интересный набор без переплат. В каталоге представлены развлекательные наборы, которые помогут поддерживать интерес ребенка к обучению. Мы внимательно относимся к тому, чтобы информация о каждом товаре была максимально точной, поэтому на странице товара доступно рекомендуемый возраст. Наш интернет-магазин работает для покупателей из всех регионов, предлагая доставку по России. Это означает, что вы можете получить заказ максимально быстро, не выходя из дома. Мы отправляем товары с защитными материалами, чтобы каждая игрушка приехала в идеальном состоянии. Для тех, кто ищет подарок на праздник, доступны популярные категории, которые помогут найти оптимальный вариант. Мы стремимся сделать процесс покупки максимально простым, поэтому на сайте реализованы быстрый поиск, позволяющие легко ориентироваться среди большого разнообразия товаров. Наша команда регулярно обновляет каталог, добавляя новые линейки, чтобы дети могли получать трендовые игрушки, а родители — экономить время и силы. Делая заказ у нас, вы выбираете выгодные условия, а также получаете возможность подарить ребенку эмоции с помощью правильно подобранных игрушек.
https://happykidtoys.ru/
Explore hyperliquid arbitrage finder and gain unlimited access to a modern, decentralized market. Trade derivatives, manage your portfolio, utilize analytics, and initiate trades in a next-generation ecosystem.
Choose hyperliquid dex as a convenient tool for trading and investing. The platform offers speed, reliability, advanced features, and fair pricing for cryptocurrency trading.
Discover hypertrade aggregator a platform for fast and secure trading without intermediaries. Gain access to innovative tools, low fees, deep liquidity, and a transparent ecosystem for working with digital assets.
Use hyperliquid dex list for stable and efficient trading. The platform combines security, high liquidity, advanced solutions, and user-friendly functionality suitable for both beginners and professional traders.
Перед перечнем поясним логику: домашний визит уместен, когда обстановка безопасна, риски контролируемы и есть взрослый помощник на вечер и ночь. Ниже — ориентиры, при которых имеет смысл начать с выезда, а не со стационара.
Подробнее тут - https://narkolog-na-dom-voskresensk8.ru/vyzov-narkologa-na-dom-v-voskresenske
Trend Collection Shop Online – Loved the modern setup, browsing felt effortless and smooth.
TCS Online Store Hub – Loved the layout and modern design, browsing items was simple.
Choose hyperliquid dex list — a platform for traders who demand speed and control: over 100 pairs per transaction, flexible orders, HL token staking, and risk management tools. Support for algorithmic strategies and advanced analytics.
Simple Fashion Finds – Clean design and effortless browsing make exploring the store enjoyable.
Check out hyper trading, a modern DEX with its own L1: minimal fees, instant order execution, and on-chain transparency. Ideal for those who want the speed of a CEX and the benefits of decentralization.
Открываешь бизнес? открытие бизнеса в оаэ полный пакет услуг: консультация по структуре, подготовка и подача документов, получение коммерческой лицензии, оформление рабочих виз, помощь в открытии корпоративного счета, налоговое планирование и пострегистрационная поддержка. Гарантия конфиденциальности.
Decor Choice Store – Smooth page transitions and a refreshing set of home décor options.
Trend Finds Corner – Browsing is easy and the products are displayed attractively.
Хотите открыть компанию оаэ? Предоставим полный комплекс услуг: выбор free zone, регистрация компании, лицензирование, визовая поддержка, банковский счет и бухгалтерия. Прозрачные условия, быстрые сроки и сопровождение до полного запуска бизнеса.
Наша задача — не ограничиться «одной капельницей», а провести пациента через связанный маршрут: купирование острых симптомов, стабилизация, профилактика срывов и поведенческая поддержка. На выезде врач оценивает давление, пульс, сатурацию, при необходимости снимает ЭКГ, подбирает инфузионные схемы и корректирует тревогу, тремор, нарушение сна. Если состояние нестабильно, организуем стационар: под наблюдением легче предупреждать осложнения и быстро корректировать назначенные дозы. Когда острые проявления уходят, настраиваем режим сна, питания и гидратации, формируем план «сложных часов» и алгоритм раннего реагирования на тягу. Психотерапевтические сессии усиливают контроль над поведением, а семейные консультации помогают близким действовать согласованно, не усиливая зависимое поведение случайными ошибками вроде «спасательства» и скрытия последствий употребления.
Исследовать вопрос подробнее - https://narkologicheskaya-klinika-moskva99.ru/horoshaya-narkologicheskaya-klinika-v-moskve
Modern Home Outlet – A tidy layout paired with simple navigation made shopping easy today.
Цель
Получить больше информации - [url=https://narkolog-na-dom-voskresensk8.ru/]narkolog-voskresensk[/url]
Маршрут помощи строится вокруг конкретных задач безопасности. С первого звонка администратор собирает короткий чек-лист: длительность нынешнего эпизода, что принималось в последние двое суток, хронические заболевания, аллергии, как прошла ночь, есть ли помощник на вечер и ночь. Дежурный врач, опираясь на эти данные, предлагает стартовый формат — выезд на дом по Воскресенску и району или немедленную госпитализацию. Решение привязывается к реальным рискам: стабильность давления и пульса, выраженность тремора и тошноты, эпизоды судорог в прошлом, возможность обеспечить «тихий режим» в квартире. После очной оценки и допуска к терапии мы запускаем детокс, а по завершении визита фиксируем правила на 24–48 часов и контрольные точки. Если состояние колеблется, сразу обсуждаем повторный контакт либо перевод в стационар, не теряя часы на бюрократию.
Ознакомиться с деталями - [url=https://narkologicheskaya-klinika-voskresensk8.ru/]narkologicheskaya-klinika-voskresensk8.ru/[/url]
Simple Value Picks – Enjoyed how everything was grouped, making comparison super simple.
RusticField Selection – Easy to browse, with a warm and cozy feel throughout the site.
Прежде чем перечислить критичные признаки, зафиксируем принцип: даже один выраженный симптом — повод не откладывать помощь и выбрать безопасный маршрут (дом или стационар) после быстрой очной оценки врача.
Получить дополнительные сведения - [url=https://vyvod-iz-zapoya-sergiev-posad8.ru/]vyvod-iz-zapoya-sergiev-posad8.ru/[/url]
Simple Value Picks – Enjoyed how everything was grouped, making comparison super simple.
RusticField Emporium Online – Smooth and easy navigation, rustic items beautifully displayed throughout the store.
נתוני הרישוי הוא אחד הצעדים הראשונים שכל קונה רכב בישראל צריך לבדוק לפני קבלת החלטה. הפרטים מאפשרים להבין את מצבו האמיתי של הרכב ולמנוע הפתעות. בדיקת רכב מקיפה בישראל הפכה לכלי חובה לקונים פרטיים. בדיקה טכנית מאפשרת לזהות בעיות נסתרות שלא רואים בעין. בחינת שלדה, כריות אוויר ומערכות בלימה היא חובה לפני קנייה. הבדיקה כוללת סקירה של חיווטים, חיישנים ומערכות ניהול מנוע. בדיקה מוקדמת מגלה תקלות שיכולות לעלות אלפי שקלים. במהלך נסיעה ניתן להרגיש את תגובת המנוע, תיבת ההילוכים והבלמים. בדיקת מחשב מתקדמת מאפשרת קריאת נתוני מנוע וחשיפת תקלות נסתרות. היעדר תיעוד עשוי להצביע על תחזוקה לקויה. מכון מקצועי מספק בדיקה אובייקטיבית ואמינה. בסיום הבדיקה מקבל הקונה דו״ח מפורט עם ציונים, ליקויים והמלצות. מי שמבצע את כל שלבי הבדיקה מגדיל משמעותית את הביטחון ברכישה. בשל ריבוי התאונות והתיקונים, בדיקה היא שלב קריטי שאין לדלג עליו. כך ניתן לרכוש רכב משומש בישראל בביטחון מלא וללא סיכונים מיותרים.
https://ashkelonim.co.il/%d7%a6%d7%a8%d7%9b%d7%a0%d7%95%d7%aa-%d7%aa%d7%95%d7%9b%d7%9f-%d7%a9%d7%99%d7%95%d7%95%d7%a7%d7%99/%d7%91%d7%93%d7%99%d7%a7%d7%aa-%d7%a8%d7%9b%d7%91-%d7%91%d7%99%d7%a9%d7%a8%d7%90%d7%9c-%d7%9e%d7%93%d7%a8%d7%99%d7%9a-%d7%9e%d7%a7%d7%99%d7%a3-%d7%9c%d7%a8%d7%9b%d7%99%d7%a9%d7%94-%d7%91%d7%98%d7%95%d7%97%d7%94-706243
Городская среда Воронежа — яркие подъезды, плотный трафик, шумные дворы — усиливает вечернюю реактивность. Поэтому выездная служба «ВоронежВита» организована «тихо»: согласованная парковка, быстрый подъем без опознавательных знаков, часть расходников доставляется заранее, чтобы на адресе сразу перейти к диагностике и инфузии. Коммуникация ведётся через защищённые каналы, уведомления — «беззвучные», названия в документах — нейтральные. Такой дизайн среды не декоративен: чем меньше «социального шума», тем устойчивее ночной сон и тем быстрее возвращается переносимость воды и лёгкой еды.
Получить больше информации - [url=https://vivod-iz-zapoya-voronezh15.ru/]вывод из запоя капельница[/url]
Предлагаем создание холдингов оаэ для международного бизнеса: подбор free zone или mainland, разработка структуры владения, подготовка учредительных документов, лицензирование, банковское сопровождение и поддержка по налогам. Конфиденциальность и прозрачные условия работы.
Хочешь фонд? личные фонды оаэ — безопасный инструмент для защиты активов и наследственного планирования. Помогаем выбрать структуру, подготовить документы, зарегистрировать фонд, обеспечить конфиденциальность, управление и соответствие международным требованиям.
Профессиональное учреждение семейных офисов оаэ: от разработки стратегии управления семейным капиталом и выбора юрисдикции до регистрации, комплаенса, настройки банковских отношений и сопровождения инвестиционных проектов. Полная конфиденциальность и защита интересов семьи.
Хотите открыть счёт? открытие счета в оаэ Подбираем оптимальный банк, собираем документы, готовим к комплаенсу, сопровождаем весь процесс до успешного открытия. Поддерживаем предпринимателей, инвесторов и резидентов с учётом всех требований.
География накладывает отпечаток на клинические решения. Длинные сумерки, переменчивый ветер с акватории и «звонкие» подъезды старого фонда увеличивают чувствительность к свету и шуму, а значит — усиливают вечернюю кардиолабильность. В «АрктикМед Профи» протоколы адаптированы под такой фон: в палатах преобладают тёплые источники света, на обходах персонал работает в «режиме тишины», в смартфонах включается «без уведомлений», а выездные бригады заходят в дом максимально незаметно. Такой «мягкий» сценарий делает помощь не только деликатной, но и клинически эффективной — снижается потребность в «сильных» седативных вмешательствах, сохраняется физиологичность сна.
Изучить вопрос глубже - [url=https://narkologicheskaya-klinika-v-murmanske15.ru/]наркологическая клиника нарколог мурманск[/url]
Нужна виза инвестора в оаэ? Подберём оптимальный вариант — через бизнес, долю в компании или недвижимость. Готовим документы, сопровождаем на всех этапах, обеспечиваем корректное прохождение комплаенса и получение резидентского статуса.
Профессиональное налоговое консультирование оаэ: разбираем вашу ситуацию, подбираем оптимальную корпоративную и личную структуру, помогаем учесть требования местного законодательства, корпоративного налога и substance. Сопровождаем бизнес и инвестиции на постоянной основе.
Оформление золотая виза оаэ под ключ: анализ вашей ситуации, подбор оптимальной категории (инвестор, бизнес, квалифицированный специалист), подготовка документов, сопровождение подачи и продления статуса. Удобный формат взаимодействия и конфиденциальный сервис.
Комплексные бухгалтерский учет в оаэ: финансовая отчётность, налоговые декларации, управление первичными документами, аудит, VAT и corporate tax. Обеспечиваем точность, своевременность и полное соответствие законодательству для стабильной работы вашего бизнеса.
trendsettershop – Easy navigation and neat product lists, very user-friendly.
Growth Potential Portal – The site felt organized and the content inspiring from start to finish.
Детокс — это не один раз «поставить капельницу», а последовательность: допуск к терапии, коррекция жидкости и электролитов, поддержка органов-мишеней, симптом-контроль, профилактика осложнений, переоценка и настройка схемы. Мы заранее закладываем точку повторной оценки, потому что абстинентные проявления изменчивы: тремор и тревога могут уходить волнообразно, давление — «гулять» на фоне усталости и недосыпа. Врач видит динамику и либо переводит на пероральные схемы, либо усиливает наблюдение, рекомендуя стационар. Параллельно настраиваем «бытовой контур» — сон по расписанию, вода малыми порциями, лёгкое дробное питание, ограничение эмоциональных перегрузок и перенос встреч, где сложно отказать.
Исследовать вопрос подробнее - http://narkologicheskaya-klinika-voskresensk8.ru
Growth Vision Hub – Pleasant browsing experience and encouraging material throughout.
shopcentral – Well-arranged product pages, made shopping fast and easy.
Shop Collective Fashion – Modern layout with speedy browsing made checking items effortless.
StreetStyleVault – Stylish products presented nicely and site navigation is smooth.
Collective Fashion Select – The catalog felt organized, and pages responded very quickly.
Наркологическая клиника «РеМед Карелия» — это круглосуточная медицинская помощь, построенная на принципе клинической точности: каждая процедура имеет цель, проверяемые маркеры и назначенное окно переоценки. Мы используем современные методы детоксикации и постабстинентной стабилизации, не перегружая терапию «на всякий случай» и не полагаясь на универсальные «сильные капельницы». Вместо этого — модульные схемы, корректировка одного параметра за раз и обязательная оценка результата. Такой подход снижает фармаконагрузку, ускоряет восстановление сна и аппетита и делает лечение предсказуемым для пациента и его семьи. Анонимность встроена в процессы: немаркированные входы, гражданская форма персонала, нейтральные формулировки в документах, «тихие» уведомления и разграниченный доступ к карте наблюдения.
Детальнее - http://narkologicheskaya-klinika-v-petrozavodske15.ru/narkolog-petrozavodsk-otzyvy/
HomeTrendyPicks – Clean design, smooth navigation, and attractive decor products.
Профессиональная легализация документов в оаэ: нотариальное заверение, Минюст, МИД, консульства, сертифицированные переводы. Сопровождаем весь процесс от проверки документов до финального подтверждения. Подходит для компаний, инвесторов и частных клиентов.
Профессиональное консульское сопровождение оаэ для частных лиц и бизнеса: консультации по визовым и миграционным вопросам, подготовка обращений, запись в консульство, помощь при подаче документов и получении решений. Минимизируем риски отказов и задержек.
Предлагаем корпоративные услуги в оаэ для действующих и новых компаний: регистрация и перерегистрация, выпуск и передача долей, протоколы собраний, обновление лицензий, KYC и комплаенс. Обеспечиваем порядок в документах и соответствие требованиям регуляторов.
StreetStyleVault – Stylish products presented nicely and site navigation is smooth.
Помогаем открыть брокерский счет в оаэ: подбор надёжного брокера, подготовка документов, прохождение KYC, сопровождение подачи и активации. Подходит для частных инвесторов, семейных офисов и компаний. Доступ к мировым рынкам и комфортные условия работы с капиталом.
CityTrendHub – Easy navigation and quick checkout, a very satisfying shopping experience.
TrendyDecorSpot – Smooth layout, attractive visuals, and effortless browsing experience.
UrbanSelectOnline – Fast and easy shopping, very happy with how smooth everything was.
Главная задача — вернуть контроль над самочувствием мягко и последовательно. Мы не соревнуемся в дозах, а собираем устойчивую траекторию улучшения: каждый модуль терапии отвечает за одну цель и имеет своё «окно оценки». Если отклик ниже ожиданий — меняем ровно один параметр (темп, последовательность или поведенческий элемент среды), чтобы точно понимать, что помогло.
Подробнее можно узнать тут - вывод из запоя дешево
Прежде чем перечислить критичные признаки, зафиксируем принцип: даже один выраженный симптом — повод не откладывать помощь и выбрать безопасный маршрут (дом или стационар) после быстрой очной оценки врача.
Углубиться в тему - [url=https://vyvod-iz-zapoya-sergiev-posad8.ru/]vyvod-iz-alkogolnogo-zapoya-v-domashnih-usloviyah[/url]
¿Tus amistades se distanciaron desde que estás con él? Señal de alerta https://lasmujeresqueamandemasiadopdf.cyou/ citas las mujeres que aman demasiado frases
TDP Online Deals – Great selection of offers, navigating the site felt fast and effortless.
TDP Shop Picks – Deals showcased nicely, moving through sections felt simple and quick.
Нужна поддержка по трудовым вопросам оаэ? Консультируем по трудовым договорам, рабочим визам, оформлению сотрудников, переработкам, отпускам и увольнениям. Готовим рекомендации, помогаем минимизировать риски штрафов и конфликтов между работодателем и работником.
Мытищи дают логистические плюсы домашнего старта: меньше перемещений, приватнее, быстрее включается режим. Дом уместен, если нет упорной рвоты, высокой температуры, выраженной дезориентации, резких «качелей» давления/пульса, признаков обезвоживания с угрозой судорог. Если же состояние «по краю» — сочетание рвоты, лихорадки, кардиальных жалоб, второй бессонной ночи, выраженного тремора — врач предложит короткую стационарную стабилизацию на 24–48 часов под круглосуточным наблюдением. Это честнее и, на дистанции, экономнее: дефициты закрываются быстрее, дозы подбираются точнее, первая ровная ночь достигается предсказуемо, а риск экстренных ночных выездов снижается. В любом варианте приватность сохраняется: немаркированные визиты, индивидуальные окна, закрытые каналы коммуникации, доступ к данным по ролям.
Подробнее тут - [url=https://narkolog-na-dom-mytishchi9.ru/]нарколог на дом мытищи[/url]
Home Essentials Point – The catalog felt neatly arranged, and pages loaded without any hassle.
Smart Living Online – Loved the modern living selections, with well-arranged sections.
Разработка соглашения об управлении оаэ: фиксируем правила принятия решений, распределение ролей, отчётность и контроль результатов. Учитываем особенности вашей компании, отрасли и требований регуляторов. Помогаем выстроить устойчивую систему корпоративного управления.
DecorSelect Hub – Loved the polished feel of the design and the simple category structure.
SLM Home Picks – Plenty of smart-living items, and moving around the site felt seamless.
экскурсия на остров краби ко ланта пляжи
Разрабатываем опционные планы в оаэ под ключ: анализ корпоративной структуры, выбор модели vesting, подготовка опционных соглашений, настройка механики выхода и выкупа долей. Помогаем выстроить прозрачную и понятную систему долгосрочной мотивации команды.
Corporate company bank account opening in uae made simple: we help choose the right bank, prepare documents, meet compliance requirements, arrange interviews and support the entire onboarding process. Reliable assistance for startups, SMEs, holding companies and international businesses.
Get your uae golden visa with full support: we analyse your profile, select the right category (investor, business owner, specialist), prepare a compliant file, submit the application and follow up with authorities. Transparent process, clear requirements and reliable guidance.
RusticTrade Deals – Pleasant and responsive, browsing the marketplace felt effortless.
RusticTrade Shoppe – Pleasantly simple interface, site works flawlessly and items are easy to find.
Страх огласки часто тормозит обращение сильнее симптомов. В «Трезвый Пульс» приватность — регламент: подтверждения и согласия — только через защищённые каналы, в расписании — шифры, визиты — без маркировки. Мы заранее согласуем маршрут подъезда и входа, учитывая дворовые проезды и часы пик, чтобы врач не искал дом по навигатору в последнюю минуту. Чем меньше холостых перемещений и социальных контактов, тем ниже тревога, выше приверженность режиму и устойчивее эффект терапии. Такой порядок особенно важен в «тёмные часы» вечера, когда склонность к импульсивным решениям максимальна — отсутствие лишнего шума помогает телу переключиться на восстановление, а не на самооборону.
Исследовать вопрос подробнее - [url=https://narkolog-na-dom-mytishchi9.ru/]www.domen.ru[/url]
Professional business setup uae: advisory on jurisdiction and licence type, company registration, visa processing, corporate bank account opening and ongoing compliance. Transparent costs, clear timelines and tailored solutions for your project.
Comprehensive consular support uae: embassy and consulate liaison, legalisation and attestation of documents, visa assistance, translations and filings with local authorities. Reliable, confidential service for expatriates, investors and corporate clients.
Comprehensive tax consultant dubai: advisory on corporate tax, VAT, group restructuring, profit allocation, substance and reporting obligations. We provide practical strategies to optimise taxation and ensure accurate, compliant financial management.
Trusted accounting firm uae providing bookkeeping, financial reporting, VAT filing, corporate tax compliance, audits and payroll services. We support free zone and mainland companies with accurate records, transparent processes and full regulatory compliance.
Want to obtain an investor visa uae? We guide you through business setup or property investment requirements, prepare documentation, submit your application and ensure smooth processing. Transparent, efficient and tailored to your goals.
Daily Motivation Corner – Encouraging pages with neat structure and easy-to-use navigation.
Домашний формат уменьшает стресс и экономит время: не нужно ехать в клинику, скрывать визит от соседей или ждать в очереди. Врач приезжает без опознавательных знаков и не создаёт «медицинского шума». За один визит удаётся снять острые проявления, выстроить понятный план ночи и следующего утра, а также определить, нужна ли дополнительная диагностика. Такой маршрут часто оказывается короче и эффективнее, чем череда попыток «пересидеть» симптомы без медицинской поддержки.
Разобраться лучше - http://narkolog-na-dom-voskresensk8.ru
Stay Positive Hub – Layout is neat, content feels encouraging, and navigation is simple.
«ГородМед Трезвость» выстраивает помощь так, чтобы человек не оставался один ни на этапе выхода из запоя, ни во время стабилизации, ни в период удержания ремиссии. С первого звонка дежурный врач проводит короткое интервью, фиксирует жалобы, длительность употребления, сопутствующие болезни и текущие препараты, после чего предлагает безопасную точку входа — экстренный выезд на дом или приём без ожидания. Мы не растягиваем процесс по неделе: старт возможен в день обращения, а маршрутизация между форматами (дом, амбулаторный визит, стационар) занимает часы. Важная часть подхода — ясные цели каждого шага и критерии эффективности, понятные самому пациенту и семье: когда ждать облегчения тревоги, как нормализуется сон, когда вернётся аппетит, что считается «красным флажком» и как действовать без паники. Такая предсказуемость снижает уровень стресса и повышает приверженность лечению уже в первые трое суток.
Подробнее - [url=https://narkologicheskaya-klinika-moskva99.ru/]narkologicheskaya-moskva[/url]
Launch your fund setup uae with end-to-end support: structuring, legal documentation, licensing, AML/KYC compliance, corporate setup and administration. We help create flexible investment vehicles for global investors and family wealth platforms.
End-to-end corporate setup uae: company formation, trade licence, corporate documentation, visa processing, bank account assistance and compliance checks. We streamline incorporation and help establish a strong operational foundation in the UAE.
Need legalization of documents for uae? We manage the entire process — review, notarisation, ministry approvals, embassy attestation and translation. Suitable for business setup, visas, employment, education and property transactions. Efficient and hassle-free.
Comprehensive family office setup uae: from choosing the right jurisdiction and legal structure to incorporation, banking, policies, reporting and ongoing administration. Tailored solutions for families consolidating wealth, protecting assets and planning succession.
Set up a uae holding company with full legal and corporate support. We help select the right jurisdiction, prepare documents, register the entity, coordinate banking and ensure compliance with substance, tax and reporting rules for international groups.
В «Центр Трезвости Воронеж» приватность не обсуждается — она проектируется. Выбор нейтральных формулировок в чеках, немаркированные выезды, «беззвучные» уведомления, отдельные входы и доступ к карте наблюдения только по ролям — это норма, а не «услуга». Пациент может назначить доверенное лицо, чтобы получать краткие апдейты в согласованные временные окна.
Узнать больше - https://narkologicheskaya-klinika-v-voronezhe15.ru/narkologicheskaya-klinika-voronezh-otzyvy/
FuturePath Online Hub – Cleanly arranged products with modern design ensure effortless shopping.
Идеи для активного отдыха Проект загородного дома следует начинать с тщательного планирования. Определите, сколько комнат вам нужно, и какое их назначение. Понимание функциональности поможет избежать ненужных затрат и упростит дальнейшую реализацию. Использование современных технологий и энергоэффективных материалов также сыграет ключевую роль в создании комфортного жилья. Не забывайте об интерьере – продуманные детали, такие как освещение и мебель, могут значительно повлиять на общее восприятие пространства. Таким образом, ваш загородный дом станет не только красивым, но и удобным местом для жизни.
Чтобы пациент и близкие не гадали «что будет дальше», мы удерживаем прозрачную последовательность. Каждый этап имеет цель, инструмент, окно оценки и критерий перехода. Это экономит минуты, снимает споры и делает план управляемым.
Подробнее - [url=https://vivod-iz-zapoya-voronezh15.ru/]анонимный вывод из запоя воронеж[/url]
Growth Exploration Spot – Enjoyed the organized sections; moving around the site felt natural.
Future Market Path – Clean, modern pages with smooth transitions make exploring products effortless.
https://bravomos.ru/ bravomos
Path to Limitless Growth – Fast loading pages and a user-friendly interface made exploring smooth.
Need a poa dubai? We draft POA documents, organise notary appointments, handle MOFA attestation, embassy legalisation and certified translations. Ideal for delegating authority for banking, business, real estate and legal procedures.
Need a will uae? We help structure inheritances, appoint executors and guardians, cover local and foreign assets and prepare documents in line with UAE requirements. Step-by-step guidance from first consultation to registration and safe storage of your will.
Open a brokerage account uae with full support. We review your goals, recommend regulated platforms, guide you through compliance, handle documentation and assist with activation. Ideal for stock, ETF, bond and multi-asset trading from a trusted jurisdiction.
LuminousVault – Attractive products and intuitive navigation make shopping fun.
Complete uae work visa support: from eligibility check and document preparation to work permit approval, medical tests and residence visa issuance. Ideal for professionals moving to Dubai, Abu Dhabi and other emirates for long-term employment.
Авиабилеты в Китай https://chinaavia.com по выгодным ценам: удобный поиск рейсов, сравнение тарифов, прямые и стыковочные перелёты, актуальные расписания. Бронируйте билеты в Пекин, Шанхай, Гуанчжоу и другие города онлайн. Надёжная оплата и мгновенная выдача электронного билета.
Показана при обезвоживании, «скачущем» давлении и пульсе, угрозе судорог, упорной рвоте, эпизодах спутанности сознания, тяжёлой соматике. За сутки–двое удаётся выровнять показатели, наладить сон и безопасно перейти к амбулаторному этапу.
Узнать больше - [url=https://narkologicheskaya-klinika-moskva999.ru/]клиника наркологии москва[/url]
Trendy Lovers Market – Enjoyed the neat design and how simple it was to look through the styles.
В реальности Воронежа на самочувствие влияет не только фармакология, но и логистика: трассы с плотным трафиком, яркое освещение подъездов, очереди в медорганизациях. «ВоронежМедЦентр» гасит эти раздражители организационно: «тихие окна» приёма без коридорного шума, согласованная парковка, немаркированные выезды, нейтральные формулировки в документах и «беззвучные» напоминания. Снижение сенсорной нагрузки — это не декоративная опция, а клинический фактор: спокойная первая ночь, ровный пульс к вечеру, предсказуемость режима воды и тёплой пищи малыми порциями.
Подробнее можно узнать тут - https://narkologicheskaya-klinika-voronezh15.ru
BrightHub – User-friendly site and well-presented products make browsing seamless.
После прохождения детоксикации пациенту назначаются восстановительные процедуры, направленные на нормализацию обмена веществ и укрепление нервной системы. Программы клиники включают физиотерапию, витаминотерапию и индивидуальные занятия с психотерапевтом. Главная цель — восстановить способность организма к естественной саморегуляции и снизить зависимость от внешних раздражителей.
Изучить вопрос глубже - https://narkologicheskaya-clinika-v-kazani16.ru/narkologicheskaya-klinika-kazan-otzyvy
Lovers Style Market – Stylish looks showcased well, and everything loaded without delay.
Техника помогает, но не доминирует. Мы используем портативные приборы с мягкой индикацией и низким уровнем шума, чтобы не разрушать формирующуюся «ночную кривую». Контроль в остром окне чаще, вечером — мягче: так сохраняется физиология сна и снижается потребность в дополнительной фармакологии.
Получить больше информации - http://narkologicheskaya-klinika-petrozavodsk15.ru/chastnaya-narkologicheskaya-klinika-petrozavodsk/
Coin burning events Binance trading signals, beyond the hype and the promises of instant riches, represent the democratization of sophisticated market analysis. These signals, whether meticulously crafted by seasoned analysts or spat out by the cold, calculating logic of AI, offer a scaffolding of insights. They attempt to distill the chaos of market sentiment into actionable intelligence – entry exit levels sharp enough to draw blood, stop-loss recommendations acting as digital lifelines, and take-profit targets crypto calibrated to maximize gain while mitigating risk. The siren song of Binance VIP signals, echoing through premium crypto signal telegram channels, underscores the premium placed on precise, actionable information delivered with the urgency of a ticking clock.
Мы предлагаем кодирование тогда, когда оно медицински оправдано и человек готов его принять осознанно. Сначала исключаем противопоказания, обсуждаем механизм, ограничения и риски, согласуем формат — инъекция, имплантация или пероральная поддержка. После процедуры пациент получает памятку и контакт для связи, а также план профилактики срывов: без поведенческих шагов любое фармвмешательство теряет часть эффективности. Важный критерий выбора методики — реальный график жизни: командировки, смены, поздние встречи. Метод должен переживать вашу неделю без «узких мест», иначе дорогостоящая техника не даст ожидаемого эффекта. Такой прагматичный подход даёт не мифическую «гарантию», а рабочую устойчивость, которую можно удерживать месяцами.
Получить дополнительную информацию - https://narkologicheskaya-klinika-moskva99.ru/narkologicheskaya-klinika-v-moskve-ceny/
SFN Lifestyle Store – Light, modern layout with quick access to interesting products.
Start Fresh Online – Great airy layout and smooth browsing experience for products.
Если в первичном звонке звучат «красные флаги» (одышка, спутанность сознания, резкие скачки ритма), мы предлагаем стационарное «окно» мониторинга с ночным постом. При низких рисках стартуем на дому: контрольные точки совпадают с домашним комфортом, а вечерние online-вставки по 15–20 минут поддерживают предсказуемость без лишних поездок.
Получить больше информации - http://vivod-iz-zapoya-voronezh15.ru
Если в первичном звонке звучат «красные флаги» (одышка, спутанность сознания, резкие скачки ритма), мы предлагаем стационарное «окно» мониторинга с ночным постом. При низких рисках стартуем на дому: контрольные точки совпадают с домашним комфортом, а вечерние online-вставки по 15–20 минут поддерживают предсказуемость без лишних поездок.
Ознакомиться с деталями - [url=https://vivod-iz-zapoya-voronezh15.ru/]вывод из запоя дешево воронеж[/url]
Домашний формат нужен, когда важно начать быстро и без лишних перемещений, а состояние не требует госпитализации. Врач адаптирует инфузионные схемы под переносимость и сопутствующие заболевания, контролирует давление, пульс, сатурацию, объясняет режим жидкости и питания, оставляет список признаков, при которых следует связаться повторно. Такой сценарий не отменяет дальнейшую работу: пациент получает краткий план на 48–72 часа, рекомендации по восстановлению сна и активности, а также точку контакта для корректировки. Это снижает тревогу, помогает избежать «самолечения» и формирует доверие к процессу, потому что человек видит конкретный результат — уменьшение тремора, нормализацию сна, снижение тревоги — уже в первые сутки.
Получить дополнительные сведения - https://narkologicheskaya-klinika-moskva9.ru/anonimnaya-narkologicheskaya-klinika-v-moskve/
Главная задача — вернуть контроль над самочувствием мягко и последовательно. Мы не соревнуемся в дозах, а собираем устойчивую траекторию улучшения: каждый модуль терапии отвечает за одну цель и имеет своё «окно оценки». Если отклик ниже ожиданий — меняем ровно один параметр (темп, последовательность или поведенческий элемент среды), чтобы точно понимать, что помогло.
Разобраться лучше - нарколог вывод из запоя в казани
Leading dealer marketplace accounts greets webmasters into the comprehensive database of social accounts. The pride of this platform is the availability of an extensive educational hub, featuring secret strategies on lead generation. Inside the guides, experts share tricks on using proxies to boost profits in your marketing efforts. Our inventory offers pages of FB, Insta, Telegram for any purpose: ranging from softregs up to verified profiles with activity.
Карта делает маршрут прозрачным для пациента и семьи. Вместо «лучше/хуже» — факты и понятные пороги. Это снижает тревожность и помогает соблюдать режим без сопротивления.
Подробнее тут - [url=https://narkologicheskaya-klinika-petrozavodsk15.ru/]наркологическая клиника нарколог в петрозаводске[/url]
Trend Fashion Corner Shop – Loved the trendy items, browsing through the collection was very smooth.
География накладывает отпечаток на клинические решения. Длинные сумерки, переменчивый ветер с акватории и «звонкие» подъезды старого фонда увеличивают чувствительность к свету и шуму, а значит — усиливают вечернюю кардиолабильность. В «АрктикМед Профи» протоколы адаптированы под такой фон: в палатах преобладают тёплые источники света, на обходах персонал работает в «режиме тишины», в смартфонах включается «без уведомлений», а выездные бригады заходят в дом максимально незаметно. Такой «мягкий» сценарий делает помощь не только деликатной, но и клинически эффективной — снижается потребность в «сильных» седативных вмешательствах, сохраняется физиологичность сна.
Исследовать вопрос подробнее - https://narkologicheskaya-klinika-v-murmanske15.ru/narkologicheskij-dispanser-g-murmansk
Такая карта делает лечение обозримым и дисциплинирует решения: пациент видит цель и порог перехода, семья понимает, зачем нужно соблюдать «тихие» часы, команда сохраняет управляемость и не «крутит ручки» ночью.
Исследовать вопрос подробнее - https://narkologicheskaya-klinika-v-petrozavodske15.ru
TFC Trend Corner – Good mix of stylish products, moving through sections was simple.
Каждый пациент проходит последовательный процесс лечения, где основное внимание уделяется безопасности, контролю состояния и постепенной адаптации. При поступлении проводится диагностика с оценкой степени зависимости, сопутствующих патологий и психологических факторов, влияющих на развитие заболевания. На основании полученных данных формируется персонализированный план терапии, включающий медикаментозные и немедикаментозные методы.
Получить дополнительные сведения - [url=https://narkologicheskaya-klinika-v-spb16.ru/]наркологическая клиника наркологический центр[/url]
SacredRidgeMart – Pleasant browsing, website loads quickly and items are well-arranged.
TrailSunrise Lane – Tidy pages and organized sections enhance the overall shopping flow.
SacredRidge Deals – Simple and pleasant browsing experience, everything loads quickly.
UniquePresentsShop – Neat layout, inspiring items, and effortless site flow.
Sunrise Trail Finds – Simple design with clearly arranged items allows effortless browsing.
Наркологическая клиника в клинике в Екатеринбурге — это специализированное медицинское учреждение, где проводится диагностика, лечение и реабилитация людей, страдающих алкогольной или наркотической зависимостью. Комплексный подход включает не только медикаментозную терапию, но и психотерапевтические методики, направленные на восстановление личности и возвращение пациента к социальной активности. Каждое вмешательство проводится с учётом физического состояния, психологического профиля и стадии заболевания. Работа специалистов основана на принципах анонимности, медицинской этики и научно доказанных протоколов лечения.
Ознакомиться с деталями - http://narkologicheskaya-klinika-v-ekb16.ru/chastnaya-narkologicheskaya-klinika-ekaterinburg/
Современный шоп по ссылке открывает возможность купить прогретые расходники для рекламы. Ключевое преимущество этого шопа — заключается в наличие масштабной библиотеки, где опубликованы актуальные гайды по добыче трафика. Команда поможем, каким образом грамотно прогревать рекламу, как обходить баны и настраивать клоаку. Вступайте к нам, изучайте обучающие кейсы, делитесь опытом чтобы делайте профит на наших расходниках прямо сейчас.
GiftSelectionSpot – Minimalistic design, smooth browsing, and unique items throughout.
Если на первичном звонке звучат «красные флаги» (выраженная одышка, спутанность сознания, скачки ритма), мы предлагаем стационарное окно мониторинга. При низком риске стартуем дома или амбулаторно и поддерживаем человека вечерними видеовставками по 15–20 минут, чтобы пройти «трудный час» без лишних поездок и паники.
Исследовать вопрос подробнее - [url=https://vyvod-iz-zapoya-v-voronezhe15.ru/]вывод из запоя с выездом в воронеже[/url]
Срочная наркологическая помощь — это не «универсальная капельница», а управляемый клинический процесс, где каждое действие проверяется измеримыми маркерами и выполняется в правильной последовательности. В наркологической клинике «ВолгаМед Альтернатива» маршрут выстроен вокруг принципа минимально достаточных вмешательств: сначала безопасный старт и телескрининг, затем очный осмотр с выбором контура инфузии и, только после теста переносимости, — основная терапия. Такой подход уменьшает реактивность организма, снижает риск побочных ощущений и делает результат предсказуемым для пациента и близких. Команда работает круглосуточно, выезжает на немаркированном транспорте, общение ведётся через одного доверенного человека, а документы оформляются в нейтральной терминологии без стигматизирующих формулировок.
Подробнее тут - https://narkologicheskaya-pomoshh-v-kazani16.ru/narkologicheskaya-sluzhba-kazan
Наркологическая клиника в клинике в Казани оказывает квалифицированную помощь людям, столкнувшимся с алкогольной и наркотической зависимостью. Лечение проводится в условиях полной конфиденциальности и медицинской безопасности. Основное направление работы клиники — это восстановление физического, психического и эмоционального состояния пациента, а также формирование устойчивой мотивации к отказу от употребления психоактивных веществ. Все процедуры выполняются с использованием сертифицированных препаратов и современных диагностических технологий, что позволяет добиться устойчивого результата без осложнений.
Выяснить больше - https://narkologicheskaya-klinika-v-kazani16.ru/narkologicheskaya-klinika-kazan-otzyvy/
Мы сознательно фиксируем не только «медицинские» параметры, но и бытовые маркеры: сколько воды выпито, как переносится тёплая пища малыми порциями, какой свет в комнате перед сном. Эти детали активно упоминаются в клинических рекомендациях, потому что нередко именно они решают исход первой ночи лучше, чем попытка «усилить» таблеткой.
Получить больше информации - [url=https://narkologicheskaya-klinika-stavropol15.ru/]наркологическая клиника стационар ставрополь[/url]
Чтобы процедура прошла спокойно и без задержек, заранее организуйте базовые условия — это экономит время и силы пациента и семьи.
Подробнее можно узнать тут - https://vyvod-iz-zapoya-moskva8.ru/vyvod-iz-zapoya-v-moskve-nedorogo/
Команда выездных специалистов работает без броской символики, использует нейтральный транспорт и конфиденциальный документооборот. Врач приезжает с портативным оборудованием (мониторинг АД/ЧСС/SpO?, термометр, пульсоксиметр, при необходимости — портативный ЭКГ-модуль), выполняет тест переносимости, формирует индивидуальный инфузионный профиль и обучает семью простым процедурам поддержки: водный режим малыми глотками, «тихие окна» без экранов, дыхательные паузы. В результате пациент не просто «переживает» детокс, а действительно возвращается к устойчивому сну, ровному пульсу и ясной голове.
Получить больше информации - [url=https://vivod-iz-zapoya-v-sankt-peterburge16.ru/]вывод из запоя капельница на дому санкт-петербург[/url]
Реабилитационные мероприятия в клинике направлены на устранение соматических последствий зависимости, нормализацию когнитивных функций и восстановление социальной адаптации. Для этого используются современные методики физиотерапии, диетологической коррекции и психологического сопровождения, позволяющие закрепить достигнутые результаты лечения.
Подробнее можно узнать тут - [url=https://narkologicheskaya-klinika-v-spb16.ru/]вывод наркологическая клиника в санкт-петербурге[/url]
goldenlookhub – Pages are tidy and easy to explore, made shopping simple.
Limitless Growth Hub – Browsed the site and found the information clear and easy to follow.
Stay Curious Creative Shop – Loved the inspiring vibe, exploring ideas was fun and easy.
Каждый метод «привязан» к решаемой задаче. Если динамика «плоская», мы не усиливаем всё сразу: корректируем один параметр (скорость инфузии, последовательность шагов, длительность вечерних вставок) и повторно оцениваем результат в оговорённое время. Такая бережная настройка снижает риск побочных эффектов и сохраняет ясность днём.
Подробнее тут - [url=https://narkologicheskaya-klinika-voronezh15.ru/]запой наркологическая клиника[/url]
SCC Idea Hub Online – Loved the inventive feel, discovering ideas was quick and easy.
Unlimited Growth Portal – Very intuitive layout and the pages load quickly without issues.
goldenharborstore – Well-structured layout and clear product listings, browsing was hassle-free.
WishCentral – Quick loading site with clearly presented items for effortless browsing.
UrbanFindVault – Intuitive navigation with clear presentation of a wide product selection.
Smart Value Finds – The layout felt steady, pages loaded cleanly, and listings offered good savings.
Urban Style Hub – Sleek urban fashion items with fast-loading pages and smooth navigation.
NewValue Market – Browsing felt intuitive with plenty of worthwhile items to check out.
Street Chic Hub – Well-arranged urban products with fast, intuitive browsing throughout.
FuturePath Online Hub – Cleanly arranged products with modern design ensure effortless shopping.
Стационар — это управляемая среда, где меньше случайностей и больше возможностей действовать на опережение. Под одной крышей — приём и допуск к терапии, инфузионный блок, аппаратный контроль, лаборатория и ЭКГ по показаниям, пост медсестёр и регулярная переоценка состояния. Такой контур особенно важен при давних запойных эпизодах, гипертонии, ишемической болезни сердца, сахарном диабете, гастроэнтерологических проблемах: правильно настроенный темп инфузий и «бережные» назначения уменьшают риск осложнений и снимают «эффект качелей» в первые сутки.
Выяснить больше - http://narkologicheskaya-klinika-voskresensk8.ru/telefon-narkologicheskoj-klinikia-v-voskresenske/
Future Path Hub – Modern layout with clearly displayed products and smooth browsing throughout.
ShadyLane Emporium – Nice clean design, browsing feels comfortable and intuitive.
Запой — это не только выраженная тяга к алкоголю, но и комплекс физиологических нарушений: обезвоживание, колебания давления, тахикардия, бессонница, тремор, дефициты электролитов. Чем дольше длится эпизод, тем выше риск делирия и декомпенсаций. Мы оцениваем картину целиком: стаж употребления, фоновые болезни, уже принятые препараты, прошлые эпизоды судорог или потерь сознания. По итогам первичной беседы врач рекомендует формат старта — визит на дому или стационар.
Разобраться лучше - [url=https://vyvod-iz-zapoya-moskva8.ru/]вывод из запоя москва вызов нарколога капельница[/url]
ShadyLane Boutique – The site is easy to navigate, and the product selection looks appealing.
Этапность терапии позволяет проводить лечение безопасно, с контролем жизненных показателей и прогнозируемым восстановлением физического состояния. После выхода из запоя пациенту рекомендуется продолжить реабилитацию для предупреждения повторных нарушений.
Подробнее можно узнать тут - наркологическая клиника цены
TFL Online Picks Hub – Loved the content variety, navigation felt very simple.
Взаимосвязь медицинских и психологических компонентов терапии формирует основу устойчивой ремиссии, снижая вероятность повторных срывов и обеспечивая длительный восстановительный эффект.
Получить дополнительную информацию - https://narkologicheskaya-klinika-v-ekb16.ru/narkologicheskaya-klinika-ekaterinburg-otzyvy/
Запой — это не только выраженная тяга к алкоголю, но и комплекс физиологических нарушений: обезвоживание, колебания давления, тахикардия, бессонница, тремор, дефициты электролитов. Чем дольше длится эпизод, тем выше риск делирия и декомпенсаций. Мы оцениваем картину целиком: стаж употребления, фоновые болезни, уже принятые препараты, прошлые эпизоды судорог или потерь сознания. По итогам первичной беседы врач рекомендует формат старта — визит на дому или стационар.
Получить дополнительные сведения - [url=https://vyvod-iz-zapoya-moskva8.ru/]vyvod-iz-zapoya-moskva-ceny[/url]
Trend For Life Corner – Appealing layout with smooth navigation, browsing was easy.
Grand River Picks – Products displayed neatly, browsing feels intuitive and satisfying.
Grand River Outlet – Well-curated finds, making it easy to explore and enjoy the selection.
Первое сутки с половиной — «каркас» программы. Мы формулируем цель каждого окна, фиксируем инструменты и пороги перехода. Если ожидаемой динамики нет, меняется один параметр (темп/объём/последовательность), после чего назначается повторная оценка. Это защищает от полипрагмазии и сохраняет причинно-следственную связь.
Получить дополнительную информацию - [url=https://narkologicheskaya-klinika-petrozavodsk15.ru/]анонимная наркологическая клиника в петрозаводске[/url]
Если при предзвонке выявляются «красные флаги» — одышка, давящая боль в груди, выраженная дезориентация, неукротимая рвота — координатор сразу резервирует место под наблюдение и организует перевод без пауз. В остальных ситуациях маршрут стартует дома с «мостиком» в стационар на случай изменения динамики.
Подробнее можно узнать тут - [url=https://vyvod-iz-zapoya-murmansk15.ru/]вывод из запоя капельница[/url]
BrookCoastalMarket – Straightforward site design, neatly arranged items, and easy overall navigation.
Наркологическая клиника «СтавропольМедСервис» объединяет современную медицину и чуткое отношение к человеку: круглосуточный приём, точные диагностические алгоритмы, адресная инфузионная терапия, телемедицинские включения и грамотная работа с тревогой и сном. Мы используем принцип «минимально достаточной фармакотерапии»: каждый препарат должен быть оправдан текущими измерениями и клинической картиной, а не привычкой «усилить». Такой подход уменьшает риски дневной заторможенности, помогает быстрее восстановить ясность и делает ночь предсказуемой — без тяжёлой седации. Все действия прозрачны: пациент знает цель шага, окно оценки, критерии перехода и признаки, при которых нужно эскалировать наблюдение. Конфиденциальность встроена в процесс: гражданская одежда персонала, нейтральные формулировки в документах, «беззвучные» уведомления и закрытый контур медицинских карт — не «сервисная опция», а клинический фактор, снижающий реактивность и повышающий приверженность плану.
Получить дополнительные сведения - http://narkologicheskaya-klinika-v-stavropole15.ru
CoastalBrookCorner – Nice variety of items with intuitive navigation and a comfortable browsing flow.
Экстренный вывод из запоя на дому — это управляемая медицинская последовательность, а не «сильная капельница на удачу». В наркологической клинике «КалининградМедПрофи» мы выстраиваем помощь вокруг трёх опор: безопасность, конфиденциальность и предсказуемый результат. Выездная бригада приезжает круглосуточно, работает в гражданской одежде и без опознавательных знаков, чтобы не привлекать внимания соседей. Каждое вмешательство имеет измеримую цель, окно проверки и прозрачный критерий перехода к следующему шагу. Благодаря этому темп лечения остаётся мягким, а динамика — понятной для пациента и близких.
Узнать больше - [url=https://vyvod-iz-zapoya-v-kaliningrade15.ru/]вывод из запоя капельница калининград[/url]
Домашний формат выбирают, когда обстановка позволяет провести лечение в тишине и нет признаков угрозы жизни. Врач приезжает без опознавательных знаков, начинает с очной оценки и допуска к инфузии, сверяет принятые ранее препараты и аллергии, объясняет ожидаемую динамику. После запуска капельницы мягко корректируются жидкость и электролиты, проводится симптом-контроль (тремор, тошнота, тревога, головная боль), по показаниям — осторожная нормализация сна. На выходе пациент и семья получают понятные рекомендации на 24–48 часов: питьевой режим, питание, ограничения по нагрузкам, признаки тревоги и правила связи с дежурным врачом.
Изучить вопрос глубже - [url=https://vyvod-iz-zapoya-sergiev-posad8.ru/]вывод из алкогольного запоя в домашних условиях[/url]
Курс терапии в клинике состоит из нескольких последовательных этапов, каждый из которых направлен на достижение конкретных целей — от снятия интоксикации до восстановления психологического равновесия. Такой подход позволяет добиться устойчивого результата и минимизировать вероятность рецидива. На всех стадиях лечения ведётся контроль состояния пациента, а также постоянная корректировка назначений в зависимости от реакции организма.
Углубиться в тему - наркологическая клиника лечение алкоголизма казань
Решение о кодировании принимает врач после очной оценки. Методика подбирается индивидуально, с обязательным информированным согласием. Ниже — ориентиры, помогающие понять, когда процедура уместна, а когда стоит отложить или выбрать альтернативу.
Получить больше информации - бесплатное кодирование от алкоголизма в санкт-петербурге
Explore the depths of space and the resilience of the human spirit. The Project Hail Mary PDF provides instant access to a story that is both hilarious and heart-wrenching. This electronic version is designed for optimal readability, ensuring you don't miss a single detail of the scientific problem-solving. https://projecthailmarypdf.top/ where to watch project hail mary
バイナリーオプションとは
YourDailySavings – Simple interface, smooth navigation, and appealing daily deals.
DealsTodayOnline – Simple layout, easy-to-browse sections, and smooth site flow.
Домашний формат уменьшает стресс и экономит время: не нужно ехать в клинику, скрывать визит от соседей или ждать в очереди. Врач приезжает без опознавательных знаков и не создаёт «медицинского шума». За один визит удаётся снять острые проявления, выстроить понятный план ночи и следующего утра, а также определить, нужна ли дополнительная диагностика. Такой маршрут часто оказывается короче и эффективнее, чем череда попыток «пересидеть» симптомы без медицинской поддержки.
Узнать больше - [url=https://narkolog-na-dom-voskresensk8.ru/]voskresensk-narkologiya[/url]
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Подробнее тут - https://primenewsnet.com/computer-filters-noise-to-make-you-a-better-listener
Forward Path Hub – Motivational theme with tidy layout, exploring content was easy.
Descubre cocoa casino 10 €: tragamonedas clasicas y de video, juegos de mesa, video poker y jackpots en una interfaz intuitiva. Bonos de bienvenida, ofertas de recarga y recompensas de fidelidad, ademas de depositos y retiros rapidos y un atento servicio de atencion al cliente. Solo para adultos. Mayores de 18 anos.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Не упусти шанс - https://elantzen.eus/deux-histoires-du-cure-axular/?lang=fr
знакомства Татарстан есть свои обычии, есть привычки, знакомства мы с ренатом встретились у друзей, он сразу обратил на меня внимание, серьезный молодой чел, надеюсь на хорошее будущее.
Platforma internetowa mostbet: zaklady przedmeczowe i na zywo, wysokie kursy, akumulatory, zaklady na sumy i handicapy, a takze popularne sloty i kasyno na zywo. Bonus powitalny, regularne promocje, szybkie wyplaty na karty i portfele.
TPF Journey Hub – Motivational and clear design, navigating the site was effortless.
Прежде чем перечислить критичные признаки, зафиксируем принцип: даже один выраженный симптом — повод не откладывать помощь и выбрать безопасный маршрут (дом или стационар) после быстрой очной оценки врача.
Ознакомиться с деталями - http://vyvod-iz-zapoya-sergiev-posad8.ru/vyvod-iz-zapoya-na-domu-v-sergievom-posade/https://vyvod-iz-zapoya-sergiev-posad8.ru
сходим в ресторан свидание https://rutiti.ru где есть упругие девушки? правильно только у нас, ты был на рутити, если нет забегай, нажми блог а там фотки убедишься сам, самое важное твой настрой.
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Узнать из первых рук - https://gettrialsnow.com/services/resplendent-sparks-farm
Platforma internetowa mostbet: zaklady przedmeczowe i na zywo, wysokie kursy, akumulatory, zaklady na sumy i handicapy, a takze popularne sloty i kasyno na zywo. Bonus powitalny, regularne promocje, szybkie wyplaty na karty i portfele.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Открыть полностью - https://vigashpk.com/projects/cnc-machinery
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Получить больше информации - https://dressingdesmomes.fr/2024/01/26/confidences-pour-confidences
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Проверенные методы — узнай сейчас - https://life365days.com/toc/cham-soc-toc/goi-dau-buoi-sang-co-tot-khong
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Не упусти шанс - https://hotelukrbu.cz/blog/spustili-jsme-novy-web
https://t.me/s/officials_1xbet_1xbet
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Открыть полностью - https://primenewsnet.com/dave-williams-defeated-in-spectacular-motorcross-final
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации - https://cattocodau.com/tiem-toc-dak-nong
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Погрузиться в детали - https://www.defining-blog.ru/nppr-team-shop-vash-put-k-uspeshnojj-reklame-6t
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Ознакомиться с полной информацией - https://virtueempress.com/spiritual-laziness
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Прочитать подробнее - https://wineco.fr/harnessing-the-power-of-social-media-for-business-growth
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Что ещё нужно знать? - https://www.defining-blog.ru/tag/finansy-i-investicii
Откройте для себя скрытые страницы истории и малоизвестные научные открытия, которые оказали колоссальное влияние на развитие человечества. Статья предлагает свежий взгляд на события, которые заслуживают большего внимания.
Как достичь результата? - https://xiao.lu/index.php/archives/1/?replyTo=310
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Продолжить изучение - https://xiao.lu/index.php/archives/1/?replyTo=326
ブビンガ 安全性
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Наши рекомендации — тут - http://www.vlamcoat.be/2013/03/28/ambrose-redmoon
Next Horizon Hub – Layout is tidy and the browsing experience was comfortable.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Исследовать вопрос подробнее - https://liphtdelta8.com/designers-shaking-up-modern-furniture
Срочная наркологическая помощь — это не «универсальная капельница», а управляемый клинический процесс, где каждое действие проверяется измеримыми маркерами и выполняется в правильной последовательности. В наркологической клинике «ВолгаМед Альтернатива» маршрут выстроен вокруг принципа минимально достаточных вмешательств: сначала безопасный старт и телескрининг, затем очный осмотр с выбором контура инфузии и, только после теста переносимости, — основная терапия. Такой подход уменьшает реактивность организма, снижает риск побочных ощущений и делает результат предсказуемым для пациента и близких. Команда работает круглосуточно, выезжает на немаркированном транспорте, общение ведётся через одного доверенного человека, а документы оформляются в нейтральной терминологии без стигматизирующих формулировок.
Углубиться в тему - срочная наркологическая помощь в казани
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Рассмотреть проблему всесторонне - https://san-tec-bautenschutz.de/galerie03
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Узнайте всю правду - https://baileyorthodontics.com/when-to-start-orthodontic-treatment
CrestStyleHub – Items easy to browse with a visually appealing, modern interface.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Перейти к полной версии - https://arch-jinji.com/%E4%B8%AD%E5%B0%8F%E4%BC%81%E6%A5%AD%E3%81%8C%E6%8E%A1%E7%94%A8%E3%81%A7%E5%8B%9D%E3%81%A4%E3%81%9F%E3%82%81%E3%81%AB%E3%82%84%E3%82%8B%E3%81%B9%E3%81%8D%E5%A4%A7%E4%BA%8B%E3%81%AA%E3%81%93%E3%81%A8
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Погрузиться в детали - https://animelx.com/veterinario-elche
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Узнать больше > - http://matthias-rudolph.net/gallery/tript
В данной статье вы найдете комплексный подход к изучению насущных тем. Мы комбинируем теоретические сведения с практическими советами, чтобы читатель мог не только понять проблему, но и найти пути её решения.
Всё, что нужно знать - http://losnorge.no/2021/09/13/mental-muda
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Изучите внимательнее - https://www.defining-blog.ru/category/nedvizhimost
Horizons Resource Center – Smooth experience with content that is useful and accessible.
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Что ещё нужно знать? - https://hygienegegenviren.de/portfolio-view/in-faucibus
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Что ещё нужно знать? - https://suryaglass.id/perbedaan-kaca-tempered-dengan-kaca-laminated
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Подробнее можно узнать тут - http://vdprofessionalroofing.com/product/roof-damage-repair
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Кликни и узнай всё! - https://www.entdailyng.com/everything-we-know-about-the-3-new-grammy-categories-for-2024
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
ТОП-5 причин узнать больше - https://kameyasouken.com/%E4%BA%80%E5%B1%8B%E5%A3%AE%E5%81%A5%E3%81%A8%E3%81%AF/cropped-1512387839618-jpg
SkyBlossom Finds – Pleasant browsing experience, site feels organized and products are appealing.
CrestTrendSpot – Fast-loading pages with modern, stylish products showcased clearly.
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Провести детальное исследование - https://humanrightwarrior.org/11-ways-to-live-your-life-like-a-warrior
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Узнать из первых рук - https://midnightsunactivities.com/experience-the-ultimate-getaway-with-luxury-yacht-rentals
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Раскрыть тему полностью - https://maclp88.com/sns%E6%B4%BB%E7%94%A8%E3%81%AB%E3%82%88%E3%82%8A%E5%AE%89%E5%AE%9A%E7%9A%84%E3%81%AB%E6%9C%88%E5%8F%8E100%E4%B8%87%E5%86%86%E3%81%AB%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95
SkyBlossom Emporium – Very smooth browsing experience, items are neatly organized and visible.
Sunrise Picks Hub – Tidy interface and clearly organized products provide smooth navigation.
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Жми сюда — получишь ответ - https://sipenmaru.poltekkespalu.ac.id/2023/05/17/pengumuman-pendaftaran-jalur-mandiri-2023-sudah-dibuka-ayo-daftar
FreshStyle Market – Navigating the various style options was smooth and pleasantly quick.
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Смотрите также - https://960.be/overig/de-verschillen-tussen-belgie-en-nederland
Эта статья погружает вас в увлекательный мир знаний, где каждый факт становится открытием. Мы расскажем о ключевых исторических поворотных моментах и научных прорывах, которые изменили ход цивилизации. Поймите, как прошлое формирует настоящее и как его уроки могут помочь нам строить будущее.
Лучшее решение — прямо здесь - https://jovemparceiro.com.br/2021/12/29/jornalistas-equatorianos-reiteram-que-pineida-rende-melhor-na-lateral-esquerda-bola-rolando
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Тыкай сюда — узнаешь много интересного - http://www.volgyfitness.hu/?p=6639&cpage=14
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый мог разобраться в предмете и извлечь из него максимум пользы.
Углубить понимание вопроса - https://rajuomlet.com/product/green-cheese
Статья содержит практические рекомендации и полезные советы, которые можно легко применить в повседневной жизни. Мы делаем акцент на реальных примерах и проверенных методиках, которые способствуют личностному развитию и улучшению качества жизни.
Изучить рекомендации специалистов - https://point-connection.com/index.php/2022/05/26/will-digital-marketing-ever-rule
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Уникальные данные только сегодня - https://primenewsnet.com/new-screen-savers-the-show-launched-video-into-the-stratosphere
Hub of Style Picks – Great layout and fast transitions that made browsing their fashion lineup enjoyable.
Sunrise Market Finds – Well-laid-out items and straightforward menus provide a smooth shopping flow.
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый мог разобраться в предмете и извлечь из него максимум пользы.
Провести детальное исследование - https://alumni.sainikschoolkodagu.edu.in/index.php?option=com_k2&view=item&id=3:benefits-of-joining-alumni-association&Itemid=525&limitstart=2010
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Смотрите также - https://universidadiesdi.com/hola-mundo
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Личный опыт — читайте сами - http://www.volgyfitness.hu/?p=6639&cpage=154
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Подробности по ссылке - https://around29.com/seo-myths-and-misconceptions-debunking-the-most-common-misbeliefs
аренда аккаунтов букмекерских конто Покупка и аренда аккаунтов букмекерских контор – это сложная и многогранная тема, окруженная как возможностями, так и значительными рисками. Группы, занимающиеся данной деятельностью, часто формируются с целью оптимизации ставок, обхода ограничений, установленных букмекерскими компаниями, или для использования различных приветственных бонусов и акций. Однако, важно понимать, что подобные действия нередко противоречат правилам и условиям, установленным букмекерскими конторами, что может привести к блокировке аккаунта и потере средств.
Статья содержит практические рекомендации и полезные советы, которые можно легко применить в повседневной жизни. Мы делаем акцент на реальных примерах и проверенных методиках, которые способствуют личностному развитию и улучшению качества жизни.
Интересует подробная информация - https://smkpgri2kediri.sch.id/vaksin-booster
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Получить полную информацию - https://www.defining-blog.ru/2025/10/10
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Информация доступна здесь - https://www.defining-blog.ru/category/marketing
TMO Picks Hub – Loved the user-friendly setup, moving between pages was fast.
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Прочесть заключение эксперта - https://bethanyfamilyinstitute.com/high-quality-da-dr-backlinks-high-tf-backlinks-high-traffic-guest-post-website-available-ahrefs-domain-rating-70-moz-domain-authority-1883
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Подробнее - https://cekodesign.com/controversial-article-find-out-more
Grand River Picks – Products displayed neatly, browsing feels intuitive and satisfying.
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Перейти к полной версии - https://www.strucktour.com/?page_id=2462
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Не упусти важное! - https://envanlifesimone.com/5-jours-en-auvergne-en-van-amenage
Trend Market Outlet Shop – Really enjoyed browsing, pages load quickly and products are easy to find.
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Доступ к полной версии - https://primenewsnet.com/ecommerce-brands-tend-to-create-strong-communities
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый мог разобраться в предмете и извлечь из него максимум пользы.
Перейти к полной версии - https://mckeeverdecorating.com/hello-world
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Детальнее - https://www.gr888.co/review/4738
Prodej reziva https://www.kup-drevo.cz v Ceske republice: siroky vyber reziva, stavebniho a dokoncovaciho reziva, tramu, prken a stepky. Dodavame soukromym klientum i firmam stalou kvalitu, konkurenceschopne ceny a dodavky po cele Ceske republice.
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый мог разобраться в предмете и извлечь из него максимум пользы.
Узнать напрямую - https://ramirezpedrosa.com/budgeting/how-to-protect-your-wealth-during-market-volatility
Grand River Choices – Well-arranged items, making navigation simple and satisfying.
Этот обзор дает возможность взглянуть на историю и науку под новым углом. Мы представляем редкие факты, неожиданные связи и значимые события, которые помогут вам глубже понять развитие цивилизации и роль человека в ней.
Получить профессиональную консультацию - https://videogamegalaxy.com/si-une-jaquette-metait-contee-fortified-zone
GlobalRidge Picks – Neatly arranged items with smooth navigation for a pleasant shopping experience.
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Узнайте всю правду - https://www.andebu.org/2018/01/17/bitcoin-is-the-gag-gift
Best ssd vps europe. Only TOP European data centers in Estonia, Finland, Germany. All servers are GDPR compliant, blazing fast NVMe SSD drives, reliable network 10+ Gbps, selection of OS templates, 24/7 monitoring, easy remote management.
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Прочитать подробнее - http://officeemployer.blog.usf.edu/?page_id=15
Prodej reziva https://www.kup-drevo.cz v Ceske republice: siroky vyber reziva, stavebniho a dokoncovaciho reziva, tramu, prken a stepky. Dodavame soukromym klientum i firmam stalou kvalitu, konkurenceschopne ceny a dodavky po cele Ceske republice.
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Изучить вопрос глубже - http://www.onlinepokies.com.au/big-chef-wild
Global Ridge Market – Well-structured pages and intuitive interface make exploring enjoyable.
Street Trend Hub – Well-arranged urban pieces and smooth site navigation enhance the experience.
Professional backup in europe secure, efficient, fast and privacy-focused reliable FTP Backup storage in Europe. 100% Dropbox European alternative. Protection on storage account. Choose European Backup Storage for peace of mind, security, and reliable 24x7x365 data management service.
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальные Insights и полезные сведения для дальнейшего изучения.
Выяснить больше - https://hakol-laganz.co.il/product/%D7%93%D7%92%D7%9D-%D7%90%D7%95%D7%A1%D7%A7%D7%94-%D7%9C%D7%9C%D7%90-%D7%94%D7%A9%D7%95%D7%9C%D7%97%D7%9F
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Подробнее можно узнать тут - https://312.kg/plastikovye-okna-v-bishkeke
Street Style Hub – Fast-loading pages with neat urban fashion displays and easy navigation.
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Жми сюда — получишь ответ - https://www.deambulatori.com/nrs-healthcare-m66739
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Уточнить детали - https://fx7.xbiz.jp/fx-shikinkanri
TTS Modern Picks – Stylish selections presented nicely, exploring was effortless.
TTS Picks Online – Stylish products organized well, moving through pages was smooth.
Color Mea Corner – Unique and inspiring designs arranged neatly, making browsing comfortable.
Color Mea Selection – Creative designs look impressive, and navigation flows effortlessly.
Если на первичном звонке звучат «красные флаги» (выраженная одышка, спутанность сознания, скачки ритма), мы предлагаем стационарное окно мониторинга. При низком риске стартуем дома или амбулаторно и поддерживаем человека вечерними видеовставками по 15–20 минут, чтобы пройти «трудный час» без лишних поездок и паники.
Ознакомиться с деталями - http://vyvod-iz-zapoya-v-voronezhe15.ru/vyvod-iz-zapoya-na-domu-voronezh/
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Подробнее - https://baratijasbonitas.com/dia-de-la-madre-20-ideas-para-regalo
Наши стандарты включают конфиденциальную маршрутизацию, детализированные инструкции для семьи, модульный план лечения и прозрачное разделение бесплатных и платных блоков. Каждому пациенту назначается ведущий специалист, который сопровождает его на всём пути — от первого звонка до контрольных чек-инов после процедур. Мы не «наращиваем» объём вмешательств ради впечатления: используется минимально достаточный набор мер, который действительно влияет на целевые маркеры — переносимость воды, качество сна, сглаживание вегетативных «качелей» и возвращение утренней ясности.
Узнать больше - наркологическая клиника лечение алкоголизма челябинск
Вызов электрика https://vash-elektrik24.ru на дом в Москве: оперативный выезд, поиск и устранение неисправностей, установка розеток и выключателей, подключение техники, ремонт проводки. Квалифицированные мастера, точные цены, гарантия на работы и удобное время приезда.
Хочешь сдать авто? https://vykup-auto78.ru/ быстро и безопасно: моментальная оценка, выезд специалиста, оформление сделки и мгновенная выплата наличными или на карту. Покупаем автомобили всех марок и годов, включая битые и после ДТП. Работаем без скрытых комиссий.
Вызов электрика https://vash-elektrik24.ru на дом в Москве: оперативный выезд, поиск и устранение неисправностей, установка розеток и выключателей, подключение техники, ремонт проводки. Квалифицированные мастера, точные цены, гарантия на работы и удобное время приезда.
Наркологическая клиника «ДонМед Резонанс» — это круглосуточный комплекс координированной помощи, где диагностика, инфузионная терапия, психообразование и поддержка семьи соединены в единую «дорожную карту». Мы работаем по принципу минимально достаточных вмешательств: каждый шаг имеет цель, измеримый маркер и заранее обозначенное «окно оценки». Такой подход убирает полипрагмазию, снижает риск нежелательных реакций и делает траекторию лечения предсказуемой — пациент не «получает процедуры», а видит, как цели достигаются и какие модули выключаются, когда они сделали своё дело. Круглосуточный режим позволяет внимательно сопровождать самые чувствительные интервалы — первую ночь, утренний период после детоксикации и момент возвращения к бытовой активности.
Разобраться лучше - платная наркологическая клиника в ростове-на-дону
заказать натяжные потолки
Они отличаются практичностью и долговечностью.
Компания "natyazhni-steli-vid-virobnika.biz.ua" предлагает качественные потолки напрямую от производителя. Клиенты получают гарантированно надежные решения.
#### **2. Преимущества натяжных потолков**
Одним из главных плюсов натяжных потолков является их влагостойкость. Даже при затоплении потолок останется целым.
Еще одно преимущество — огромный выбор цветов и фактур. Дизайнеры помогут создать уникальный стиль для вашего помещения.
#### **3. Производство и материалы**
Наша компания изготавливает потолки из экологически чистого ПВХ. Материал абсолютно безопасен для здоровья.
Технология производства гарантирует прочность и эластичность полотна. Мы тщательно контролируем каждый этап создания продукции.
#### **4. Установка и обслуживание**
Монтаж натяжных потолков занимает всего несколько часов. Уже через день вы сможете пользоваться обновленным помещением.
Уход за потолком не требует особых усилий. Пятна и пыль легко удаляются без специальных средств.
---
### **Спин-шаблон статьи**
#### **1. Введение**
Компания "natyazhni-steli-vid-virobnika.biz.ua" работает напрямую с клиентами без посредников.
#### **2. Преимущества натяжных потолков**
Выбор оформления практически безграничен — от классики до 3D-эффектов.
#### **3. Производство и материалы**
Каждый экземпляр проходит многоступенчатый контроль.
#### **4. Установка и обслуживание**
Профессиональный монтаж исключает ошибки и обеспечивает идеальный результат.
University VSU named P.M. Masherov offers modern educational programs, a strong faculty, and an active student life. Practice-oriented training, research projects, and international collaborations help students build successful careers.
Хочешь сдать авто? продать авто срочно спб быстро и безопасно: моментальная оценка, выезд специалиста, оформление сделки и мгновенная выплата наличными или на карту. Покупаем автомобили всех марок и годов, включая битые и после ДТП. Работаем без скрытых комиссий.
Трастовый поставщик марокетплейс аккаунтов предлагает доступ приобрести прогретые профили для бизнеса. Ключевое преимущество данной площадки — заключается в наличие эксклюзивной базы знаний, в которой выложены секретные схемы по заливу. На сайте доступны акки Google, Twitter, Telegram для любых задач: от авторегов и заканчивая трастовыми кабинетами с отлежкой. Переходите в наше комьюнити, читайте полезные кейсы, общайтесь и делайте профит на наших расходниках без задержек.
Skyline Fashion Boutique – Easy to browse, stylish items arranged clearly with quick loading pages.
Skyline Fashion Collections – Quick-loading pages, trendy products easy to view, browsing is enjoyable.
Все современные специальности ВГУ им. Машерова в одном разделе: список факультетов, направления подготовки, краткие описания программ, длительность обучения, квалификация выпускника и основные дисциплины. Помогаем абитуриентам выбрать подходящую профессию и траекторию обучения.
ChoiceHubOnline – Attractive layout, premium items, and convenient navigation.
Leading vendor here greets advertisers to the comprehensive catalog of marketing tools. The core value of our shop is the availability of an extensive learning center, where you can find secret manuals about social media marketing. Inside the materials, we share hacks on using cloaking tools to increase efficiency in your marketing efforts. Our inventory contains pages for FB, Insta, Telegram for any purpose: ranging from freshly registered up to trustworthy profiles with history.
NatureCorner – Fast-loading pages with a cozy, rustic feel enhance browsing.
Конфиденциальность обеспечивается процессом: нейтральные формулировки в документах, минимум персональных данных, немаркированные формы и транспорт, отдельный вход, «короткие» переговоры у двери, единый контакт по медицинским вопросам. Внутри команды действует «язык цифр» — витальные показатели, шкалы, интервалы питья и сна, окна проверки. Это исключает лишние обсуждения и защищает от распространения деликатной информации за пределы клинического круга.
Разобраться лучше - [url=https://narkologicheskaya-clinika-v-rostove-na-donu16.ru/]запой наркологическая клиника в ростове-на-дону[/url]
ChoiceCenterOnline – Clean interface, easy navigation, and top-notch items.
brightbazaar – Loved the neat layout, shopping felt straightforward and quick.
NatureVault – Smooth site performance with well-displayed rustic products.
В реальной городской ткани Ставрополя на самочувствие влияет не только схема лечения, но и логистика: утренние заторы на въезде, плотная застройка частного сектора, шумные перекрёстки. Мы заранее «поглощаем» эти риски организацией: секторные выезды, согласованная парковка, нейтральная переписка без «говорящих» терминов, при необходимости — курьерская доставка расходников отдельно от врача, чтобы на месте сразу переходить к оценке и запуску инфузии. Пациенту не нужно «вписываться» в систему — система подстраивается под реальную жизнь человека, экономя десятки минут и снижая сенсорную нагрузку перед первой ночью.
Исследовать вопрос подробнее - [url=https://narkologicheskaya-klinika-v-stavropole15.ru/]наркологическая клиника лечение алкоголизма[/url]
Лечебная логика строится по принципу «одна цель — один маркер — одно окно оценки — один выключатель». Например, задача «открыть окно питья» решается антиеметическим мостом и мягкой регидратацией; как только вода пьётся без позывов и появляется стабильный диурез, модуль отключается. Если целевой маркер «ЧСС/АД в рабочем коридоре» достигнут — снимаем антивегетативный контур. Это дисциплина маленьких шагов, где каждый следующий ход становится очевидным из предыдущих цифр, а не из ожиданий.
Получить дополнительную информацию - https://narkolog-na-dom-v-krasnodare16.ru/narkolog-i-psikhiatr-v-krasnodare
creststylehub – Simple interface and clear layout, shopping felt quick.
Outlet of Fresh Fashion – The catalog felt lively, pages loaded instantly, and the visit was enjoyable.
Вакансии ООО Торгово-транспортное предприятие "Острое Жало" на avito. ru
FreshStyle Select – The browsing flow felt quick, and the overall presentation was sharp.
TCS Picks Hub – Loved the modern display, browsing items felt effortless.
Trendy Collection Hub Online – Modern layout with clear product display, browsing was simple.
Today’s gaming world is more exciting than ever, and any enthusiast can discover their perfect experience. No matter what genre you love, the thrill of competition keeps players coming back.
With platforms like Playamo, players can enjoy smooth gameplay, exclusive features that enhance the journey, and a space built for true gamers. Start your next adventure and explore the world of gaming today!
https://gyn101.com/
https://gyn101.com/
Hidden Valley Collection Hub – Well-presented items, making exploring and discovering treasures effortless.
В первые два часа после прибытия бригады важно не «сделать побольше», а принять наименьшее количество решений, которое реально меняет картину. Команда фиксирует базовую линию (ЧСС, АД, SpO?, температура, шкала тошноты/тремора), даёт антиеметический мост и запускает регидратацию. При тахикардии — добавляет антивегетативный контур. Семья получает сценарий ночи: когда приглушить свет, когда предложить воду, какие цифры на тонометре считать нормой и при каких — звонить. Такой протокол экономит время и силы, а главное — превращает вечер из хаотичного в управляемый, снижая риск ночных экстренных вызовов и «эмоциональных качелей».
Подробнее можно узнать тут - капельница от запоя недорого
«Волшебной капельницы» не существует. Мы структурируем инфузии от симптомов, а не от «средних рецептов». Ниже — логика подбора для типичных профилей; реальную схему определяет врач на месте.
Изучить вопрос глубже - [url=https://narkologicheskaya-klinika-v-kaliningrade15.ru/]вывод наркологическая клиника[/url]
копирайтер вакансии удаленная работа Находки ВБ мужские – это баланс между практичностью и индивидуальностью. От классических костюмов, подчеркивающих деловой статус, до удобной спортивной одежды, располагающей к активному отдыху, от стильных аксессуаров, добавляющих образу изюминку, до полезных гаджетов, облегчающих повседневные задачи – здесь мужчины могут найти все необходимое для создания уверенного и респектабельного образа. Естественно, находки ВБ для парней ориентированы на более молодежную аудиторию.
Hidden Valley Online – Unique treasures showcased neatly, navigation flows seamlessly.
TCI Practical Picks – Creative products arranged nicely, browsing felt natural and easy.
Think Create Innovate Shop – Loved the inspiring vibe, finding items was smooth and simple.
Впечатился работой этой фирмы. Всё произошло без лишней суеты. Менеджер дал массу полезных советов. Оперативно подобрали и доставили. Всем знакомым советую эту компанию https://gribisrael.borda.ru/?1-10-0-00000127-000-0-0-1764787003
Наркологическая клиника в Краснодаре специализируется на лечении алкогольной, наркотической и других видов зависимостей с использованием современных медицинских технологий и индивидуальных программ терапии. Работа специалистов направлена на устранение физической зависимости, восстановление психоэмоционального состояния и возвращение пациента к полноценной жизни. Все процедуры проводятся в безопасных условиях с соблюдением принципов анонимности и врачебной тайны.
Разобраться лучше - [url=https://narkologicheskaya-klinika-v-krasnodare16.ru/]наркологическая клиника цены краснодар[/url]
Cryptocasino reviews https://crypto-casinos-canada.com in Canada - If you're looking for fast BTC/ETH transactions and clear terms, cryptocasino reviews will help you evaluate which platforms offer transparent bonuses and consistent payouts.
BankID-fria kasinon https://casinos-utan-bankid.com Manga spelare forbiser hur mycket uttagsgranser och verifieringskrav varierar, men BankID-fria kasinon hjalper dig att jamfora bonusar, betalningsmetoder och tillforlitlighet.
Casinos, die Paysafecard https://paysefcard-casino-de.info akzeptieren: Viele Spieler in Deutschland mochten ihr Konto aufladen, ohne ihre Bankdaten anzugeben. Casinos, die Paysafecard akzeptieren, ermoglichen sichere Prepaid-Einzahlungen mit einem festen Guthaben. So behalten Sie die volle Kontrolle uber Ihre Ausgaben und konnen weiterhin Spielautomaten und Live-Dealer-Spiele spielen.
Качество — это не субъективные впечатления, а сравнение базовой линии с целевыми коридорами в обозначенных окнах. Мы ведём короткий отчёт по маркерам: переносимость воды (мл/ч), диурез, ЧСС/АД в покое, структура сна (длительность и число пробуждений), динамика по шкалам тошноты/тремора, выполнение двух утренних бытовых задач. Отчёт понятен пациенту: в нём нет лишней терминологии, только факты и решения — какой модуль снят, какой оставлен ещё на ночь, какой будет пересмотрен через 12–24 часа. Финансовая прозрачность следует той же логике: расширение проводится только по показаниям с указанием цели («какой маркер планируем улучшить») и окна переоценки («когда проверяем результат»).
Подробнее тут - https://narkologicheskaya-klinika-v-rostove-na-donu16.ru/narkologi-rostov-na-donu
Motivation Finds Hub – Fast-loading, clean pages with motivating content for easy exploration.
Проблемы с алкоголем? круглосуточный стационар вывод из запоя: анонимная помощь, круглосуточный выезд врача, детоксикация, капельницы, стабилизация состояния и поддержка. Индивидуальный подход, современные методы и контроль здоровья. Конфиденциально и безопасно.
FindMotivation Hub – Clear, uplifting articles combined with seamless navigation flow.
Проблемы с алкоголем? вывод из запоя кодировка на дому: анонимная помощь, круглосуточный выезд врача, детоксикация, капельницы, стабилизация состояния и поддержка. Индивидуальный подход, современные методы и контроль здоровья. Конфиденциально и безопасно.
стоимость написания курсовой работы на заказ kupit-kursovuyu-24.ru .
Мы избегаем шаблонов. Состав инфузий и порядок действий подбираются индивидуально: учитываем тяжесть интоксикации, сопутствующие заболевания, чувствительность к свету и шуму, объём воды, который человек переносит малыми глотками, а также, как реагирует на вечерние уведомления телефона. Главная цель первых часов — стабилизировать витальные показатели, вернуть переносимость питья и лёгкой тёплой пищи, выровнять вариабельность пульса к сумеркам и обеспечить физиологичный сон без «переседации». Все измерения фиксируются в краткой карте наблюдения с разграничением доступа по ролям — это защищает данные и ускоряет принятие решений.
Получить дополнительные сведения - http://vyvod-iz-zapoya-v-kaliningrade15.ru/klinika-vyvod-iz-zapoya-kaliningrad/
Today’s gaming world is full of limitless possibilities, and any enthusiast can find something unique. Whether you prefer fast-paced action, the thrill of competition keeps players coming back.
With platforms like Playamo, users get access to top-tier gaming experiences, innovative tools that enhance the journey, and a space built for true gamers. Dive in and embrace your inner gamer today!
https://gyn101.com/
https://gyn101.com/
Капельницы в «ЧелМед Детокс» — это модульная конструкция, а не «микс на удачу». База — регидратация и коррекция электролитов. По показаниям добавляются антиэметики, антивегетативные средства, поддержка метаболизма, витамины группы B, магний. Отдельным блоком идёт ночной модуль: задача — собрать восстановительный сон, не «перелечивая» пациента. Каждый модуль имеет свою цель и стоп-критерий. Врач избегает одновременного запуска нескольких новых элементов, чтобы видеть причинно-следственную связь и точно понимать, что именно работает у конкретного человека.
Получить дополнительную информацию - нарколог на дом вывод из запоя челябинск
SoftPeak Hub Online – Clean layout, items clearly displayed, browsing experience feels pleasant.
Explore Adventure Hub – The adventurous theme is appealing, and the site runs seamlessly.
SoftPeak Selection Hub – Easy browsing, layout simple and intuitive, products presented nicely.
CopperLaneMall – Great assortment available, with clean sections that make browsing effortless.
сайт для заказа курсовых работ http://kupit-kursovuyu-24.ru/ .
Next Adventure Hub – The site feels exciting, with an adventurous layout and smooth browsing.
LaneOfCopperOutlet – Deals look well organized, and the simple layout offers a smooth experience.
Капельницы в «ЧелМед Детокс» — это модульная конструкция, а не «микс на удачу». База — регидратация и коррекция электролитов. По показаниям добавляются антиэметики, антивегетативные средства, поддержка метаболизма, витамины группы B, магний. Отдельным блоком идёт ночной модуль: задача — собрать восстановительный сон, не «перелечивая» пациента. Каждый модуль имеет свою цель и стоп-критерий. Врач избегает одновременного запуска нескольких новых элементов, чтобы видеть причинно-следственную связь и точно понимать, что именно работает у конкретного человека.
Подробнее тут - вывод из запоя на дому круглосуточно в челябинске
Все шаги фиксируются в карте наблюдения. Если динамика «плоская», меняется один параметр (скорость/объём/последовательность), и через оговорённое окно проводится повторная оценка. Это снижает риск побочных реакций и сохраняет дневную ясность.
Ознакомиться с деталями - https://narkologicheskaya-klinika-v-kaliningrade15.ru/vyvod-iz-zapoya-kaliningrad-staczionar/
Эта схема помогает постепенно вывести пациента из кризисного состояния, снизить риски осложнений и закрепить результаты лечения.
Узнать больше - https://narkologicheskaya-klinika-v-krasnodare16.ru/anonimnaya-narkologicheskaya-klinika-krasnodar
WildCollection Online – Sleek pages and easy-to-navigate product displays give a modern feel.
WildflowerFinds – Browsing is smooth and products are clearly displayed throughout.
Relevant tips: https://claire-garand.fr
Current Updates: http://www.rivierapokerclub.fr
Trusted and best: https://diablotine-coiffure-mode-solomiac.fr
NaturePeak – Products arranged neatly and site navigation feels effortless.
FutureWild Online – Smooth page transitions and stylish layout make exploring products easy.
bukmacher internetowy mostbet pl oferuje szeroki wybor zakladow sportowych, zakladow na zywo i slotow od czolowych dostawcow. Oferuje szybka rejestracje, bonusy dla nowych graczy, przyjazna dla uzytkownika aplikacje mobilna, natychmiastowe wyplaty i calodobowa obsluge klienta.
Наркологическая клиника «КарелМед Центр» — это круглосуточное лечение, современное оборудование и предсказуемые протоколы, которые избавляют пациента и семью от догадок. Мы не используем «универсальные сильные капельницы» и не усиливаем схему «на всякий случай»: каждое вмешательство имеет понятную цель, измеримые маркеры и заранее оговорённое окно повторной оценки. Такой подход снижает фармаконагрузку, бережёт сон, сокращает вечернюю реактивность и делает первую ночь спокойнее. Анонимность встроена в процессы: немаркированные входы, гражданская одежда персонала, нейтральные формулировки в документах и «беззвучные» уведомления по согласованным каналам связи.
Подробнее - http://narkologicheskaya-klinika-petrozavodsk15.ru
Карта делает маршрут прозрачным для пациента и семьи. Вместо «лучше/хуже» — факты и понятные пороги. Это снижает тревожность и помогает соблюдать режим без сопротивления.
Ознакомиться с деталями - https://narkologicheskaya-klinika-petrozavodsk15.ru/chastnaya-narkologicheskaya-klinika-petrozavodsk/
bukmacher internetowy mostbet casino oferuje szeroki wybor zakladow sportowych, zakladow na zywo i slotow od czolowych dostawcow. Oferuje szybka rejestracje, bonusy dla nowych graczy, przyjazna dla uzytkownika aplikacje mobilna, natychmiastowe wyplaty i calodobowa obsluge klienta.
FreshValue Store – Items were laid out clearly, and page transitions were quick and stable.
Updates on the Topic: https://www.als-photo.fr
Today's Most Important: https://m-g.wine
Read more on the website: https://www.gilmaire-etienne.com
Budget Value Outlet – Everything felt simple to access, and the pages loaded without delay.
Trendy Purchase Hub – Great variety of products, navigation around the site was simple.
PureStyleOutlet – Clean layout, trendy items, and effortless site experience.
Мы собираем терапию как конструктор из узких модулей. Каждый модуль запускается только при показаниях и выключается сразу после достижения цели — это защищает от «инерции лечения» и возвращает организму пространство для самостоятельной регуляции. Ниже — ориентировочная сетка модулей; фактический состав и дозировки определяет врач на очном осмотре.
Исследовать вопрос подробнее - [url=https://narkologicheskaya-clinika-v-rostove-na-donu16.ru/]наркологическая клиника вывод из запоя ростов-на-дону[/url]
TPH Trend Store – Clean layout with modern items, moving around pages felt seamless.
Для наглядности представлен примерный состав инфузионного раствора, используемого при выводе из запоя:
Углубиться в тему - [url=https://vyvod-iz-zapoya-v-rostove-na-donu16.ru/]вывод из запоя на дому цена[/url]
Highland Craft Finds – Well-presented items, navigation feels intuitive and fast.
ChicChoiceStore – Modern design, easy-to-browse sections, and fashion-forward selection.
Highland Craft Picks Hub – Beautifully displayed crafts, with smooth and comfortable navigation.
Для наглядности представлена таблица с основными направлениями терапии и их эффектами:
Углубиться в тему - [url=https://narkologicheskaya-klinika-v-krasnodare16.ru/]наркологическая клиника клиника помощь краснодар[/url]
Мы придерживаемся инженерной логики: цель > маркер > окно проверки > отключение модуля. Никаких «сильных коктейлей на всякий случай»: сначала один точный шаг, затем — проверка результата. Именно так формируется прозрачность и доверие: пациент видит причину каждого назначения и понимает момент его завершения. Это уменьшает тревогу, ускоряет восстановление и убирает «инерцию лечения», когда лишние вмешательства продолжаются просто по привычке.
Получить больше информации - http://narkolog-na-dom-v-samare16.ru/
Индексация пенсий Предпенсионный возраст – особый период в жизни человека, когда особенно важна поддержка государства и общества. Льготы предпенсионерам призваны обеспечить плавный переход к пенсионной жизни, защитить от дискриминации на рынке труда, предоставить возможности для переобучения и повышения квалификации. Забота о предпенсионерах – это инвестиция в будущее, гарантия того, что люди, готовящиеся к заслуженному отдыху, будут чувствовать себя уверенно и защищенно.
Состояния при зависимостях чувствительны к времени суток и среде. К ночи нарастает тревога, усиливается тремор, нестабильны показатели ЧСС/АД. Круглосуточный приём позволяет выстроить «мост» через самые сложные часы: собрать сон без избыточной фармаконагрузки, сделать короткие чек-ины, вовремя ретитровать один параметр (свет, дыхательные ритмы, интервалы питья), а утром оформить «малые победы» — гигиена и 10–15 минут тихой ходьбы. Эти простые маркеры часто надёжнее любых субъективных оценок «как себя чувствую».
Выяснить больше - [url=https://narkologicheskaya-clinika-v-rostove-na-donu16.ru/]наркологические клиники алкоголизм ростов-на-дону[/url]
Shop SoftStone – Well-organized layout, effortless navigation, and items presented nicely.
Вся динамика фиксируется в единой карте наблюдения. При переводе в амбулаторную точку мы не «сбрасываем» историю: решения продолжаются с учётом уже сделанного и реакции пациента на вмешательства.
Детальнее - [url=https://vyvod-iz-zapoya-v-voronezhe15.ru/]вывод из запоя недорого в воронеже[/url]
Offer Highlights – Everything appears well-sorted, making it simple to check out the latest offers.
SoftStone Emporium Hub – Layout is simple and intuitive, products displayed attractively, browsing is smooth.
Offer Highlights – Everything appears well-sorted, making it simple to check out the latest offers.
В городе и ближайших районах клиника «УралМед Трезвость» обеспечивает оперативный выезд и амбулаторный приём без очередей. На этапе первичного контакта координатор уточняет только клинически значимые моменты: постоянные препараты и дозы, аллергии, эпизоды судорог/психозов в прошлом, базовые показатели (АД/ЧСС/SpO?, если доступны), длительность симптомов, возможность организовать «тихое окно» на 20–30 минут. Вместо долгих разговоров — короткая, спокойная логика: где безопаснее начать (дом/амбулатория/стационар), какую ближайшую цель выбираем, в каком интервале ждём эффект и что считаем сигналом для связи с дежурным врачом.
Подробнее тут - наркологическая клиника наркологический центр
Ниже — структурированная карта экстренного выезда. Она помогает пациенту и семье понимать, что происходит в каждый отрезок времени, какие цели мы преследуем и по каким критериям двигаемся дальше.
Ознакомиться с деталями - [url=https://vyvod-iz-zapoya-v-voronezhe15.ru/]вывод из запоя на дому круглосуточно воронеж[/url]
Нарколог на дом в Челябинске — это услуга, которая позволяет получить профессиональную медицинскую помощь при алкогольной или наркотической интоксикации без необходимости посещения клиники. Такой формат особенно востребован в случаях, когда пациент не может самостоятельно прибыть в медицинское учреждение или нуждается в конфиденциальной помощи. Врач-нарколог выезжает по указанному адресу, проводит осмотр, оценивает состояние и подбирает оптимальную терапию. Квалифицированное вмешательство помогает избежать осложнений и стабилизировать состояние уже в течение первых часов после прибытия специалиста.
Подробнее - нарколог на дом клиника в челябинске
Fresh Buy Lane – Trendy selection presented neatly with smooth page flow and organized sections.
Первая задача при выезде — быстро отделить угрозы от симптомов, которые можно безопасно стабилизировать на дому. Таблица ниже иллюстрирует, как стартовые наблюдения превращаются в проверяемые гипотезы, конкретные действия и решения в «окнах оценки». Она не заменяет очной диагностики, а объясняет архитектуру первых часов, чтобы у семьи был ясный ориентир.
Подробнее - [url=https://narkolog-na-dom-v-krasnodare16.ru/]нарколог на дом недорого[/url]
отражающая изоляция Тенты – это мобильная крыша над головой, готовая защитить от дождя, солнца и ветра в любой ситуации. Туристы, строители, дачники – все найдут в тенте верного союзника, способного создать комфортные условия для работы и отдыха. Разнообразие размеров, форм и материалов позволяет выбрать тент, идеально соответствующий поставленной задаче.
FreshBuy Finds Hub – Trendy items arranged clearly with smooth navigation for effortless shopping.
Стоимость и состав зависят от длительности вмешательства, выраженности симптомов и сопутствующих рисков. Мы избегаем универсальных «коктейлей»: комплектация пакета формируется по маркерам, которые видим на месте. Ниже — ориентиры, помогающие заранее понимать логику и наполнение.
Подробнее - http://narkologicheskaya-klinika-v-nizhnem-novgorode16.ru/
WildNorthernFinds – Quick-loading pages and easy-to-find items make browsing enjoyable.
CloverCozyFinds – Attractive cozy pieces, easy navigation, and an overall soothing feel throughout.
NorthHubSpot – Well-organized items, fast-loading site, and effortless navigation for users.
CozyClovShop – Everything looks pleasant and well-organized, making browsing peaceful and smooth.
Autumn Peak Studio – Autumn-style items look charming, and the browsing experience feels calm and easy today.
crestartoutlet – Pages load fast and products are easy to locate, shopping felt pleasant.
Peak Studio Finds – Warm seasonal selections stand out, and the site flows naturally while exploring.
Fashion Finds Worldwide – The site felt smooth to navigate and the styles looked sharp today.
artisancentral – Smooth and simple navigation, browsing was very convenient.
Style Hub Worldwide – Easy to navigate sections and plenty of stylish pieces to look at.
Этот список — памятка на холодильник. Он не раскрывает диагноз, но точно описывает поводы для связи с дежурным врачом. Своевременная эскалация — часть безопасности, а не «подстраховка». Если сомневаетесь — лучше позвонить.
Получить дополнительную информацию - капельница от запоя цена в челябинске
Городская среда Петрозаводска со сменой ветров с Онежского озера, короткими сумерками и сезонными перепадами влажности может усиливать тревожность в вечерние часы. Мы учитываем это с момента первого контакта: согласованная парковка, отдельный вход без вывесок, короткая регистрация без «толстых анкет», приглушённый тёплый свет в зоне ожидания и отсутствие громких объявлений. Родственникам предоставляются «тихие окна» связи — лаконичные апдейты в фиксированное время, чтобы не перегружать пациента и не дёргать команду в критические окна наблюдения. Такой «мягкий» контур снижает сенсорную нагрузку, стабилизирует вариабельность ЧСС к сумеркам и сокращает число импульсивных просьб «усилить на ночь».
Углубиться в тему - [url=https://narkologicheskaya-klinika-petrozavodsk15.ru/]вывод наркологическая клиника в петрозаводске[/url]
Капельница — основной метод дезинтоксикации при запое. Она позволяет быстро восполнить дефицит жидкости и электролитов, вывести токсины и улучшить общее самочувствие. В состав инфузии входят препараты, нормализующие обмен веществ, а также витамины и гепатопротекторы. Процедура проводится под контролем врача, что гарантирует безопасность и точную дозировку лекарств.
Получить дополнительную информацию - [url=https://vyvod-iz-zapoya-v-rostove-na-donu16.ru/]наркология вывод из запоя в ростове-на-дону[/url]
Детокс — это последовательность целевых действий. Инфузии подбираются индивидуально: цель — восстановить объём циркулирующей крови, скорректировать электролиты, снизить токсическую нагрузку, мягко приглушить тремор и тревогу, вернуть условия для сна. Мы не перегружаем препаратами, не «гоняем» симптом силой седативов и не используем универсальные растворы «для всех». Поддержка сна строится на минимально достаточных дозах и гигиене вечернего времени: затемнение, тишина, отказ от экранов, ранний отбой. Параллельно врач объясняет, как пить воду маленькими порциями, когда сделать лёгкий перекус, зачем планировать короткую дневную паузу. После купирования остроты пациент получает чёткий план на трое суток — простые, реалистичные шаги, которые удерживают эффект без «героизма» и без лишней фармакологической нагрузки. В результате медицинский эффект не растворяется в быту, а закрепляется привычками, которые по силам выполнить сегодня и завтра.
Подробнее можно узнать тут - [url=https://narkolog-na-dom-moskva999.ru/]вызов нарколога на дом[/url]
daily deals corner – Products look attractive, navigating the site is easy and pleasant.
SimpleHome Finds Hub – Smooth scrolling and well-structured sections for easy exploration.
TSO Picks Online – Loved the variety available, navigation around the site felt seamless.
your daily shopping corner – Items are displayed clearly, navigating is quick and easy today.
SimpleHome Select – Neatly displayed items and effortless navigation made exploring simple.
Страх огласки часто тормозит обращение сильнее симптомов. В «Трезвый Пульс» приватность — регламент: подтверждения и согласия — только через защищённые каналы, в расписании — шифры, визиты — без маркировки. Мы заранее согласуем маршрут подъезда и входа, учитывая дворовые проезды и часы пик, чтобы врач не искал дом по навигатору в последнюю минуту. Чем меньше холостых перемещений и социальных контактов, тем ниже тревога, выше приверженность режиму и устойчивее эффект терапии. Такой порядок особенно важен в «тёмные часы» вечера, когда склонность к импульсивным решениям максимальна — отсутствие лишнего шума помогает телу переключиться на восстановление, а не на самооборону.
Получить больше информации - [url=https://narkolog-na-dom-mytishchi9.ru/]врач нарколог на дом анонимно[/url]
Trendy Sale Online – Clear layout with appealing products, moving around the site felt effortless.
High Pine Finds Hub – Deals look appealing, browsing feels effortless and fun.
DealMarketOnline – Solid bargains, easy to browse, and pages load quickly.
High Pine Corner – Beautifully presented products, exploring the site feels effortless.
SimpleMarketDeals – Well-presented products, easy navigation, and smooth shopping flow.
Домашний визит — это медицинская логика без лишней логистики. В мегаполисе каждая задержка увеличивает риски: человек устаёт, растёт тревога, обостряются скачки давления и пульса, а бессонные ночи превращают любые «самодельные» схемы в опасный эксперимент. «Трезвый Стандарт» строит помощь как управляемую последовательность: дежурный врач собирает краткий анамнез (длительность употребления, лекарства, сопутствующие заболевания), уточняет текущие показатели и предлагает безопасную точку входа — выезд на дом или стационар на сутки-двое при высоких рисках. Дом даёт приватность и предсказуемость: знакомая среда снижает стресс, а врач привозит всё для мониторинга и инфузий по показаниям. Ключевой результат первых часов — контролируемый сон, понятный режим гидратации и питания «по силам», а также зафиксированные «красные флажки» для связи. Именно последовательность, а не «сильная капельница любой ценой», делает выездной формат эффективным и безопасным в реальном ритме Москвы.
Ознакомиться с деталями - https://narkolog-na-dom-moskva999.ru/narkolog-na-dom-moskva-kruglosutochno
Детокс — это последовательность целевых действий. Инфузии подбираются индивидуально: цель — восстановить объём циркулирующей крови, скорректировать электролиты, снизить токсическую нагрузку, мягко приглушить тремор и тревогу, вернуть условия для сна. Мы не перегружаем препаратами, не «гоняем» симптом силой седативов и не используем универсальные растворы «для всех». Поддержка сна строится на минимально достаточных дозах и гигиене вечернего времени: затемнение, тишина, отказ от экранов, ранний отбой. Параллельно врач объясняет, как пить воду маленькими порциями, когда сделать лёгкий перекус, зачем планировать короткую дневную паузу. После купирования остроты пациент получает чёткий план на трое суток — простые, реалистичные шаги, которые удерживают эффект без «героизма» и без лишней фармакологической нагрузки. В результате медицинский эффект не растворяется в быту, а закрепляется привычками, которые по силам выполнить сегодня и завтра.
Ознакомиться с деталями - [url=https://narkolog-na-dom-moskva999.ru/]вызвать нарколога на дом[/url]
Страх огласки часто тормозит обращение сильнее симптомов. Мы устраняем барьер процессами: запись и подтверждения через закрытые каналы, шифры вместо ФИО в расписании, немаркированные визиты, доступ к данным по ролям. В клинике нет общих очередей, контакты разнесены по времени; внутри — «тихие коридоры», минимум пересечений с другими посетителями. Документы оформляются минимальным набором персональных сведений, информирование родственников — только с согласия пациента. В выездном формате заранее согласуем «тихий» маршрут по двору и подъезду. Такая деликатная логистика повышает приверженность лечению: когда не страшно «быть узнанным», проще согласиться на помощь вовремя и точнее выполнить план. Это прямой вклад в результат и бюджет: меньше «пожаров» — меньше незапланированных расходов, потому что решения принимаются на фактах, а не на страхе.
Выяснить больше - [url=https://narkologicheskaya-klinika-podolsk9.ru/]наркологические клиники в области[/url]
Запой бьёт по организму не линейно: чем дольше затягивается ситуация, тем сильнее «скачут» давление и пульс, растёт тревога, рушится сон, усиливается тремор и обезвоживание. В городской среде к медицинским рискам добавляется логистика: пробки, необходимость объясняться на ресепшене, ожидание в общих очередях. Формат выезда «Трезвый Подольск» убирает эту инерцию — врач приезжает без маркировки, оценивает состояние на месте, запускает строго необходимую инфузионную терапию и сразу задаёт правила ближайших 48–72 часов. Такой маршрут снижает импульсивность и возвращает управляемость: пациент понимает, что будет через час, вечером и на следующее утро; семья перестаёт «гадать» и действует по согласованному плану. Домашняя капельница не про «чудо-смесь», а про клиническую последовательность: регидратация, коррекция электролитов, мягкая анксиолитическая поддержка при показаниях, гигиена сна и понятные «красные флажки» для связи. Когда каждое действие объяснено простым языком, тревога не подменяет факты, и эффект держится дольше, чем «косметическое облегчение на час».
Узнать больше - http://kapelnica-ot-zapoya-podolsk9.ru/kapelnica-ot-alkogolya-cena-v-podolske/
SoftWindStudio Hub – Navigation was effortless, calm design, and browsing felt smooth.
Петрозаводск добавляет нюансы: влажные сумерки, ветер от Онежского озера, «звонкие» подъезды старого фонда. Поэтому бригада «СеверКар Медикус» приезжает в гражданской одежде, быстро и без лишних фраз. Координатор заранее уточняет код домофона, парковку, «окна связи» для близких; рекомендует приглушить верхний свет, подготовить воду комнатной температуры и свободный доступ к розетке. Такой «тихий сценарий» снижает сенсорную нагрузку, сглаживает пульсовые «пики» к вечеру и помогает заснуть без избыточной фармакологии.
Получить больше информации - https://vyvod-iz-zapoya-petrozavodsk15.ru/
Страх огласки часто тормозит обращение сильнее симптомов. В «Трезвый Пульс» приватность — регламент: подтверждения и согласия — только через защищённые каналы, в расписании — шифры, визиты — без маркировки. Мы заранее согласуем маршрут подъезда и входа, учитывая дворовые проезды и часы пик, чтобы врач не искал дом по навигатору в последнюю минуту. Чем меньше холостых перемещений и социальных контактов, тем ниже тревога, выше приверженность режиму и устойчивее эффект терапии. Такой порядок особенно важен в «тёмные часы» вечера, когда склонность к импульсивным решениям максимальна — отсутствие лишнего шума помогает телу переключиться на восстановление, а не на самооборону.
Получить дополнительную информацию - [url=https://narkolog-na-dom-mytishchi9.ru/]narkolog-na-dom-kruglosutochno[/url]
SoftWind Hub Online – Clean design, easy navigation, and products presented clearly.
Техника помогает, но не доминирует. Мы используем портативные приборы с мягкой индикацией и низким уровнем шума, чтобы не разрушать формирующуюся «ночную кривую». Контроль в остром окне чаще, вечером — мягче: так сохраняется физиология сна и снижается потребность в дополнительной фармакологии.
Выяснить больше - https://narkologicheskaya-klinika-petrozavodsk15.ru/petrozavodsk-narkologiya
Discover Best Offers – The deals here look impressive, and the site layout makes browsing simple.
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Осуществить глубокий анализ - https://sadenir.com.uy/naturalis/2020/02/18/maine-coon-el-gigante-amable
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Узнать больше - https://www.1001expeditions.fr/quelles-sont-les-activites-de-voyages-pour-les-seniors
Статья знакомит с важнейшими моментами, которые сформировали наше общество. От великих изобретений до культурных переворотов — вы узнаете, как прошлое влияет на наше мышление, технологии и образ жизни.
Кликни и узнай всё! - https://fromimaginewithlove.amsterdam/client3
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Кликни и узнай всё! - http://nostalgia.maniowy.net/historia-wsi/category/43-przesiedlenie?start=69460
Статья знакомит с важнейшими моментами, которые сформировали наше общество. От великих изобретений до культурных переворотов — вы узнаете, как прошлое влияет на наше мышление, технологии и образ жизни.
Разобраться лучше - https://plustech.co.in/bajaj-auto-ltd-ptaced-line-at-akurdi-pune-for-ev
Great Deal Hub – The offers are eye-catching, and everything is laid out for quick exploration.
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Информация доступна здесь - https://sarhadkasathi.com/?p=107
Marketplace Picks Midday – Attractive visuals with structured categories make browsing enjoyable.
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Узнать больше - https://cicidesri.com/my-bookings
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Открыть полностью - https://trouwchicks.nl/portfolio/salient-prints/green
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Смотрите также... - https://www.comecon.jp/amazon_haisourfyoukijun
Статья знакомит с важнейшими моментами, которые сформировали наше общество. От великих изобретений до культурных переворотов — вы узнаете, как прошлое влияет на наше мышление, технологии и образ жизни.
Подробнее тут - https://maxfinding.com/cat-battling-severe-illness-opts-to-live-life-to-the-fullest-after-being-abandoned
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Как достичь результата? - https://www.lifelonglerner.com/espresso
Midday Market Corner – Well-arranged products with neat sections ensure effortless browsing.
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Выяснить больше - https://primenewsnet.com/complimentary-decor-and-design-advice-with-summit-park-estates
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Хочешь знать всё? - https://umigaku-hakodate.com/logo
Статья содержит практические рекомендации и полезные советы, которые можно легко применить в повседневной жизни. Мы делаем акцент на реальных примерах и проверенных методиках, которые способствуют личностному развитию и улучшению качества жизни.
Следуйте по ссылке - https://vilagtajolo.hu/kivancsi-vagyok-34-a-cukrasz-aki-sutemeny-lett
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Полная информация здесь - https://nsbarchive.newshelvesbooks.com/ingramspark-logo
The best is collected here: https://evendis.fr
Расширенная статья здесь: https://sdobruchevskiy.ru
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Личный опыт — читайте сами - https://acialis.buzz
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Не упусти важное! - https://mygardenchannel.com/cold-stratification
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Не упусти шанс - https://drsourabhsharmakota.com/portfolio/minimally-invasive-cardiac-surgery
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Прочесть заключение эксперта - https://tecudi.com/produto/corretor-ortopedico-joanete-1-par
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
А что дальше? - https://alpf-lituanie.org/konferencija-2024-kalbu-sinergija-lietuvos-uzsienio-kalbu-bendryste-ir-vizija
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Узнай первым! - https://blog.beagrie.com/2022/04/01/retirement-from-consultancy
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Получить дополнительную информацию - https://www.comecon.jp/bikudon_tablet
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Давай разберёмся досконально - https://www.politraining.upiita.ipn.mx/lecciones/introduccion-a-liderazgo-1o1
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Как это работает — подробно - https://bureauchezsoi.fr/eclairage-teletravail-lumiere-parfaite-concentration-optimale
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Только факты! - http://juegos.es/psvita/sony-da-un-repaso-a-la-historia-de-playstation
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Продолжить чтение - https://www.lara-project.eu/german-research-center-for-artificial-intelligence-dfki/dfki
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Подробная информация доступна по запросу - https://mosaic-platform.com/uncategorized/5-2
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Расширить кругозор по теме - https://www.adarsh.school/2018/12/22/60-years-of-endless-strive-towards-excellence-is-finally-here
Эта статья погружает вас в увлекательный мир знаний, где каждый факт становится открытием. Мы расскажем о ключевых исторических поворотных моментах и научных прорывах, которые изменили ход цивилизации. Поймите, как прошлое формирует настоящее и как его уроки могут помочь нам строить будущее.
Читать полностью - https://accelerathon.eu/valencia-acoge-el-congreso-mundial-del-agua-wex-global-2020
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Изучить вопрос глубже - https://www.defining-blog.ru/category/onlayn
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Смотрите также... - https://globalolivecorp.com/the-health-benefits-of-extra-virgin-olive-oil
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Доступ к полной версии - https://potischool.ge/2024/04/02/2-%E1%83%90%E1%83%9E%E1%83%A0%E1%83%98%E1%83%9A%E1%83%98-%E1%83%90%E1%83%A3%E1%83%A2%E1%83%98%E1%83%96%E1%83%9B%E1%83%98%E1%83%A1%E1%83%AA%E1%83%9C%E1%83%9D%E1%83%91%E1%83%90%E1%83%93%E1%83%9D
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Изучить рекомендации специалистов - https://www.mike-martin.de/?p=277
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Читать далее > - https://arscarrosseriebouw.nl/carrosserieen/plywood/20130909_142635_resized
Публикация предлагает читателю не просто информацию, а инструменты для анализа и саморазвития. Мы стимулируем критическое мышление, предлагая различные точки зрения и призывая к самостоятельному поиску решений.
Что ещё нужно знать? - https://www.accademiainternazionalesenghor.com/articoli/discorso-tenuto-da-aime-cesaire-a-dakar-il-6-aprile-1966
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Подробнее можно узнать тут - https://chiliconkarin.se/2023/03/19/potatis-och-purjoloksoppa
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Обратитесь за информацией - https://intelimindz.com/revolutionize-your-business-with-our-cutting-edge
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Хочешь знать всё? - http://www.pienogele.lt/milk-and-sunny-spring-field-2
TimelessStylePlace – Stylish products displayed well, site loads fast and browsing feels smooth.
UrbanHarbNation – Trendy urban items available, navigation simple and overall experience feels enjoyable today.
UrbanLightSelect – Nice curated products, layout clean and browsing was easy and pleasant.
UrbanWishMarket – Great selection of items, navigation intuitive and browsing feels effortless today.
VioletCrestTrends – Beautifully arranged trendy items, site runs smoothly and looks very modern.
WildBranchCorner – Rustic charm visible, browsing felt comfortable and site layout is well organized.
WildflowerPeak – Lovely natural theme, products displayed clearly and browsing was really smooth today.
WildNorthTrading – Nice variety of items, navigation simple and site loads quickly overall.
WildPathMarket – Pleasant layout with curated items, browsing felt easy and enjoyable today.
FindGreatOffers – Deals displayed nicely, site runs fast and browsing felt effortless indeed.
FindGreatOffers – Great offers available here, navigation smooth and overall experience feels convenient.
FindSomethingBetter – Items look appealing, site layout clean and browsing felt very comfortable.
FindYourAnswers – Helpful resources shown clearly, navigation intuitive and browsing was pleasant today.
FindYourDirection – Motivational content displayed well, site feels organized and browsing was effortless.
FindYourTruePath – Inspiring layout and content, navigation smooth and browsing felt enjoyable overall.
FreshFashionFinds – Trendy products showcased nicely, site loads fast and browsing was very easy.
FreshGiftOutlet – Lovely gift items, layout clean and navigation intuitive and smooth today.
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Читать полностью - https://allyoucaneatgids.nl/hier-eet-je-onbeperkt-streetfood-in-arnhem
Мы предлагаем вам подробное руководство, основанное на проверенных источниках и реальных примерах. Каждая часть публикации направлена на то, чтобы помочь вам разобраться в сложных вопросах и применить знания на практике.
Лучшее решение — прямо здесь - https://universidadiesdi.com/hola-mundo
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Интересует подробная информация - https://tipspercintaan.com/ramalan-zodiak-cinta-besok-13-oktober-2022
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Читать дальше - http://lallamaquiagenssjc.com.br/spotlight-on-nail-trends-whats-buzzing-in-the-industry
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Не упусти важное! - https://pedacodavila.com.br/gastronomia/delicia-oriental
TimelessStylePlace – Stylish products displayed well, site loads fast and browsing feels smooth.
UrbanHarbNation – Trendy urban items available, navigation simple and overall experience feels enjoyable today.
UrbanLightSelect – Nice curated products, layout clean and browsing was easy and pleasant.
UrbanWishMarket – Great selection of items, navigation intuitive and browsing feels effortless today.
VioletCrestTrends – Beautifully arranged trendy items, site runs smoothly and looks very modern.
WildBranchCorner – Rustic charm visible, browsing felt comfortable and site layout is well organized.
WildflowerPeak – Lovely natural theme, products displayed clearly and browsing was really smooth today.
WildNorthTrading – Nice variety of items, navigation simple and site loads quickly overall.
WildPathMarket – Pleasant layout with curated items, browsing felt easy and enjoyable today.
FindGreatOffers – Deals displayed nicely, site runs fast and browsing felt effortless indeed.
FindGreatOffers – Great offers available here, navigation smooth and overall experience feels convenient.
FindSomethingBetter – Items look appealing, site layout clean and browsing felt very comfortable.
FindYourAnswers – Helpful resources shown clearly, navigation intuitive and browsing was pleasant today.
FindYourDirection – Motivational content displayed well, site feels organized and browsing was effortless.
FindYourTruePath – Inspiring layout and content, navigation smooth and browsing felt enjoyable overall.
FreshFashionFinds – Trendy products showcased nicely, site loads fast and browsing was very easy.
FreshGiftOutlet – Lovely gift items, layout clean and navigation intuitive and smooth today.
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Хочу знать больше - https://cubbinthekitchen.com/raspberry-pancakes
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Детали по клику - https://reciclemosmas.com/educacion-ambiental
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Получить исчерпывающие сведения - https://jardinruse.com/les-mains-miroir-du-corps-et-de-lequilibre-interieur
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Неизвестные факты о... - https://thewebsbest.net/want-a-tutor-to-help-you-with-studying
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Осуществить глубокий анализ - https://worldbanks.news/2020/05/13/mcq-questions-loans-and-advances
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Это стоит прочитать полностью - https://www.albertoandrea.it/news/differenze-tra-gelato-artigianale-e-industriale
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Подробнее - https://nationalbeautycompany.com/2021/07/18/in-viverra-faucibus-tellus-sed-cursus-quam-fringilla-sit-amet-6
Этот обзор дает возможность взглянуть на историю и науку под новым углом. Мы представляем редкие факты, неожиданные связи и значимые события, которые помогут вам глубже понять развитие цивилизации и роль человека в ней.
Где можно узнать подробнее? - https://furnisheed.com/types-of-elevators
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Информация доступна здесь - https://www.uyled.com.cn/archives/37153.html
Fresh Home Corner – Attractive visuals and organized layout ensure a smooth shopping flow.
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Детали по клику - https://oposicionespolicialocalzaragoza.es/csl-incorporara-clases-en-diferido
APS Marketplace – Autumn-themed products look nicely arranged, with browsing feeling light and easy.
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальные Insights и полезные сведения для дальнейшего изучения.
Информация доступна здесь - https://bootstrap.ph/2024/05/07/admiral-s-a3000-paper-shredder-machine
Home Fresh Lane – Clean pages with well-arranged products provide an intuitive experience.
Autumn Peak Store – Seasonal designs look appealing, and exploring the site is effortless right now.
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Провести детальное исследование - https://www.abonosycompost.com/como-hacer-compost-con-restos-de-poda
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Уникальные данные только сегодня - https://dadandburied.com/2010/09/23/mmmm-babies
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Что скрывают от вас? - https://www.kirra.jp/2020/06/22/%E3%82%B2%E3%82%B9%E3%83%88%E3%83%8F%E3%82%A6%E3%82%B9%E3%81%AE%E3%83%96%E3%83%AD%E3%82%B0%E5%A7%8B%E3%81%BE%E3%82%8A%E3%81%BE%E3%81%99%EF%BC%81
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальные Insights и полезные сведения для дальнейшего изучения.
Смотрите также... - https://gothamdoughnuts.com/post/indulge-in-these-irresistible-doughnuts-in-melbourne
shopping hub corner – Products appear well curated, navigating is simple and intuitive.
DeepValleyPlace – Affordable products displayed clearly, giving a sense of quality and consistency.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Давай разберёмся досконально - https://zhoubartcenter.com/home/artist-studios
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Изучить вопрос глубже - https://www.radiolibre939.com/?mp-event=tiempo-de-mujer
ValleyValueMart – Items look well-presented with fair prices and an overall reliable feel.
daily deals corner – Products look attractive, navigating the site is easy and pleasant.
Unique Gift Shop Online – Beautifully arranged items, browsing the site felt smooth and convenient.
Living Market Online – Well-organized sections and smooth, effortless browsing experience.
Горячее секс видео Горячее секс видео .
Unique Gift Online Store – Creative gifts presented clearly, browsing through pages felt effortless.
Simple Living Market Hub – Easy-to-navigate categories and a visually pleasant interface.
сайт заказать курсовую работу kupit-kursovuyu-21.ru .
Поэтапная структура терапии делает лечение контролируемым и прогнозируемым, минимизируя риски возникновения осложнений и повторных обострений зависимости.
Исследовать вопрос подробнее - наркологическая клиника нарколог в санкт-петербурге
фен дайсон оригинал фен дайсон оригинал .
написать курсовую на заказ https://www.kupit-kursovuyu-23.ru .
заказ курсовых работ заказ курсовых работ .
сколько стоит заказать курсовую работу www.kupit-kursovuyu-25.ru/ .
Ironline Finds – Marketplace items look durable, navigation is smooth and simple.
StarWayBoutique Hub – Navigation was smooth, boutique items displayed nicely, browsing felt effortless.
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Подробнее - http://dyscalculie-adulte.fr/caroline
Вызов нарколога на дом — это не «капельница как панацея», а управляемая последовательность решений с ясными целями, измеримыми маркерами и понятными «окнами оценки». В «СамарМед Ассист» мы строим лечение из узких модулей: сначала проверяем базовую безопасность (дыхание, сознание, гемодинамика), затем возвращаем переносимость питья, стабилизируем вегетатику, собираем ночь, и только после этого занимаемся дневной выносливостью и бытовой устойчивостью. Такой ритм исключает полипрагмазию, снижает фармаконагрузку и превращает первые часы из хаотичной «борьбы с симптомами» в спокойный, предсказуемый маршрут. Семья получает роль партнёра, а не наблюдателя: по простым ориентирам понятно, что считать нормой, когда звонить врачу и на каком этапе модуль следует «выключить».
Подробнее - выезд нарколога на дом самара
SimpleDealsHub – Great deals available, site navigation is smooth and browsing feels effortless.
Публикация предлагает уникальную подборку информации, которая будет интересна как специалистам, так и широкому кругу читателей. Здесь вы найдете ответы на часто задаваемые вопросы и полезные инсайты для дальнейшего применения.
Жми сюда — получишь ответ - https://www.muharremdemir.com.tr/adiyaman-gezilecek-yerler
Ironline Picks – Market selection looks strong, finding items is easy and efficient.
Первая задача при выезде — быстро отделить угрозы от симптомов, которые можно безопасно стабилизировать на дому. Таблица ниже иллюстрирует, как стартовые наблюдения превращаются в проверяемые гипотезы, конкретные действия и решения в «окнах оценки». Она не заменяет очной диагностики, а объясняет архитектуру первых часов, чтобы у семьи был ясный ориентир.
Углубиться в тему - нарколог на дом анонимно
StarWay Shoppe – Pleasant layout, effortless navigation, products displayed attractively.
DailyDealMarket – Smooth layout, attractive deals, and enjoyable user experience.
??? xxx ?????? ??? xxx ?????? .
В Мурманске длинные сумерки, влажный ветер и «звонкие» подъезды старого фонда повышают чувствительность к свету и звуку. Поэтому выезд «Северный Медлайн» начинается с настройки среды: приглушается верхний свет, обеспечивается проветривание без сквозняка, смартфоны переводятся в «тихий режим» с «белым списком» близких. Только после этого врач проводит осмотр и запускает инфузионную терапию. Такой «тихий» сценарий снижает потребность в седативных препаратах и сохраняет физиологичность сна в первую ночь.
Ознакомиться с деталями - http://vyvod-iz-zapoya-murmansk15.ru
заказать дипломную работу онлайн https://kupit-kursovuyu-25.ru .
курсовая заказать курсовая заказать .
дайсон официальный сайт стайлер для волос с насадками цена купить http://fen-d-3.ru/ .
курсовая работа купить https://kupit-kursovuyu-21.ru .
заказать курсовую работу заказать курсовую работу .
Smiles & Living Store – Clean and cheerful interface with fast navigation and great product variety.
Happy Home Finds – Pages load quickly, and the overall atmosphere feels uplifting.
Каждый пациент проходит последовательный процесс лечения, где основное внимание уделяется безопасности, контролю состояния и постепенной адаптации. При поступлении проводится диагностика с оценкой степени зависимости, сопутствующих патологий и психологических факторов, влияющих на развитие заболевания. На основании полученных данных формируется персонализированный план терапии, включающий медикаментозные и немедикаментозные методы.
Ознакомиться с деталями - наркологическая клиника наркологический центр санкт-петербург
дипломные работы на заказ https://kupit-kursovuyu-27.ru/ .
купить курсовая работа купить курсовая работа .
Discover New Products – Many appealing options here, and browsing the site feels smooth and efficient.
Женский портал https://forthenaturalwoman.com о жизни, красоте и вдохновении: мода, уход за собой, здоровье, отношения, карьера и личные финансы. Полезные статьи, честные обзоры, советы экспертов и истории реальных женщин. Присоединяйтесь к сообществу и находите идеи для себя каждый день.
Главные новости https://mynewsmonitor.com онлайн: самые важные события дня в сжатом и понятном формате. Политика, экономика, общество, мир, наука и культура. Краткие сводки, развёрнутые статьи, мнения экспертов и удобная лента, которая обновляется в режиме реального времени.
где можно заказать курсовую работу где можно заказать курсовую работу .
Наркологическая клиника в клинике в Екатеринбурге — это специализированное медицинское учреждение, где проводится диагностика, лечение и реабилитация людей, страдающих алкогольной или наркотической зависимостью. Комплексный подход включает не только медикаментозную терапию, но и психотерапевтические методики, направленные на восстановление личности и возвращение пациента к социальной активности. Каждое вмешательство проводится с учётом физического состояния, психологического профиля и стадии заболевания. Работа специалистов основана на принципах анонимности, медицинской этики и научно доказанных протоколов лечения.
Получить дополнительные сведения - [url=https://narkologicheskaya-klinika-v-ekb16.ru/]частная наркологическая клиника[/url]
Актуальные и главные https://allnews.in.ua новости: короткие заметки о срочных событиях и развёрнутые аналитические материалы. Помогаем понять, что произошло, почему это важно и к чему может привести. Лента обновляется в течение дня, чтобы вы не упустили ничего значимого.
Главные новости https://newsline.in.ua онлайн: от срочных сообщений до глубоких обзоров и экспертных комментариев. Политика, экономика, безопасность, технологии и культура. Только проверенные факты и удобная лента, чтобы быстро ориентироваться во всём, что происходит.
Discover Top Items – Plenty of quality choices, and navigating around feels intuitive.
заказать курсовую работу качественно заказать курсовую работу качественно .
Женский портал https://forthenaturalwoman.com о жизни, красоте и вдохновении: мода, уход за собой, здоровье, отношения, карьера и личные финансы. Полезные статьи, честные обзоры, советы экспертов и истории реальных женщин. Присоединяйтесь к сообществу и находите идеи для себя каждый день.
Главные новости https://mynewsmonitor.com онлайн: самые важные события дня в сжатом и понятном формате. Политика, экономика, общество, мир, наука и культура. Краткие сводки, развёрнутые статьи, мнения экспертов и удобная лента, которая обновляется в режиме реального времени.
Актуальные и главные https://allnews.in.ua новости: короткие заметки о срочных событиях и развёрнутые аналитические материалы. Помогаем понять, что произошло, почему это важно и к чему может привести. Лента обновляется в течение дня, чтобы вы не упустили ничего значимого.
Главные новости https://newsline.in.ua онлайн: от срочных сообщений до глубоких обзоров и экспертных комментариев. Политика, экономика, безопасность, технологии и культура. Только проверенные факты и удобная лента, чтобы быстро ориентироваться во всём, что происходит.
На протяжении всего периода лечения специалисты клиники контролируют динамику состояния, анализируя результаты лабораторных исследований и поведение пациента. Такой подход позволяет своевременно корректировать терапевтическую схему и предотвращать осложнения. Применяемые методы терапии соответствуют современным стандартам и одобрены медицинскими сообществами.
Подробнее - [url=https://narkologicheskaya-klinika-v-kazani16.ru/]наркологическая клиника клиника помощь[/url]
Для наглядности приведена таблица с примерными направлениями терапии и их результатами:
Выяснить больше - [url=https://narcologicheskaya-klinika-v-chelyabinske16.ru/]наркологическая клиника стационар[/url]
HotDealsNow – Loved the clean layout and smooth navigation, really easy to check offers.
В городе и ближайших районах клиника «УралМед Трезвость» обеспечивает оперативный выезд и амбулаторный приём без очередей. На этапе первичного контакта координатор уточняет только клинически значимые моменты: постоянные препараты и дозы, аллергии, эпизоды судорог/психозов в прошлом, базовые показатели (АД/ЧСС/SpO?, если доступны), длительность симптомов, возможность организовать «тихое окно» на 20–30 минут. Вместо долгих разговоров — короткая, спокойная логика: где безопаснее начать (дом/амбулатория/стационар), какую ближайшую цель выбираем, в каком интервале ждём эффект и что считаем сигналом для связи с дежурным врачом.
Разобраться лучше - [url=https://narkologicheskaya-klinika-v-chelyabinske16.ru/]наркологическая клиника наркологический центр челябинск[/url]
BestBargains – Navigation is effortless, and deals are clearly laid out.
goldenartstore – Smooth pages with clearly arranged products, made browsing a breeze.
Качество — это не субъективные впечатления, а сравнение базовой линии с целевыми коридорами в обозначенных окнах. Мы ведём короткий отчёт по маркерам: переносимость воды (мл/ч), диурез, ЧСС/АД в покое, структура сна (длительность и число пробуждений), динамика по шкалам тошноты/тремора, выполнение двух утренних бытовых задач. Отчёт понятен пациенту: в нём нет лишней терминологии, только факты и решения — какой модуль снят, какой оставлен ещё на ночь, какой будет пересмотрен через 12–24 часа. Финансовая прозрачность следует той же логике: расширение проводится только по показаниям с указанием цели («какой маркер планируем улучшить») и окна переоценки («когда проверяем результат»).
Выяснить больше - вывод наркологическая клиника ростов-на-дону
StoneBridge Shop – Layout is simple, navigation effortless, and products well-arranged.
официальный сайт дайсон в москве интернет магазин www.fen-d-3.ru/ .
Все главные https://ua-news.com.ua новости в одном потоке: актуальные события, важные решения, прогнозы, мнения и аналитика. Помогаем понять, что стоит за заголовками, как события связаны между собой и почему они значимы. Обновления в режиме реального времени.
Главные новости https://ukrnews.in.ua сегодня: политика, экономика, международные события, наука, культура и общественные темы. Оперативные сводки, анализ и подробные статьи. Полная картина дня, собранная в одном месте для удобного и быстрого чтения.
Современный авто https://cargurus.com.ua портал: свежие новости, премьеры, обзоры новых и подержанных автомобилей, тест-драйвы, советы по эксплуатации и страхованию. Удобный поиск по маркам и моделям, рейтинги, подборки и полезные материалы для автолюбителей любого уровня.
Новостной портал https://ua-today.com.ua с акцентом на достоверность: только проверенные источники, факты, комментарии экспертов и глубокая аналитика. Удобная лента событий, фильтры по темам, архив материалов и быстрый доступ к главному за день.
crestartoutlet – Pages load fast and products are easy to locate, shopping felt pleasant.
Наркологическая клиника в клинике в Екатеринбурге — это специализированное медицинское учреждение, где проводится диагностика, лечение и реабилитация людей, страдающих алкогольной или наркотической зависимостью. Комплексный подход включает не только медикаментозную терапию, но и психотерапевтические методики, направленные на восстановление личности и возвращение пациента к социальной активности. Каждое вмешательство проводится с учётом физического состояния, психологического профиля и стадии заболевания. Работа специалистов основана на принципах анонимности, медицинской этики и научно доказанных протоколов лечения.
Исследовать вопрос подробнее - http://narkologicheskaya-klinika-v-ekb16.ru
StoneBridge Finds Online – Navigation feels intuitive, items well-arranged, overall experience smooth.
курсовая заказать недорого http://www.kupit-kursovuyu-24.ru .
Unique Gift Picks – Clean layout with attractive items, browsing was convenient and enjoyable.
Главные новости https://ukrnews.in.ua сегодня: политика, экономика, международные события, наука, культура и общественные темы. Оперативные сводки, анализ и подробные статьи. Полная картина дня, собранная в одном месте для удобного и быстрого чтения.
Все главные https://ua-news.com.ua новости в одном потоке: актуальные события, важные решения, прогнозы, мнения и аналитика. Помогаем понять, что стоит за заголовками, как события связаны между собой и почему они значимы. Обновления в режиме реального времени.
Современный авто https://cargurus.com.ua портал: свежие новости, премьеры, обзоры новых и подержанных автомобилей, тест-драйвы, советы по эксплуатации и страхованию. Удобный поиск по маркам и моделям, рейтинги, подборки и полезные материалы для автолюбителей любого уровня.
Новостной портал https://ua-today.com.ua с акцентом на достоверность: только проверенные источники, факты, комментарии экспертов и глубокая аналитика. Удобная лента событий, фильтры по темам, архив материалов и быстрый доступ к главному за день.
Trend & Style Hub – Stylish items presented clearly, with smooth navigation and pleasant browsing.
UGC Shop Online – Well-organized gift collection, moving around the site felt smooth.
Fresh Season Hub – Well-arranged seasonal items with smooth navigation and quick-loading pages.
дайсон официальный сайт россия http://fen-d-3.ru/ .
В наркологической клинике в Челябинске проводится профессиональная детоксикация — очищение организма от токсинов, накопленных в результате употребления алкоголя или наркотиков. Процедура выполняется под наблюдением специалистов, что исключает риск осложнений и обеспечивает быстрое улучшение самочувствия. Для восстановления функций внутренних органов применяются препараты, стабилизирующие работу печени, сердца и нервной системы. Использование капельниц, витаминов и гепатопротекторов помогает нормализовать обмен веществ и устранить последствия интоксикации.
Подробнее - [url=https://narcologicheskaya-klinika-v-chelyabinske16.ru/]лечение в наркологической клинике в челябинске[/url]
Ниже — ориентировочная матрица первых часов. Она не заменяет очной оценки, но показывает, как мы переводим наблюдения в действия и какие критерии считаем достаточными для переключения модуля. Приведённые окна проверки помогают не тянуть с нужными корректировками и одновременно не «дергать» схему без повода.
Получить дополнительную информацию - https://narkologicheskaya-clinika-v-rostove-na-donu16.ru/narkologiya-rostov-kruglosutochno/
помощь студентам и школьникам www.kupit-kursovuyu-24.ru .
TrendAndStyle Market – Easy-to-navigate layout and visually appealing product presentation.
FreshSeason Picks Hub – Well-laid-out pages and clearly showcased seasonal items make shopping effortless.
growth shop daily – Products feel well curated, navigating feels fast and easy.
FashionFresh Lane – Stylish arrangement of products with responsive pages enhances usability.
Iron Root Collection – Products showcased neatly, navigation feels intuitive and enjoyable.
где можно заказать курсовую где можно заказать курсовую .
Наркологическая клиника «ДонМед Резонанс» — это круглосуточный комплекс координированной помощи, где диагностика, инфузионная терапия, психообразование и поддержка семьи соединены в единую «дорожную карту». Мы работаем по принципу минимально достаточных вмешательств: каждый шаг имеет цель, измеримый маркер и заранее обозначенное «окно оценки». Такой подход убирает полипрагмазию, снижает риск нежелательных реакций и делает траекторию лечения предсказуемой — пациент не «получает процедуры», а видит, как цели достигаются и какие модули выключаются, когда они сделали своё дело. Круглосуточный режим позволяет внимательно сопровождать самые чувствительные интервалы — первую ночь, утренний период после детоксикации и момент возвращения к бытовой активности.
Получить дополнительную информацию - наркологическая клиника вывод из запоя в ростове-на-дону
daily power picks – Selection seems uplifting, site layout feels clean and easy.
заказать качественную курсовую заказать качественную курсовую .
inspiring growth shop – Selection appears useful, browsing is fast and intuitive.
Iron Root Market – Impressive corner store offerings, browsing is smooth and natural.
inner power hub – Selection looks encouraging, navigating the site feels fast and natural.
Первая задача при выезде — быстро отделить угрозы от симптомов, которые можно безопасно стабилизировать на дому. Таблица ниже иллюстрирует, как стартовые наблюдения превращаются в проверяемые гипотезы, конкретные действия и решения в «окнах оценки». Она не заменяет очной диагностики, а объясняет архитектуру первых часов, чтобы у семьи был ясный ориентир.
Получить дополнительную информацию - врач нарколог на дом краснодар
FreshFashion Lane – Well-structured sections and appealing product displays create a seamless flow.
diamondfield store link – Product range looks good, and browsing feels clean and smooth.
Для сохранения приватности мы ведём коммуникацию через одного доверенного представителя, используем нейтральные формулировки в документах, а инструкции выдаём в неброском виде. При невозможности создать тишину дома (ремонт, маленькие дети, гости) предложим краткий «тихий» стационар с отдельным входом и камерным режимом, после чего сопровождение вернётся в домашний формат.
Детальнее - http://vyvod-iz-zapoya-v-ekaterinburge16.ru/vyvod-iz-zapoya-v-staczionare-ekaterinburg/
Первая задача при выезде — быстро отделить угрозы от симптомов, которые можно безопасно стабилизировать на дому. Таблица ниже иллюстрирует, как стартовые наблюдения превращаются в проверяемые гипотезы, конкретные действия и решения в «окнах оценки». Она не заменяет очной диагностики, а объясняет архитектуру первых часов, чтобы у семьи был ясный ориентир.
Узнать больше - https://narkolog-na-dom-v-krasnodare16.ru/
DFH online – Plenty of useful items here, and the platform feels quite trustworthy.
«НеоТрезвие СПБ» работает в парадигме доказательной наркологии. Мы используем медикаментозные и психотерапевтические подходы, а также их комбинации. Выбор зависит от клинического запроса, сопутствующих диагнозов и предпочтений пациента. Ниже — сравнительная таблица, которая отражает практический смысл каждого направления.
Подробнее можно узнать тут - [url=https://kodirovanie-ot-alkogolizma-v-spb16.ru/]кодирование от алкоголизма отзывы[/url]
заказать курсовую заказать курсовую .
курсовая работа недорого курсовая работа недорого .
где можно заказать курсовую работу http://kupit-kursovuyu-21.ru/ .
Мы не ограничиваемся капельницей. Сервис включает организационные, клинические и поведенческие элементы, которые уменьшают хаос и ускоряют восстановление. Ниже — ключевые блоки, которые пациенты отмечают в отзывах как наиболее полезные и «приземлённые».
Изучить вопрос глубже - нарколог на дом круглосуточно самара
Вызов нарколога на дом — это не «капельница как панацея», а управляемая последовательность решений с ясными целями, измеримыми маркерами и понятными «окнами оценки». В «СамарМед Ассист» мы строим лечение из узких модулей: сначала проверяем базовую безопасность (дыхание, сознание, гемодинамика), затем возвращаем переносимость питья, стабилизируем вегетатику, собираем ночь, и только после этого занимаемся дневной выносливостью и бытовой устойчивостью. Такой ритм исключает полипрагмазию, снижает фармаконагрузку и превращает первые часы из хаотичной «борьбы с симптомами» в спокойный, предсказуемый маршрут. Семья получает роль партнёра, а не наблюдателя: по простым ориентирам понятно, что считать нормой, когда звонить врачу и на каком этапе модуль следует «выключить».
Изучить вопрос глубже - https://narkolog-na-dom-v-samare16.ru/vyvod-iz-zapoya-samara-narkolog-na-dom
Каждый профиль решает одну задачу и имеет ожидаемую динамику. Мы избегаем параллельных «усилений», чтобы не «замазывать» вклад отдельного шага и не перегружать организм.
Получить дополнительные сведения - [url=https://narkologicheskaya-pomoshh-v-kazani16.ru/]круглосуточная наркологическая помощь[/url]
заказать качественную курсовую kupit-kursovuyu-23.ru .
Для жителей Ростова-на-Дону клиника работает по схеме «тихих маршрутов»: отдельный вход с нейтральной табличкой, окна записи в невызывающие подозрений часы, немаркированный подъезд автомобиля при выездном визите. На первом звонке диспетчер собирает только то, что влияет на безопасность: эпизоды рвоты, ЧСС/АД, ночные панические эпизоды, сопутствующие препараты, аллергии, наличие хронических заболеваний сердца. Личные и социальные детали не запрашиваются — мы придерживаемся принципа «минимально необходимой информации». По прибытии врача фиксируются базовая линия (сознание, дыхание, SpO?, температура), шкалы симптомов и переносимость небольших объёмов воды. Дальше — один точный шаг, одно «окно проверки» и прозрачное решение: продолжать модуль, модифицировать одну переменную или выключить блок.
Исследовать вопрос подробнее - анонимная наркологическая клиника
В мегаполисе привычный ритм часто мешает системному лечению: плотный график, транспортные задержки, высокая социальная видимость. Чтобы терапия проходила спокойно, «НеоТрезвие СПБ» использует «немаркированную» логистику: нейтральные формулировки в документах, аккуратные визиты, разнесенные по времени консультации специалистов и персональный координатор. По желанию пациента часть этапов — образовательные сессии и посткодовое сопровождение — выполняются онлайн. Это снижает тревогу и делает маршрут лечения менее заметным для окружения.
Исследовать вопрос подробнее - [url=https://kodirovanie-ot-alkogolizma-v-spb16.ru/]как происходит кодирование от алкоголизма[/url]
Мы не составляем «супер-смеси» «на всякий случай». Капельница — это набор модулей, каждый из которых отвечает за конкретную задачу: гидратация, электролиты, гастропротекция, антиоксидантная поддержка; при показаниях — мягкая анксиолитика. Порядок модулей зависит от ведущего симптом-кластера и времени суток.
Исследовать вопрос подробнее - http://kapelnicza-ot-zapoya-murmansk15.ru
FashionTrendSpot – Attractive interface, well-organized pages, and effortless browsing.
помощь студентам и школьникам https://kupit-kursovuyu-21.ru .
Онлайн авто https://autoindustriya.com.ua портал: всё об автомобилях и автожизни. Обзоры и сравнения моделей, тест-драйвы, лайфхаки по ремонту и обслуживанию, информация о кредитах и лизинге, новости рынка. Помогаем выбрать машину, понять тонкости владения и сэкономить на содержании.
Женский портал https://womanblog.com.ua с актуальными темами: тренды моды и макияжа, здоровье, фитнес, питание, саморазвитие и вдохновляющие истории. Ежедневные обновления, рекомендации специалистов и подборки идей для повседневной жизни, карьеры и личного счастья.
Современный женский https://womanstyle.com.ua портал для тех, кто хочет успевать всё: стиль и красота, психология и отношения, материнство, дом, путешествия и работа. Практичные лайфхаки, чек-листы, подборки и мотивационные материалы, которые помогают заботиться о себе и жить в балансе.
Современный новостной https://arguments.com.ua портал: главные новости дня, поясняющая аналитика, мнения экспертов и репортажи с мест событий. Лента в реальном времени, тематические рубрики, фото и видео. Помогаем разобраться в том, что происходит в стране и мире.
TrendyHubOnline – Clean pages, smooth layout, and effortless shopping experience.
покупка курсовых работ www.kupit-kursovuyu-23.ru .
Онлайн авто https://autoindustriya.com.ua портал: всё об автомобилях и автожизни. Обзоры и сравнения моделей, тест-драйвы, лайфхаки по ремонту и обслуживанию, информация о кредитах и лизинге, новости рынка. Помогаем выбрать машину, понять тонкости владения и сэкономить на содержании.
Soft Willow Boutique Online – Loved the calming tone and neat arrangement of products.
Особенность петербургского контекста — большая доля интеллектуального труда и проектной занятости. Мы учитываем это при выборе методики: отдаем предпочтение схемам, которые не «глушат» когнитивную активность и позволяют быстро возвращаться к задачам. Если требуются краткие больничные листы, предоставляем корректные медицинские документы без «ярлыков».
Узнать больше - http://kodirovanie-ot-alkogolizma-v-spb16.ru
Женский портал https://womanblog.com.ua с актуальными темами: тренды моды и макияжа, здоровье, фитнес, питание, саморазвитие и вдохновляющие истории. Ежедневные обновления, рекомендации специалистов и подборки идей для повседневной жизни, карьеры и личного счастья.
Современный женский https://womanstyle.com.ua портал для тех, кто хочет успевать всё: стиль и красота, психология и отношения, материнство, дом, путешествия и работа. Практичные лайфхаки, чек-листы, подборки и мотивационные материалы, которые помогают заботиться о себе и жить в балансе.
Современный новостной https://arguments.com.ua портал: главные новости дня, поясняющая аналитика, мнения экспертов и репортажи с мест событий. Лента в реальном времени, тематические рубрики, фото и видео. Помогаем разобраться в том, что происходит в стране и мире.
Today’s Outlet Picks – Products look well-curated, and browsing is comfortable and quick.
Soft Willow Studio Online – Each product feels unique and thoughtfully presented, very calming.
Daily Finds Outlet – Many items stand out here, and checking through them is quick and simple.
покупка курсовых работ покупка курсовых работ .
Такая последовательность обеспечивает медицинскую точность и безопасность процедуры, позволяя добиться быстрого улучшения самочувствия без необходимости госпитализации.
Разобраться лучше - [url=https://narkolog-na-dom-v-chelyabinske16.ru/]выезд нарколога на дом в челябинске[/url]
Happy Budget Finds – The site feels organized, with responsive pages and appealing items.
Поэтапная структура терапии делает лечение контролируемым и прогнозируемым, минимизируя риски возникновения осложнений и повторных обострений зависимости.
Исследовать вопрос подробнее - наркологическая клиника вывод из запоя
курсовая работа на заказ цена курсовая работа на заказ цена .
https://mebel-24.blogspot.com/2025/12/2025.html?m=1
Smart Value Store – Neatly arranged products with quick page transitions and a tidy feel.
купить курсовую https://www.kupit-kursovuyu-27.ru .
GrabSavings – Smooth scrolling and well-presented deals make browsing fun.
заказать курсовую работу качественно http://www.kupit-kursovuyu-22.ru .
DiscountCentral – Very smooth browsing, and deals were easy to spot.
курсовые под заказ курсовые под заказ .
помощь студентам курсовые помощь студентам курсовые .
SunColor Hub Online – Pleasant browsing, bright items displayed clearly, interface intuitive.
Такой комплексный подход позволяет не только купировать острые состояния, но и устранить внутренние факторы, провоцирующие развитие зависимости. После стабилизации состояния пациент переходит к этапу психотерапевтической коррекции, направленной на предотвращение рецидивов.
Получить дополнительные сведения - [url=https://narkologicheskaya-klinika-v-ekb16.ru/]наркологическая клиника лечение алкоголизма в екатеринбурге[/url]
Авто портал https://automotive-news.com.ua для тех, кто живёт автомобилями: новости автопрома, обзоры машин, тест-драйвы, советы по выбору и обслуживанию, сравнение моделей и подбор авто по параметрам. Фото, видео, мнения экспертов и реальные отзывы владельцев в одном месте.
Чтобы сделать процесс понятным и управляемым, каждый шаг сопровождается измеримыми маркерами безопасности и эффективности. Корректировки — точечные, по правилу «одного изменения», что позволяет видеть вклад каждого действия и сохранять переносимость.
Получить дополнительные сведения - [url=https://narkologicheskaya-pomoshh-v-kazani16.ru/]наркологическая психиатрическая помощь[/url]
Строительный портал https://garden-story.com для профессионалов и частных мастеров: статьи и инструкции по ремонту, отделке и строительству, обзоры материалов и инструментов, калькуляторы, сметы, фото-примеры и советы экспертов. Всё, чтобы грамотно спланировать и выполнить работы.
Портал о ремонте https://remont-sam.com и строительстве: от подготовки проекта и сметы до отделки и декора. Подробные инструкции, обзоры инструментов, рейтинги материалов, фото-примеры и лайфхаки. Удобная навигация по темам помогает быстро найти нужное решение для вашего объекта.
SunColor Emporium Online – Colorful products displayed neatly, navigation easy, overall experience enjoyable.
выполнение курсовых www.kupit-kursovuyu-22.ru .
официальный сайт дайсон в москве интернет магазин www.fen-d-3.ru .
Авто портал https://automotive-news.com.ua для тех, кто живёт автомобилями: новости автопрома, обзоры машин, тест-драйвы, советы по выбору и обслуживанию, сравнение моделей и подбор авто по параметрам. Фото, видео, мнения экспертов и реальные отзывы владельцев в одном месте.
Строительный портал https://garden-story.com для профессионалов и частных мастеров: статьи и инструкции по ремонту, отделке и строительству, обзоры материалов и инструментов, калькуляторы, сметы, фото-примеры и советы экспертов. Всё, чтобы грамотно спланировать и выполнить работы.
Портал о ремонте https://remont-sam.com и строительстве: от подготовки проекта и сметы до отделки и декора. Подробные инструкции, обзоры инструментов, рейтинги материалов, фото-примеры и лайфхаки. Удобная навигация по темам помогает быстро найти нужное решение для вашего объекта.
помощь студентам курсовые помощь студентам курсовые .
ai chat porn ai chat porn .
дайсон стайлер для волос с насадками официальный сайт купить цена www.fen-d-3.ru .
Для сохранения приватности мы ведём коммуникацию через одного доверенного представителя, используем нейтральные формулировки в документах, а инструкции выдаём в неброском виде. При невозможности создать тишину дома (ремонт, маленькие дети, гости) предложим краткий «тихий» стационар с отдельным входом и камерным режимом, после чего сопровождение вернётся в домашний формат.
Подробнее тут - [url=https://vyvod-iz-zapoya-v-ekaterinburge16.ru/]вывод из запоя круглосуточно[/url]
«Опора Здоровья» организует выезд нарколога на дом по Воскресенску и району круглосуточно. Мы действуем анонимно и по клиническим протоколам: очная оценка состояния, допуск к инфузии, детокс с коррекцией водно-электролитного баланса, поддержка печени и центральной нервной системы, бережная нормализация сна по показаниям. Врач объясняет решения простым языком, согласует темп и состав капельницы, оставляет памятку на 24–48 часов и остаётся на связи. Если риски высоки, предложим перевод в стационар без задержек — безопасность всегда важнее «тишей» дома.
Получить больше информации - http://narkolog-na-dom-voskresensk8.ru/psihiatr-narkolog-na-dom-v-voskresenske/
free live sex cams free live sex cams .
FashionWorld Online Hub – Pages opened instantly, and the modern styling made it enjoyable to explore.
Процесс терапии включает несколько последовательных шагов:
Получить дополнительные сведения - [url=https://narcologicheskaya-klinika-v-chelyabinske16.ru/]анонимная наркологическая клиника в челябинске[/url]
your journey picks – Items look attractive, site navigation is intuitive and smooth.
Majestic Grover Selection – Well-laid-out Grover products, exploring is easy and enjoyable.
fashion find store – Products look modern and attractive, site loads fast and cleanly.
Modern Styles World – Loved the sleek layout and fast loading across all sections.
Wild Rose Creative – Charming boutique layout, browsing revealed some unique finds.
your inspiration corner – Products feel uplifting, site layout makes browsing easy.
написание курсовой работы на заказ цена https://www.kupit-kursovuyu-24.ru .
Majestic Grover Hub – Unique items arranged well, navigating the store is simple and pleasant.
top fashion finds – Items are well organized, site layout feels simple and pleasant.
Wild Rose Collection Online – Lovely atmosphere with a few delightful discoveries along the way.
выполнение курсовых выполнение курсовых .
Soft Willow Finds Online – Browsing felt smooth and the curated pieces stand out beautifully.
помощь студентам контрольные kupit-kursovuyu-25.ru .
SoftWillow Online Shop – Smooth browsing and gentle design make exploring a pleasure.
Поэтапный подход помогает достичь устойчивых результатов и минимизировать вероятность рецидива, обеспечивая безопасность пациента на всех стадиях лечения.
Подробнее можно узнать тут - https://narkologicheskaya-clinika-v-samare16.ru/narkolog-i-psikhiatr-samara/
где можно заказать курсовую www.kupit-kursovuyu-24.ru .
помощь в написании курсовой https://kupit-kursovuyu-26.ru/ .
Fresh Trend Select – Cleanly arranged items and fast navigation ensure effortless shopping.
курсовой проект цена http://www.kupit-kursovuyu-25.ru .
FreshTrend Lane – Clearly presented trendy items with smooth browsing make the site user-friendly.
grove marketplace – Overall, the place has a calm design, making the search for products enjoyable.
PureGiftZone – Simple design, smooth navigation, and wide gift variety.
dreamgrovehub online – The site gives a soft, inviting impression and makes checking items quite simple.
GiftCollectionOnline – Pleasant layout, simple navigation, and clear product display.
где можно купить курсовую работу http://www.kupit-kursovuyu-21.ru .
Для жителей Ростова-на-Дону и агломерации выстроены два параллельных «тихих» маршрута: выездная бригада без маркировки и амбулаторный вход с отдельной дверью и согласованными временными слотами. На первичном звонке диспетчер уточняет только факторы безопасности: эпизоды рвоты, частоту мочеиспусканий, выраженность тремора, показатели ЧСС/АД, наличие ночных панических эпизодов, текущие препараты и аллергии. На месте врач фиксирует базовую линию (уровень сознания, дыхание, сатурация, температура), использует шкалы симптомов 0–10 и определяет минимальный стартовый модуль. По результатам «окон оценки» (40–90 минут для питья и тошноты; 60–120 минут для ЧСС/АД; первая ночь для сна) мы либо выключаем модуль, либо адресно меняем одну переменную — так сохраняется причинно-следственная связь и исключается «инерция лечения».
Ознакомиться с деталями - наркологическая клиника
Trend Collection Daily – A curated mix of styles is shown, and the pages load without delay.
Everyday Trend Hub – Trendy picks look great today, and the browsing experience feels very smooth.
сколько стоит заказать курсовую работу www.kupit-kursovuyu-23.ru .
куплю курсовую работу http://kupit-kursovuyu-21.ru/ .
ThreeForest Deals – Clean layout, products easy to explore, browsing is comfortable.
Этапы терапии выглядят следующим образом:
Углубиться в тему - https://narkologicheskaya-klinika-v-samare16.ru/narkologicheskij-dispanser-g-samara
ValuePicks – Enjoyable browsing with all items displayed neatly.
ThreeForest Finds Online – Comfortable browsing, products arranged well, site feels clean and natural.
CrestGlobal Hub – Clean interface with well-spaced categories ensures easy exploration.
AI Porn Chat AI Porn Chat .
куплю курсовую работу https://www.kupit-kursovuyu-23.ru .
SmartDealsNow – Clear layout with easy navigation makes browsing enjoyable.
курсовой проект цена курсовой проект цена .
CrestGlobal Select – Well-spaced sections and clean design ensure a smooth user flow.
дайсон фен купить в москве оригинал дайсон фен купить в москве оригинал .
Этапы терапии выглядят следующим образом:
Узнать больше - http://narkologicheskaya-klinika-v-samare16.ru
Hi Dear, are you in fact visiting this web site regularly, if so afterward you will definitely get nice experience.
juegos frv
free live sex cams free live sex cams .
помощь в написании курсовой работы онлайн www.kupit-kursovuyu-27.ru .
покупка курсовых работ покупка курсовых работ .
Вызов нарколога на дом — это не «капельница как панацея», а управляемая последовательность решений с ясными целями, измеримыми маркерами и понятными «окнами оценки». В «СамарМед Ассист» мы строим лечение из узких модулей: сначала проверяем базовую безопасность (дыхание, сознание, гемодинамика), затем возвращаем переносимость питья, стабилизируем вегетатику, собираем ночь, и только после этого занимаемся дневной выносливостью и бытовой устойчивостью. Такой ритм исключает полипрагмазию, снижает фармаконагрузку и превращает первые часы из хаотичной «борьбы с симптомами» в спокойный, предсказуемый маршрут. Семья получает роль партнёра, а не наблюдателя: по простым ориентирам понятно, что считать нормой, когда звонить врачу и на каком этапе модуль следует «выключить».
Получить больше информации - нарколог на дом самара
дайсон стайлер для волос купить официальный сайт с насадками цена http://www.fen-d-3.ru .
Для наглядности ниже приведена таблица с основными направлениями медикаментозной терапии и их эффектами:
Подробнее можно узнать тут - http://narkologicheskaya-klinika-v-samare16.ru/narkolog-i-psikhiatr-samara/
заказать курсовую работу заказать курсовую работу .
Состояния при зависимостях чувствительны к времени суток и среде. К ночи нарастает тревога, усиливается тремор, нестабильны показатели ЧСС/АД. Круглосуточный приём позволяет выстроить «мост» через самые сложные часы: собрать сон без избыточной фармаконагрузки, сделать короткие чек-ины, вовремя ретитровать один параметр (свет, дыхательные ритмы, интервалы питья), а утром оформить «малые победы» — гигиена и 10–15 минут тихой ходьбы. Эти простые маркеры часто надёжнее любых субъективных оценок «как себя чувствую».
Получить больше информации - http://narkologicheskaya-clinika-v-rostove-na-donu16.ru
Modern Wardrobe Hub – Items are easy to find, and pages load quickly with a clean design.
EverLeaf Trend Picks – Products are displayed clearly and browsing felt natural and intuitive.
Fashion Edge Corner – Sleek interface and well-organized products make browsing enjoyable.
LeafOutlet Storefront – Everything appears organized and clean, making browsing enjoyable.
написание курсовых на заказ написание курсовых на заказ .
Wild Rose Picks – Boutique has a lovely atmosphere, found some special items easily.
learning click corner – Items are appealing, navigating the site is smooth today.
ModernHome Select – Everything felt organized, and the site loaded quickly.
MidCity Select – Well-presented selections, exploring the store feels quick and simple.
daily home finds – Items are clearly presented, site layout feels clean and user-friendly.
Такой комплексный подход позволяет не только купировать острые состояния, но и устранить внутренние факторы, провоцирующие развитие зависимости. После стабилизации состояния пациент переходит к этапу психотерапевтической коррекции, направленной на предотвращение рецидивов.
Ознакомиться с деталями - [url=https://narkologicheskaya-klinika-v-ekb16.ru/]запой наркологическая клиника в екатеринбурге[/url]
стоимость написания курсовой работы на заказ https://kupit-kursovuyu-22.ru/ .
WildRose Treasures Online – Charming setup with some standout products, exploring was fun.
discover & learn – Products feel motivating, site loads quickly and is easy to use.
купить курсовую работу купить курсовую работу .
MidCity Collections – Attractive collections presented clearly, navigation feels smooth and quick.
ModernHome Select – Everything felt organized, and the site loaded quickly.
home essentials hub – Great selections here, everything is arranged neatly and intuitive to browse.
заказать курсовую работу качественно https://kupit-kursovuyu-24.ru .
помощь курсовые https://www.kupit-kursovuyu-26.ru .
Premium World Finds – Loved exploring, the layout is clean and the selection diverse.
заказать задание kupit-kursovuyu-22.ru .
Лечение в клинике в Челябинске строится на принципах конфиденциальности, добровольности и медицинской этики. Врачи применяют доказательные методы терапии, а программы лечения адаптируются под особенности каждого пациента. Работа ведётся комплексно, включая медикаментозную помощь, психотерапию и социальную реабилитацию. Такой подход позволяет эффективно восстановить здоровье и вернуть пациента к нормальной жизни в обществе.
Углубиться в тему - https://narcologicheskaya-klinika-v-chelyabinske16.ru/
Global Marketplace Elite – Browsing was simple, everything feels curated and premium.
Приоритеты «ПолярМед Центра» — безопасность, устойчивость результата и приватность. Мы используем современные методы терапии, в том числе адресную инфузионную коррекцию, мягкие анксиолитические протоколы по строгим показаниям, когнитивно-поведенческие техники, а также сенсорную гигиену (работу со светом, шумом, цифровыми триггерами). В документации — нейтральные формулировки; в общении — короткие ясные фразы; в логистике — немаркированный транспорт и «беззвучные» уведомления. Прозрачность и предсказуемость снимают лишнюю тревогу и повышают приверженность плану.
Ознакомиться с деталями - [url=https://narkologicheskaya-klinika-murmansk15.ru/]частная наркологическая клиника[/url]
Этика коммуникации — отдельный протокол: врач простыми словами объясняет, какую цель мы решаем прямо сейчас (например, «вернуть переносимость воды»), какой маркер наблюдаем (тошнота, диурез, частота пульса), через какое время ожидаем эффект (20–40 минут, 60–120 минут или первая ночь) и в каком случае нужна коррекция. Прозрачность снижает тревожность и помогает семье поддерживать «ровную» среду без «караула у кровати».
Выяснить больше - http://narkologicheskaya-klinika-v-nizhnem-novgorode16.ru
заказать качественную курсовую заказать качественную курсовую .
онлайн сервис помощи студентам https://kupit-kursovuyu-24.ru/ .
Мы не «усиливаем всё сразу». Лечение собирается из модулей: гидратация, адресная коррекция электролитов, гастропротекция, антиоксидантная поддержка, при необходимости — мягкие анксиолитики по строгим показаниям. Порядок и насыщенность зависят от ведущей жалобы и времени суток. Ниже — ориентир для пациента: почему назначение выглядит именно так и в какой горизонт мы ожидаем эффект.
Выяснить больше - https://narkologicheskaya-klinika-murmansk15.ru/
курсовая заказ купить курсовая заказ купить .
Выездной формат — это не просто «капельница у кровати». Мы заранее раскладываем визит на модули и назначаем окна оценки: первые 20–40 минут (антиеметический мост, переносимость воды), 60–120 минут (регидратация и электролиты, сглаживание ЧСС/АД), первая ночь (сон ?6 часов и ?1 пробуждение), 12–24 часа (утренняя ясность и способность выполнить 2 короткие бытовые задачи). Одно изменение — один параметр: либо темп инфузии, либо порядок модулей, либо настройка среды (свет/тишина/ритуал). Так причинно-следственные связи остаются прозрачными, а результат — подтверждаемым.
Подробнее можно узнать тут - [url=https://narkologicheskaya-klinika-v-chelyabinske16.ru/]запой наркологическая клиника в челябинске[/url]
V?deo pornogr?fico gay negro V?deo pornogr?fico gay negro .
DailyShopSpot – Simple design, effortless navigation, and attractive deals throughout.
написание студенческих работ на заказ www.kupit-kursovuyu-25.ru .
DailyDealsSpot – Organized pages, quick navigation, and appealing products.
ThreeOak Deals – Clear layout, treasures easy to explore, navigation feels simple and smooth.
FashionAndDesign Styles – Beautiful fashion picks are displayed, making the shopping flow smooth.
большая задница xxx видео секс порно большая задница xxx видео секс порно .
ThreeOak Hub Online – Smooth browsing experience, treasures easy to locate, layout clean.
Вывод из запоя в клинике в Санкт-Петербурге осуществляется под круглосуточным медицинским контролем с применением современных методов инфузионной терапии, препаратов для восстановления обменных процессов и купирования синдрома отмены. Главной задачей врачей является восстановление баланса между физическим и психическим состоянием, предотвращение осложнений и стабилизация основных жизненных функций.
Получить больше информации - наркологические клиники алкоголизм в санкт-петербурге
Сразу важно проговорить: кодирование — это «замок» на поведение и физиологию, который помогает удержать ремиссию, пока человек выстраивает новые привычки и восстанавливает качество жизни. Поэтому эффект процедуры прямо зависит от того, насколько грамотно выстроены подготовка, информирование и поддержка после вмешательства. «НеоТрезвие СПБ» делает акцент на постепенности: один этап — одна цель — один прозрачный маркер успеха.
Получить дополнительную информацию - [url=https://kodirovanie-ot-alkogolizma-v-spb16.ru/]кодирование от алкоголизма отзывы цены в санкт-петербурге[/url]
StartBuilding Online – Well-laid-out pages with intuitive navigation make browsing effortless.
F&D Trend Shop – A polished variety of designs is shown, and browsing feels effortless.
evercrest link – The site feels active with steady updates, offering a dependable variety.
Build Hub Today – Clean design with easy-to-navigate sections ensures a pleasant browsing experience.
Ниже — практическая карта первых часов. Она помогает всем участникам понимать логику действий, точки контроля и критерии перехода. Если ответ «плоский», меняем один параметр и возвращаемся к оценке в назначённое время — без хаотичных «усилений».
Узнать больше - http://kapelnicza-ot-zapoya-murmansk15.ru
EverCrest Selection – Nicely curated goods here, with fresh updates that make browsing feel rewarding.
Такая карта снимает неопределённость. Пациент понимает, чего ожидать; родственники — когда и по каким метрикам судить об успехе; команда — что именно корректировать, чтобы сохранить управляемость терапии даже ночью.
Углубиться в тему - [url=https://narkologicheskaya-klinika-murmansk15.ru/]лечение в наркологической клинике в мурманске[/url]
AnswerStream – Easy-to-use interface, resources presented neatly for quick reference.
Строительный портал https://sovetremont.com с практическими советами: ремонт квартир, строительство домов, инженерные системы, отделка, фасады, кровля и благоустройство. Руководства, видео, расчёты и рекомендации экспертов, которые помогают экономить время и деньги.
Портал о строительстве https://stroyline.com и ремонте: пошаговые инструкции, обзоры материалов, калькуляторы, идеи планировок и дизайна, советы мастеров и реальные примеры. Помогаем спланировать работы, избежать типичных ошибок и сэкономить время и бюджет.
Онлайн-портал https://stroyinfo.com о строительстве и ремонте для владельцев квартир, домов и дач: полезные статьи, схемы, чек-листы, подбор материалов и техники, советы по отделке и инженерным системам. Всё, чтобы сделать ремонт своими руками или грамотно контролировать подрядчиков.
Свежие новости https://ukrportal.com.ua Украины и мира: политика, экономика, общество, происшествия, аналитика и авторские материалы. Оперативные обновления 24/7, проверенные факты и объективная подача. Следите за ключевыми событиями, которые формируют будущее страны и всего мира.
QuickAnswersNow – Clear layout makes searching for solutions very easy.
Строительный портал https://sovetremont.com с практическими советами: ремонт квартир, строительство домов, инженерные системы, отделка, фасады, кровля и благоустройство. Руководства, видео, расчёты и рекомендации экспертов, которые помогают экономить время и деньги.
Портал о строительстве https://stroyline.com и ремонте: пошаговые инструкции, обзоры материалов, калькуляторы, идеи планировок и дизайна, советы мастеров и реальные примеры. Помогаем спланировать работы, избежать типичных ошибок и сэкономить время и бюджет.
Онлайн-портал https://stroyinfo.com о строительстве и ремонте для владельцев квартир, домов и дач: полезные статьи, схемы, чек-листы, подбор материалов и техники, советы по отделке и инженерным системам. Всё, чтобы сделать ремонт своими руками или грамотно контролировать подрядчиков.
Свежие новости https://ukrportal.com.ua Украины и мира: политика, экономика, общество, происшествия, аналитика и авторские материалы. Оперативные обновления 24/7, проверенные факты и объективная подача. Следите за ключевыми событиями, которые формируют будущее страны и всего мира.
дайсон стайлер купить официальный fen-d-4.ru .
где можно заказать курсовую www.kupit-kursovuyu-21.ru/ .
RisingRiver Online Market – Easy to navigate with a wide, well-curated assortment.
студенческие работы на заказ студенческие работы на заказ .
Rising River Essentials – Each section is thoughtfully designed, making browsing enjoyable.
дайсон официальный сайт стайлер дайсон официальный сайт стайлер .
курсовая заказать курсовая заказать .
курсовые купить kupit-kursovuyu-21.ru .
написать курсовую на заказ написать курсовую на заказ .
помощь студентам и школьникам www.kupit-kursovuyu-23.ru .
срочно курсовая работа www.kupit-kursovuyu-29.ru/ .
выполнение учебных работ выполнение учебных работ .
WildRose Treasures Online – Charming setup with some standout products, exploring was fun.
написание курсовых работ на заказ цена http://kupit-kursovuyu-28.ru .
Wild Rose Hub Online – Cozy boutique vibe, found several enjoyable items while browsing.
modern collection store – Products are attractive, navigation feels smooth and effortless.
Midnight Trend Collection Hub – Stylish items displayed clearly, exploring the store is fast and pleasant.
Процесс лечения в клинике организован последовательно и направлен на восстановление всех систем организма. Каждый этап имеет свои задачи и методы, что обеспечивает максимальную эффективность терапии.
Подробнее - [url=https://narkologicheskaya-clinika-v-samare16.ru/]наркологическая клиника лечение алкоголизма самара[/url]
modern trend collection – Products are nicely displayed, navigating feels effortless.
Sunset Grove Lane – Inviting visuals and clean layout ensure a natural browsing experience.
выполнение курсовых работ выполнение курсовых работ .
TopBargainOutlet – Fantastic selection, speedy browsing, and very shopper-friendly.
Modern Styles Store – Pages opened instantly and the trendy selection was attractive.
Капельница — основной метод дезинтоксикации при запое. Она позволяет быстро восполнить дефицит жидкости и электролитов, вывести токсины и улучшить общее самочувствие. В состав инфузии входят препараты, нормализующие обмен веществ, а также витамины и гепатопротекторы. Процедура проводится под контролем врача, что гарантирует безопасность и точную дозировку лекарств.
Получить дополнительную информацию - вывод из запоя на дому в ростове-на-дону
Midnight Trend Store – Trendy selections look impressive, browsing feels effortless and natural.
курсовая работа недорого курсовая работа недорого .
QuickValueShop – Loads quickly, easy to navigate, perfect for smart shoppers.
Grove Sunset Market – Clear imagery and organized sections enhance the user experience.
Trendy Modern Finds – Clean design, smooth navigation, and stylish selections throughout.
Актуальные новости https://ukrmedia24.com.ua Украины и мира в одном месте: главные события дня, обзоры, комментарии экспертов, репортажи и эксклюзивные материалы. Политика, экономика, технологии, культура и спорт. Быстро, достоверно и удобно для ежедневного чтения.
Новости Украины https://ukrinfo24.com.ua и мира: оперативная информация, разбор ключевых событий, интервью, репортажи и аналитика. Только проверенные источники и объективная подача. Будьте в курсе того, что происходит в стране и на международной арене прямо сейчас.
Все новости https://uanews24.com.ua Украины и мира — быстро, достоверно и понятно: события в политике, экономике, науке, культуре и спорте. Подробные обзоры, интервью и аналитика помогают увидеть полную картину происходящего. Ежедневные обновления и удобная навигация.
Лента новостей https://uavesti.com.ua Украины и мира: самые важные события дня, актуальные темы, экспертные оценки и глубокая аналитика. Удобный формат, быстрые обновления, проверенные данные. Политика, общество, экономика, культура и мировые тенденции — всё на одной платформе.
honestfindshub – HonestFindsHub provides genuine items in an easy-to-use interface for smooth shopping.
мой опыт Нелепые ситуации случаются, когда логика уступает месту импровизации. Однажды мой светофор на перекрёстке решил быть не зелёным, а тем, что красно-зелёным, что привело к короткому квесту по правилам дорожного движения и смеху прохожих. В офисе принтер заупрямился и начал печатать только пустые страницы в самом циферблате, ничего не выдавая — как будто издевался над нашими отчётами. На прогулке в парке я случайно нашёл чужой зонтик, который оказался такой же яркий, что люди переходили на другую сторону улицы, думая, что это сигнал светофора для пингвинов. Нелепости напоминают: не всё в жизни должно идти строго по плану — иногда хаос делает день интереснее.
Актуальные новости https://ukrmedia24.com.ua Украины и мира в одном месте: главные события дня, обзоры, комментарии экспертов, репортажи и эксклюзивные материалы. Политика, экономика, технологии, культура и спорт. Быстро, достоверно и удобно для ежедневного чтения.
Новости Украины https://ukrinfo24.com.ua и мира: оперативная информация, разбор ключевых событий, интервью, репортажи и аналитика. Только проверенные источники и объективная подача. Будьте в курсе того, что происходит в стране и на международной арене прямо сейчас.
Premium Worldwide Market – Smooth layout and clear organization, products feel curated.
выполнение курсовых http://kupit-kursovuyu-22.ru/ .
Все новости https://uanews24.com.ua Украины и мира — быстро, достоверно и понятно: события в политике, экономике, науке, культуре и спорте. Подробные обзоры, интервью и аналитика помогают увидеть полную картину происходящего. Ежедневные обновления и удобная навигация.
Лента новостей https://uavesti.com.ua Украины и мира: самые важные события дня, актуальные темы, экспертные оценки и глубокая аналитика. Удобный формат, быстрые обновления, проверенные данные. Политика, общество, экономика, культура и мировые тенденции — всё на одной платформе.
simplelivinghub – SimpleLivingHub presents thoughtfully chosen products that make browsing effortless.
Global Marketplace Elite – Browsing was simple, everything feels curated and premium.
TimberField Emporium Online – Comfortable browsing, tidy layout, rustic items displayed clearly and appealingly.
Fashion Style Hub – The site is responsive, and the modern picks are displayed elegantly.
TimberFieldCorner Hub – Smooth browsing, rustic items displayed neatly, layout feels organized.
Fashion Trend Hub – Modern picks feel fresh, and the browsing experience is seamless.
SuccessPath – Friendly interface, organized content, and simple browsing.
стайлер дайсон официальный сайт стайлер дайсон официальный сайт .
FocusForward – Streamlined layout, simple interactions, and pleasant browsing.
Поэтапный подход помогает достичь устойчивых результатов и минимизировать вероятность рецидива, обеспечивая безопасность пациента на всех стадиях лечения.
Подробнее можно узнать тут - [url=https://narkologicheskaya-clinika-v-samare16.ru/]вывод наркологическая клиника[/url]
Fashion & Choice Hub – Beautiful items stand out, and the website navigation is very clear.
SunsetCrest Studio – The boutique feels welcoming and the items are thoughtfully arranged.
обзор казино Ищете лучшие казино? Мы собрали для вас топ! Если вы в поисках проверенных и надежных онлайн-казино, где можно насладиться азартом и выиграть по-крупному, то вы попали по адресу. Мы подготовили для вас актуальный список лучших казино, которые зарекомендовали себя высоким качеством игр, щедрыми бонусами и безупречной репутацией. Откройте для себя мир захватывающих слотов, классических настольных игр и живого дилера – все это в самых топовых заведениях!
SunsetCrest Treasures – Cozy feel throughout and thoughtfully selected items.
FashionDesign Choice – Stylish pieces are well-curated, and site navigation is intuitive and smooth.
дайсон официальный сайт фен цена http://fen-d-4.ru/ .
rejestracja w mostbet mostbet pl
Сайт для женщин https://golosiyiv.kiev.ua которые ценят себя и своё время: полезные статьи о моде и уходе, психологии, детях, отношениях, работе и хобби. Подборки идей, гайды, чек-листы и вдохновляющие истории. Помогаем находить баланс между заботой о других и заботой о себе.
Сайт для женщин https://e-times.com.ua о жизни, красоте и вдохновении: мода, макияж, уход за собой, здоровье, отношения, семья и карьера. Практичные советы, обзоры, чек-листы и личные истории. Помогаем заботиться о себе, развиваться и находить новые идеи каждый день.
Онлайн женский https://womenclub.kr.ua портал для девушек и женщин любого возраста: статьи про красоту и уход, отношения, семью, детей, карьеру и хобби. Удобная навигация по разделам, полезные советы, тесты и подборки, которые помогают находить ответы на важные вопросы.
Онлайн-сайт https://funtura.com.ua для женщин любого возраста: тренды моды и макияжа, здоровый образ жизни, питание, фитнес, отношения и саморазвитие. Регулярные обновления, советы экспертов и вдохновляющие материалы, которые помогают чувствовать себя увереннее каждый день.
DirectionFinder – Well-presented posts and fast-loading pages make reading easy.
Сайт для женщин https://golosiyiv.kiev.ua которые ценят себя и своё время: полезные статьи о моде и уходе, психологии, детях, отношениях, работе и хобби. Подборки идей, гайды, чек-листы и вдохновляющие истории. Помогаем находить баланс между заботой о других и заботой о себе.
Онлайн женский https://womenclub.kr.ua портал для девушек и женщин любого возраста: статьи про красоту и уход, отношения, семью, детей, карьеру и хобби. Удобная навигация по разделам, полезные советы, тесты и подборки, которые помогают находить ответы на важные вопросы.
Сайт для женщин https://e-times.com.ua о жизни, красоте и вдохновении: мода, макияж, уход за собой, здоровье, отношения, семья и карьера. Практичные советы, обзоры, чек-листы и личные истории. Помогаем заботиться о себе, развиваться и находить новые идеи каждый день.
Онлайн-сайт https://funtura.com.ua для женщин любого возраста: тренды моды и макияжа, здоровый образ жизни, питание, фитнес, отношения и саморазвитие. Регулярные обновления, советы экспертов и вдохновляющие материалы, которые помогают чувствовать себя увереннее каждый день.
FocusFinder – Smooth browsing experience and content is clearly structured.
Evergreen Find Hub – A tidy and clear layout makes it easy to explore evergreen options.
Trendy Lane Hub – Well-laid-out product sections and smooth navigation provide a pleasant experience.
Evergreen Choice Storefront – Items appear neatly, and browsing flows naturally from section to section.
Trendy Finds Store – Stylish items displayed clearly, pages load fast, and navigation is intuitive.
Вывод из запоя у подростков в Люберцах. Мы предлагаем специализированное лечение для подростков, учитывая их возрастные особенности.
Детальнее - [url=https://https://kapelnica-ot-zapoya-lyubercy11.ru//]vyzvat-kapelniczu-ot-zapoya lyubercy[/url]
top favorites shop – Favorites are arranged clearly, making the experience easy and enjoyable.
daily favorite picks – Daily selections look appealing, and the site operates with great ease.
Wild Rose Hub Online – Cozy boutique vibe, found several enjoyable items while browsing.
Мы дозировано упоминаем географию — важнее не слово «Нижний Новгород», а предсказуемость процесса. Пациент получает «вечерний протокол» — краткие инструкции на ближайшие 12 часов: как пить воду малыми порциями, как приглушить свет, какое «окно тишины» соблюсти перед сном, когда связаться с дежурным врачом и какие маркеры фиксировать в «дневнике симптомов» (шкалы тремора, тревоги, тошноты по 0–10; время засыпания; число пробуждений).
Подробнее можно узнать тут - https://narkologicheskaya-klinika-v-nizhnem-novgorode16.ru/
Журнал о животных https://zoo-park.com дикая природа и домашние питомцы. Познавательные материалы, фотоистории, редкие виды, повадки, экология и ответственное содержание. Понятные гайды по уходу, выбору питомца и безопасному общению с животными.
Журнал о животных https://myzoofriend.com советы по уходу за питомцами, здоровье, питание, воспитание и поведение. Обзоры кормов и аксессуаров, рекомендации ветеринаров, истории спасения и интересные факты о кошках, собаках и дикой природе.
Wild Rose Boutique – Charming layout throughout, found some unique and enjoyable pieces.
Авто портал https://just-forum.com с полным набором разделов: новости, обзоры, тесты, подержанные авто, советы по покупке, эксплуатации и продаже автомобиля. Честные мнения экспертов, реальные отзывы, подборки лучших моделей и удобная навигация по маркам и классам.
Новостной портал https://infonews.com.ua с полным охватом событий: оперативная лента, большие тексты, интервью и аналитика. Политика, экономика, общество, технологии, культура и спорт. Обновления в режиме реального времени и удобная структура разделов для ежедневного чтения.
Для наглядности представлена таблица с основными направлениями терапии и их эффектами:
Разобраться лучше - наркологическая клиника стационар
где можно заказать курсовую где можно заказать курсовую .
Журнал о животных https://zoo-park.com дикая природа и домашние питомцы. Познавательные материалы, фотоистории, редкие виды, повадки, экология и ответственное содержание. Понятные гайды по уходу, выбору питомца и безопасному общению с животными.
Журнал о животных https://myzoofriend.com советы по уходу за питомцами, здоровье, питание, воспитание и поведение. Обзоры кормов и аксессуаров, рекомендации ветеринаров, истории спасения и интересные факты о кошках, собаках и дикой природе.
Новостной портал https://infonews.com.ua с полным охватом событий: оперативная лента, большие тексты, интервью и аналитика. Политика, экономика, общество, технологии, культура и спорт. Обновления в режиме реального времени и удобная структура разделов для ежедневного чтения.
Авто портал https://just-forum.com с полным набором разделов: новости, обзоры, тесты, подержанные авто, советы по покупке, эксплуатации и продаже автомобиля. Честные мнения экспертов, реальные отзывы, подборки лучших моделей и удобная навигация по маркам и классам.
MidRiver Finds – Attractive products showcased neatly, navigation feels effortless.
выполнение курсовых выполнение курсовых .
TrendSpotHub – Quick navigation, attractive fashion pieces, and easy-to-find collections.
MidRiver Outlet – Items displayed nicely, site navigation is quick and convenient.
Timeless Groove Collections – Easy navigation, items well-presented, interface feels tidy and fun.
The Trendy Shop – Fast site speed paired with a great variety of stylish products.
StyleHavenClick – Simple and fast browsing, fashionable items displayed neatly.
Весь процесс можно представить следующим образом:
Получить больше информации - [url=https://narkolog-na-dom-v-chelyabinske16.ru/]нарколог на дом вывод[/url]
Timeless Groove Treasures – Navigation simple, browsing smooth, creative items arranged nicely.
официальный магазин дайсон официальный магазин дайсон .
Shop Trendy Finds – The site ran fast and the product lineup looked really appealing.
Design Conscious Market – Loved the curated selection, browsing was smooth and enjoyable throughout.
Conscious Finds Hub – Clean and organized layout with thoughtfully curated items.
BrightNorth Style Shop – The layout feels organized and refreshing, enjoyable to scroll around.
стайлер дайсон купить в спб стайлер дайсон купить в спб .
BrightNorth Fashion House – A tidy, stylish setup that makes finding items simple and enjoyable.
Наркологическая клиника «ПолярМед Центр» — это пространство круглосуточной помощи, где медицинская точность сочетается с бережным сервисом и конфиденциальными процедурами. Мы строим терапию как последовательность проверяемых шагов: ставим понятную цель, выбираем подходящий инструмент, заранее определяем маркеры контроля и фиксируем время повторной оценки. Такая дисциплина исключает «универсальные сильные капельницы» и заменяет их модульными решениями с предсказуемым эффектом. Пациент и его близкие на каждом этапе понимают, почему именно такое назначение выбрано сейчас и в какой момент мы ожидаем улучшение самочувствия.
Получить дополнительные сведения - [url=https://narkologicheskaya-klinika-murmansk15.ru/]частная наркологическая клиника мурманск[/url]
стоимость написания курсовой работы на заказ www.kupit-kursovuyu-22.ru/ .
Портал о даче https://sovetyogorod.com саде и огороде: статьи и гайды по уходу за почвой, посадке, обрезке, мульчированию и борьбе с болезнями растений. Обзоры инструментов, идеи для теплиц и компостеров, ландшафтные решения и полезные советы для урожая.
Женский портал https://dreamywoman.com о стиле жизни: красота и уход, мода, здоровье, психология, отношения, семья и карьера. Полезные статьи, подборки, чек-листы и вдохновляющие истории. Всё, чтобы заботиться о себе, развиваться и находить идеи на каждый день.
Новостной портал https://ua24news.com.ua Украины: оперативные события дня, политика, экономика, общество, происшествия и международная повестка. Проверенные факты, аналитика, интервью и репортажи. Узнавайте главное о жизни страны и мира в удобном формате 24/7.
Современный женский https://nova-woman.com сайт для девушек и женщин: тренды моды и макияжа, питание, фитнес, эмоциональное здоровье, отношения и саморазвитие. Понятные советы, обзоры, тесты и подборки, которые помогают чувствовать себя увереннее и счастливее.
EcoTreasureSpot – Pleasant interface, smooth flow, and eco-conscious product variety.
Портал о даче https://sovetyogorod.com саде и огороде: статьи и гайды по уходу за почвой, посадке, обрезке, мульчированию и борьбе с болезнями растений. Обзоры инструментов, идеи для теплиц и компостеров, ландшафтные решения и полезные советы для урожая.
Женский портал https://dreamywoman.com о стиле жизни: красота и уход, мода, здоровье, психология, отношения, семья и карьера. Полезные статьи, подборки, чек-листы и вдохновляющие истории. Всё, чтобы заботиться о себе, развиваться и находить идеи на каждый день.
Кодирование от алкоголизма — это не «волшебная таблетка», а четко структурированный этап комплексного лечения, который должен вписываться в общий терапевтический план: диагностика, стабилизация состояния, выбор методики, юридически корректное информированное согласие, сопровождение и профилактика рецидивов. В наркологической клинике «НеоТрезвие СПБ» приоритет — безопасность, предсказуемость и конфиденциальность. Мы не перебираем методы «на удачу», а подбираем технологию с учетом клинического профиля, мотивации, социализации и коморбидных факторов (тревога, депрессия, соматические заболевания).
Получить больше информации - [url=https://kodirovanie-ot-alkogolizma-v-spb16.ru/]анонимное кодирование от алкоголизма[/url]
Новостной портал https://ua24news.com.ua Украины: оперативные события дня, политика, экономика, общество, происшествия и международная повестка. Проверенные факты, аналитика, интервью и репортажи. Узнавайте главное о жизни страны и мира в удобном формате 24/7.
Современный женский https://nova-woman.com сайт для девушек и женщин: тренды моды и макияжа, питание, фитнес, эмоциональное здоровье, отношения и саморазвитие. Понятные советы, обзоры, тесты и подборки, которые помогают чувствовать себя увереннее и счастливее.
EarthChoiceStore – Well-laid-out pages, inviting design, and natural-feeling navigation.
заказать курсовую https://www.kupit-kursovuyu-22.ru .
GoldenStore Lane – Well-organized categories and tidy pages make exploring products smooth.
LifeCompass – Site layout is intuitive and discovering inspiring content is quick.
Golden Field Hub – Clean, tidy layout with clearly organized products that make browsing effortless.
LifeDirectionNow – Intuitive navigation and inspiring posts make browsing enjoyable.
Trendy Market Spot – Stylish items stand out, and the layout makes browsing smooth and enjoyable.
Trendy Market Spot – Stylish items stand out, and the layout makes browsing smooth and enjoyable.
Эта схема помогает постепенно вывести пациента из кризисного состояния, снизить риски осложнений и закрепить результаты лечения.
Углубиться в тему - https://narkologicheskaya-klinika-v-krasnodare16.ru/gosudarstvennaya-narkologicheskaya-klinika-krasnodar
mostbet dzisiaj mostbet pl
オアンダ証券
Главные новости https://smi24.com.ua Украины в одном месте: актуальные события, мнения аналитиков, расследования, репортажи и эксклюзивные материалы. Наш новостной портал помогает понимать, что происходит в стране и как события влияют на жизнь людей.
Онлайн-новостной https://novosti24online.com.ua портал Украины: лента новостей, авторские колонки, интервью, обзоры и аналитика. Политика, социальные вопросы, экономика, международные события — всё оперативно, достоверно и понятно каждому читателю.
Новости Украины https://mediaportal.com.ua в удобном формате: лента последних событий, разделы по темам, авторские колонки и аналитика. Освещаем политику, экономику, безопасность, социальные вопросы и международные отношения. Портал для тех, кто хочет получать полную картину дня.
Новостной портал https://mediasfera.com.ua Украины для тех, кто хочет быть в курсе: свежие публикации, разбор ключевых событий, экспертные оценки и подробные материалы о политике, экономике и обществе. Быстрые обновления, удобная навигация и проверенная информация.
Everline Collection – Nicely curated items, making browsing feel smooth and straightforward.
Главные новости https://smi24.com.ua Украины в одном месте: актуальные события, мнения аналитиков, расследования, репортажи и эксклюзивные материалы. Наш новостной портал помогает понимать, что происходит в стране и как события влияют на жизнь людей.
Онлайн-новостной https://novosti24online.com.ua портал Украины: лента новостей, авторские колонки, интервью, обзоры и аналитика. Политика, социальные вопросы, экономика, международные события — всё оперативно, достоверно и понятно каждому читателю.
Everline Online Hub – Nicely categorized products, making it easy to find exactly what you want.
Новости Украины https://mediaportal.com.ua в удобном формате: лента последних событий, разделы по темам, авторские колонки и аналитика. Освещаем политику, экономику, безопасность, социальные вопросы и международные отношения. Портал для тех, кто хочет получать полную картину дня.
Новостной портал https://mediasfera.com.ua Украины для тех, кто хочет быть в курсе: свежие публикации, разбор ключевых событий, экспертные оценки и подробные материалы о политике, экономике и обществе. Быстрые обновления, удобная навигация и проверенная информация.
your gift gallery – The gallery of gift items looks polished, and navigation feels very smooth.
WildWood Studio Lane – Modern layout, neatly displayed products, and effortless browsing throughout.
Наркологическая клиника в клинике в Казани — это современный медицинский центр, специализирующийся на лечении алкогольной и наркотической зависимости. Основное направление деятельности заключается в проведении детоксикации, восстановлении работы нервной системы и формировании устойчивой мотивации к отказу от употребления психоактивных веществ. Все процедуры проводятся в условиях полной анонимности и медицинского контроля, что обеспечивает безопасность и доверие со стороны пациентов. Программа терапии строится по принципам доказательной медицины и индивидуального подбора лечебных средств.
Разобраться лучше - [url=https://narkologicheskaya-clinika-v-kazani16.ru/]наркологическая клиника казань[/url]
Лечение проводится поэтапно, начиная с оценки состояния и заканчивая восстановлением после интоксикации. Каждый этап направлен на устранение симптомов отравления и стабилизацию работы внутренних органов.
Выяснить больше - https://narkolog-na-dom-v-chelyabinske16.ru/narkolog-chelyabinsk-sovetskij-rajon/
superslots club casino Жаждете острых ощущений и адреналина? Игровые автоматы – это то, что вам нужно! Почувствуйте азарт, когда барабаны вращаются, и надейтесь на удачную комбинацию. Каждый спин – это новая возможность испытать свою фортуну. Играйте и пусть вам повезет!
yourgiftcorner.shop – Thoughtful gift picks are displayed clearly, and browsing feels pleasantly simple.
WildWood Online – Smooth navigation with well-arranged fashion products and fast-loading pages.
купить дайсон стайлер для волос официальный сайт цена с насадками https://fen-d-4.ru/ .
Качество — это не субъективные впечатления, а сравнение базовой линии с целевыми коридорами в обозначенных окнах. Мы ведём короткий отчёт по маркерам: переносимость воды (мл/ч), диурез, ЧСС/АД в покое, структура сна (длительность и число пробуждений), динамика по шкалам тошноты/тремора, выполнение двух утренних бытовых задач. Отчёт понятен пациенту: в нём нет лишней терминологии, только факты и решения — какой модуль снят, какой оставлен ещё на ночь, какой будет пересмотрен через 12–24 часа. Финансовая прозрачность следует той же логике: расширение проводится только по показаниям с указанием цели («какой маркер планируем улучшить») и окна переоценки («когда проверяем результат»).
Исследовать вопрос подробнее - наркологическая клиника вывод из запоя в ростове-на-дону
https://opalubka.market/ opalubka market
Modern Roots Hub Online – Fresh products arranged neatly, exploring the store is simple.
Silver Branch Essentials – Elegant presentation and carefully curated items make browsing enjoyable.
дайсон официальный сайт фен дайсон официальный сайт фен .
moomoo証券 wiki
Modern Roots Market – Fresh modern products displayed nicely, browsing feels smooth and convenient.
кровать москва Выбирая мебель, не стоит забывать, что она должна быть не только красивой, но и функциональной. Каталог мебели – ваш надежный помощник в поиске идеального решения. Сайт мебели предложит вам самые актуальные модели и поможет сравнить цены. Фабрика мебели гарантирует качество и долговечность. Кровать, кресло, диван – каждый предмет мебели должен быть тщательно выбран, чтобы создать гармоничное и комфортное пространство. Дизайн-проект поможет вам визуализировать свою мечту, а магазин мебели предложит широкий ассортимент товаров. Мебель на заказ – это возможность создать уникальный интерьер, который будет соответствовать всем вашим потребностям и пожеланиям. Диван раскладной – это практичное и функциональное решение для небольших помещений. Детская мебель должна быть безопасной и экологически чистой. Детская кроватка – это место, где ваш малыш будет проводить большую часть времени, поэтому к ее выбору следует подойти с особой ответственностью. Двухъярусная кровать – это отличное решение для детской комнаты, где живут двое детей.
SilverBranch Treasures – Clean, stylish layout with attractive designs that stand out.
Вызов нарколога на дом — это не «универсальная капельница», а управляемая последовательность маленьких шагов с понятными целями и точками проверки. В наркологической клинике «КубаньМед Резолюция» выезд врача, инфузионная поддержка и лечение зависимостей складываются в дорожную карту: мы начинаем с короткого триежа, формулируем рабочую гипотезу, включаем минимально достаточный модуль, назначаем «окно оценки» и только затем либо выключаем модуль, либо изменяем одну переменную. Такой подход снижает фармаконагрузку, предотвращает полипрагмазыю и делает динамику прозрачной: пациент и семья видят, что именно помогает и когда вмешательство завершается.
Получить дополнительные сведения - https://narkolog-na-dom-v-krasnodare16.ru/narkolog-krasnodar-anonimno/
WildRose Finds – Warm and inviting atmosphere, browsing revealed a few delightful items.
TrendSpotStore – Quick access to fashionable items, easy navigation, and smooth experience.
Bright Choice Online – Found everything structured clearly, and the overall look felt open and accessible.
Home & Lifestyle Collective – Felt cozy and sustainable, every item seemed thoughtfully selected.
Эта последовательность действий обеспечивает безопасное прекращение запоя и предотвращает развитие синдрома отмены.
Выяснить больше - наркологический вывод из запоя
WildRose Finds Online – Boutique has a warm and charming vibe, browsing was enjoyable.
FashionTrendShop – Trendy selections, easy navigation, and an enjoyable shopping flow.
Bright Choice Deals – Simple navigation and friendly layout made finding items stress-free.
Ethical Living Studio – Easy to navigate with unique and eco-friendly finds throughout the site.
authenticsupplyzone – AuthenticSupplyZone offers genuine items with a clean, easy-to-navigate layout.
https://kitehurghada.ru/ кайт египет
naturallyselectedhub – NaturallySelectedHub delivers authentic, well-made items that make exploring fun.
интересно Беспорядок: хаос в мире и в голове. Размышления и истории.
При домашнем формате мы сразу закладываем «мостик» к стационару: в случае ухудшения состояния перевод происходит бесшовно, по заранее оговорённым критериям. Пациент и семья знают, какие маркеры считаются целевыми (переносимость воды, ровный вечерний пульс, время до засыпания, число пробуждений), и когда состоится повторная оценка. Прозрачность снимает суету и укрепляет приверженность плану.
Получить дополнительные сведения - https://kapelnicza-ot-zapoya-murmansk15.ru/kapelnicza-ot-pokhmelya-murmansk
Мы переводим субъективные ощущения в простые маркеры, чтобы решения не зависели от настроения и ожиданий. Базовый набор: объём выпитой воды в час; ЧСС/АД в покое; длительность сна и число пробуждений; шкалы тошноты/тремора/тревоги; две утренние бытовые задачи. В отчёте фиксируется, какой модуль включён, какой маркер он должен сдвинуть, в каком окне мы проверяем результат и при каком значении модуль выключается. Это защищает от «инерции лечения» и делает финансовую часть предсказуемой: расширения назначаются только по показаниям с указанием цели и времени переоценки.
Подробнее можно узнать тут - http://narkolog-na-dom-v-krasnodare16.ru
Женский сайт https://loveliness.kyiv.ua с практичным контентом: уход за кожей и волосами, стильные образы, дом и уют, дети, работа и финансы. Полезные рекомендации, экспертные материалы и вдохновение без лишней «воды». Удобная навигация по рубрикам и регулярные обновления.
Универсальный авто https://kolesnitsa.com.ua портал для водителей и будущих владельцев: обзоры автомобилей, сравнение комплектаций, тест-драйвы, советы по ТО и ремонту, подбор шин и аксессуаров. Актуальные новости, аналитика рынка и материалы, которые помогают делать осознанный выбор.
Онлайн женский https://lugor.org.ua сайт для тех, кто ценит своё время: гайды по красоте и стилю, психологические советы, идеи для дома, отношения, материнство и карьерные цели. Подборки, чек-листы, истории и советы, которые реально работают в повседневной жизни.
Украинский новостной https://mediacentr.com.ua портал с акцентом на объективность и факты: свежие новости, аналитические статьи, интервью и спецпроекты. Освещаем жизнь страны, реформы, фронт, дипломатию и повседневные истории людей. Всё важное — на одной площадке.
Женский сайт https://loveliness.kyiv.ua с практичным контентом: уход за кожей и волосами, стильные образы, дом и уют, дети, работа и финансы. Полезные рекомендации, экспертные материалы и вдохновение без лишней «воды». Удобная навигация по рубрикам и регулярные обновления.
Универсальный авто https://kolesnitsa.com.ua портал для водителей и будущих владельцев: обзоры автомобилей, сравнение комплектаций, тест-драйвы, советы по ТО и ремонту, подбор шин и аксессуаров. Актуальные новости, аналитика рынка и материалы, которые помогают делать осознанный выбор.
Онлайн женский https://lugor.org.ua сайт для тех, кто ценит своё время: гайды по красоте и стилю, психологические советы, идеи для дома, отношения, материнство и карьерные цели. Подборки, чек-листы, истории и советы, которые реально работают в повседневной жизни.
Украинский новостной https://mediacentr.com.ua портал с акцентом на объективность и факты: свежие новости, аналитические статьи, интервью и спецпроекты. Освещаем жизнь страны, реформы, фронт, дипломатию и повседневные истории людей. Всё важное — на одной площадке.
みんなの fx
StyleHubNow – Clean layout and fast pages make checking out fashion items easy.
TrendySpot – Fast site load and intuitive navigation enhance the shopping experience.
Мы не ограничиваемся капельницей. Сервис включает организационные, клинические и поведенческие элементы, которые уменьшают хаос и ускоряют восстановление. Ниже — ключевые блоки, которые пациенты отмечают в отзывах как наиболее полезные и «приземлённые».
Углубиться в тему - нарколог на дом срочно самара
fashion trend zone – Products are appealing, site layout is clear and smooth to explore.
modern fashion hub – Trendy selections displayed nicely, browsing feels smooth and easy.
WildBrook Modern Lifestyle – Contemporary and trendy style, exploring the store was fun.
WildBrook Modern Selection – Stylish and fresh, the overall experience was calm and pleasant.
В клинике применяются современные методы лечения, включающие медикаментозную терапию, психотерапию и физиологическое восстановление. Такой подход позволяет достигнуть стойкого результата и предотвратить возвращение к употреблению алкоголя.
Получить дополнительные сведения - [url=https://kapelnicza-ot-zapoya-v-nizhnem-novgorode16.ru/]поставить капельницу от запоя на дому нижний новгород[/url]
WillowCraft Outlet – Neat structure and easy-to-find items, overall pleasant experience.
Blue Willow Essentials – Everything is presented simply and clearly, making navigation quick.
Для сохранения приватности мы ведём коммуникацию через одного доверенного представителя, используем нейтральные формулировки в документах, а инструкции выдаём в неброском виде. При невозможности создать тишину дома (ремонт, маленькие дети, гости) предложим краткий «тихий» стационар с отдельным входом и камерным режимом, после чего сопровождение вернётся в домашний формат.
Подробнее можно узнать тут - [url=https://vyvod-iz-zapoya-v-ekaterinburge16.ru/]вывод из запоя дешево екатеринбург[/url]
Сочетание медицинских и психотерапевтических мер создаёт устойчивую систему поддержки. Пациенты получают возможность постепенно восстановить утраченное здоровье и психологическую стабильность.
Ознакомиться с деталями - http://narkologicheskaya-klinika-v-kazani16.ru/chastnaya-narkologicheskaya-klinika-kazan/
Корректная среда — половина успешной инфузии. Этот порядок действий помогает врачу быстрее принять решения, а пациенту — легче перенести первые часы.
Получить дополнительные сведения - www.domen.ru
Эта схема помогает постепенно вывести пациента из кризисного состояния, снизить риски осложнений и закрепить результаты лечения.
Получить дополнительную информацию - наркологическая клиника стационар краснодар
Shop Everything Hub – Pleasant browsing with well-arranged items and clear navigation.
Urban Designs Lane – Modern style and neatly arranged items make browsing pleasant and fast.
В Екатеринбурге бригады выезжают 24/7, покрывая как центральные районы, так и отдалённые кварталы. Координатор уточняет только то, что влияет на безопасность: принимаемые лекарства и дозы, аллергии, эпизоды судорог/психозов, исходные значения давления и пульса, а также бытовые условия — можно ли обеспечить «тихое окно» на 2–3 часа, есть ли свободная розетка и место для полулёжа. Врач приезжает с портативным мониторингом, расходными материалами и резервным планом на случай повышенной реактивности.
Ознакомиться с деталями - [url=https://vyvod-iz-zapoya-v-ekaterinburge16.ru/]скорая вывод из запоя[/url]
Day Shopping Market – Fast-loading pages and an inviting setup make exploring enjoyable.
UrbanWild Lane – Creative visuals and a modern interface allow users to browse effortlessly.
WildRose Lifestyle Online – Cozy, inviting atmosphere, browsing revealed a few standout items.
В мегаполисе привычный ритм часто мешает системному лечению: плотный график, транспортные задержки, высокая социальная видимость. Чтобы терапия проходила спокойно, «НеоТрезвие СПБ» использует «немаркированную» логистику: нейтральные формулировки в документах, аккуратные визиты, разнесенные по времени консультации специалистов и персональный координатор. По желанию пациента часть этапов — образовательные сессии и посткодовое сопровождение — выполняются онлайн. Это снижает тревогу и делает маршрут лечения менее заметным для окружения.
Разобраться лучше - [url=https://kodirovanie-ot-alkogolizma-v-spb16.ru/]кодирование от алкоголизма адрес в санкт-петербурге[/url]
MoonCrest Studio – Creative products showcased well, navigating the site is intuitive and fast.
WildRose Hub – Charming and cozy feel, exploring the store was very enjoyable.
MoonCrest Online Studio – Attractive designs showcased clearly, navigation feels easy and intuitive.
Everwild Store – Product selection is appealing, and navigation feels fast and natural.
GiftChoiceStore – Items are eye-catching, site navigation is simple and pleasant.
Everwild Spot – Wide assortment presented neatly, and the shopping experience feels smooth.
Curated Modern Finds – Loved the quality of items, the store feels very thoughtfully arranged.
UrbanGiftMarket – Fast navigation, lovely gifts, and easy-to-use layout.
Quiet Plains Market Hub – The site loaded fast, and browsing through sections felt very comfortable.
Unique Gift Online – Intuitive navigation and clear layout make exploring gifts simple and enjoyable.
Modern Quality Hub – Items feel high-quality and clean, exploring the site is a pleasant experience.
Карта — это общий язык для всех участников процесса. Пациент видит смысл каждого шага, родные знают, когда и чему посвящены короткие апдейты, а врач точно понимает, какой параметр корректировать, чтобы не потерять причинно-следственную связь.
Детальнее - [url=https://vyvod-iz-zapoya-murmansk15.ru/]нарколог вывод из запоя мурманск[/url]
Quiet Plains Essentials – Calm design with fast-loading pages and easy-to-browse categories.
Unique Gift Lane Studio – Attractive gift displays with easy navigation make browsing effortless.
Elite Finds Collection – Carefully curated collection with visually appealing and user-friendly design.
Команда клиники — это врачи-наркологи, психиатры-консультанты, специалисты интенсивной терапии, клинический психолог, психотерапевт и медсёстры с опытом круглосуточного поста. Мы разговариваем «языком фактов»: витальные показатели, шкалы симптомов, дневники воды и сна, малые бытовые цели. Такой язык исключает стигму и «магическое мышление»; он понятен семье и помогает принимать решения без страхов и «подстраховочных» излишков.
Выяснить больше - http://narkologicheskaya-klinika-v-rostove-na-donu16.ru/
Top Premium Finds – Premium products presented with clarity, easy browsing, and neat layout.
В Казани дежурят мобильные бригады, покрывающие центральные районы и спальные кварталы. Координатор по телефону собирает лишь данные, влияющие на безопасность: текущие лекарства и дозировки, аллергии, эпизоды судорог/психозов в анамнезе, последние значения АД/ЧСС, температуру, а также бытовые условия — место полулёжа, доступ к розетке, возможность «тихого окна» на 2–3 часа. Врач приезжает быстро, но спокойно; вместо суеты — последовательность и аккуратные действия. Визит начинается с очного осмотра, где фиксируются исходные показатели и выбирается контур терапии. Далее выполняется тест переносимости и только затем — основной инфузионный этап. По завершении пациент получает «вечерний протокол» с простыми ритуалами: приглушить свет, проветрить комнату, исключить экраны за час до сна, пить воду малыми глотками.
Подробнее - https://narkologicheskaya-pomoshh-v-kazani16.ru/skoraya-narkologicheskaya-pomoshh-kazan/
станица благовещенская кайтсерфинг горящие туры
Анонимная наркологическая помощь — это не «быстрая капельница и забыли», а последовательный и конфиденциальный процесс, в котором каждое вмешательство имеет цель, измеримый маркер и заранее оговорённое «окно проверки». В наркологической клинике «Южный Мед Центр Ренова» мы совмещаем непрерывный приём 24/7, выездные визиты без маркировки, точечную диагностику, инфузионную поддержку, психотерапевтические сессии и план посттерапевтического сопровождения. Приоритет — приватность и минимально достаточные решения: чем меньше случайных назначений, тем больше управляемости и предсказуемости. Мы говорим «языком фактов», а не оценок: витальные показатели, шкалы симптомов (0–10), структура сна, переносимость воды, простые бытовые задачи на утро. Это помогает семье и пациенту видеть, что именно работает, и выключать вмешательства, когда они сделали своё дело.
Узнать больше - narkologicheskaya-clinika-v-rostove-na-donu16.ru/
Процесс лечения в клинике организован последовательно и направлен на восстановление всех систем организма. Каждый этап имеет свои задачи и методы, что обеспечивает максимальную эффективность терапии.
Детальнее - [url=https://narkologicheskaya-clinika-v-samare16.ru/]наркологическая клиника вывод из запоя[/url]
Капельница — это не «секретный коктейль», а набор узких модулей, каждый из которых отвечает за одну задачу. Мы включаем ровно один новый модуль за раз и заранее обозначаем стоп-критерий, чтобы не тянуть терапию «по инерции». Параллельно настраиваются поведенческие элементы: свет, тишина, дыхательные ритмы и «окна» питья. Это снимает часть нагрузки с организма и ускоряет наступление целевых маркеров.
Углубиться в тему - нарколог на дом круглосуточно цены
Состояния при зависимостях чувствительны к времени суток и среде. К ночи нарастает тревога, усиливается тремор, нестабильны показатели ЧСС/АД. Круглосуточный приём позволяет выстроить «мост» через самые сложные часы: собрать сон без избыточной фармаконагрузки, сделать короткие чек-ины, вовремя ретитровать один параметр (свет, дыхательные ритмы, интервалы питья), а утром оформить «малые победы» — гигиена и 10–15 минут тихой ходьбы. Эти простые маркеры часто надёжнее любых субъективных оценок «как себя чувствую».
Узнать больше - http://narkologicheskaya-clinika-v-rostove-na-donu16.ru
GiftVault – Smooth browsing experience and attractive gift items throughout.
Процесс включает:
Выяснить больше - вывод из запоя вызов на дом
GiftExplorer – Clear layout with intuitive navigation and beautiful gift options.
fashion zone hub – Trendy selections are appealing, site feels quick and intuitive.
modern fashion picks – Items look modern, navigation is smooth and easy to explore.
Новостной портал https://infosmi.com.ua Украины: главные события дня, оперативная лента, аналитика и мнения экспертов. Политика, экономика, общество, война и международные новости. Чёткая подача, удобная структура разделов и регулярные обновления в режиме 24/7.
Онлайн новостной https://expressnews.com.ua портал для тех, кто хочет быть в курсе: свежие новости, обзоры, спецпроекты и авторские материалы. Политика, бизнес, общество, наука, культура и спорт — всё в одном месте, с понятной подачей и регулярными обновлениями 24/7.
Украинский новостной https://medicalanswers.com.ua портал: главные новости, расширенные обзоры, разбор решений власти, ситуации на фронте и жизни граждан. Фото, видео, инфографика и мнения экспертов помогают глубже понять происходящее в Украине и вокруг неё.
Портал о технологиях https://technocom.dp.ua новости IT и гаджетов, обзоры смартфонов и ноутбуков, сравнения, тесты, инструкции и лайфхаки. Искусственный интеллект, кибербезопасность, софт, цифровые сервисы и тренды — простым языком и с пользой для читателя.
Портал смачних ідей https://mallinaproject.com.ua прості рецепти на щодень, святкові страви, десерти, випічка та корисні перекуси. Покрокові інструкції, поради, підбірки меню й лайфхаки для кухні. Готуйте швидко, смачно та з натхненням разом із нами.
Новостной портал https://infosmi.com.ua Украины: главные события дня, оперативная лента, аналитика и мнения экспертов. Политика, экономика, общество, война и международные новости. Чёткая подача, удобная структура разделов и регулярные обновления в режиме 24/7.
Онлайн новостной https://expressnews.com.ua портал для тех, кто хочет быть в курсе: свежие новости, обзоры, спецпроекты и авторские материалы. Политика, бизнес, общество, наука, культура и спорт — всё в одном месте, с понятной подачей и регулярными обновлениями 24/7.
Украинский новостной https://medicalanswers.com.ua портал: главные новости, расширенные обзоры, разбор решений власти, ситуации на фронте и жизни граждан. Фото, видео, инфографика и мнения экспертов помогают глубже понять происходящее в Украине и вокруг неё.
Портал о технологиях https://technocom.dp.ua новости IT и гаджетов, обзоры смартфонов и ноутбуков, сравнения, тесты, инструкции и лайфхаки. Искусственный интеллект, кибербезопасность, софт, цифровые сервисы и тренды — простым языком и с пользой для читателя.
Портал смачних ідей https://mallinaproject.com.ua прості рецепти на щодень, святкові страви, десерти, випічка та корисні перекуси. Покрокові інструкції, поради, підбірки меню й лайфхаки для кухні. Готуйте швидко, смачно та з натхненням разом із нами.
WildRose Essentials – Warm and friendly environment, browsing uncovered a few gems.
WildRose Essentials – Warm and friendly environment, browsing uncovered a few gems.
Если дома нет возможности обеспечить тишину (ремонт, маленькие дети, гости), можно кратко перейти в «тихий стационар» с отдельным входом; после стабилизации сопровождение возвращается на дом, и маршрут продолжается «зеркально» — с теми же целями и окнами оценки. Такой перенос сохраняет управляемость процесса и снижает тревогу семьи: никто не «начинает сначала», меняется только место, а логика остаётся прежней.
Выяснить больше - https://narkologicheskaya-pomoshh-v-kazani16.ru/narkologicheskaya-sluzhba-kazan
Mountain Mist Outlet – Products presented clearly, navigating is intuitive and pleasant.
Mountain Mist Finds Hub – Beautiful mountain-inspired items, browsing the site is easy and pleasant.
TrendPulseStore – Organized layout, quick access to items, and enjoyable navigation.
Curated Discoveries Hub – Clean and organized layout with eye-catching products, browsing was enjoyable.
Для сохранения приватности мы ведём коммуникацию через одного доверенного представителя, используем нейтральные формулировки в документах, а инструкции выдаём в неброском виде. При невозможности создать тишину дома (ремонт, маленькие дети, гости) предложим краткий «тихий» стационар с отдельным входом и камерным режимом, после чего сопровождение вернётся в домашний формат.
Выяснить больше - [url=https://vyvod-iz-zapoya-v-ekaterinburge16.ru/]вывод из запоя дешево в екатеринбурге[/url]
UrbanTrendHub – Smooth navigation, stylish items, and a clean interface.
Терапия проводится в комфортных условиях с использованием сертифицированных препаратов и современных медицинских технологий. Команда врачей, психологов и реабилитологов обеспечивает поддержку на всех этапах лечения.
Подробнее тут - [url=https://narkologicheskaya-clinika-v-kazani16.ru/]наркологическая клиника клиника помощь[/url]
Прогон Xrumer телеграм Обучение Xrumer телеграм: Обучение Xrumer телеграм – это специализированный курс, посвященный использованию Xrumer для продвижения Telegram-каналов и групп. В рамках обучения рассматриваются особенности работы с базами сайтов, ориентированных на Telegram, а также стратегии привлечения целевой аудитории.
Ethical Commerce Hub – A bright and organized layout with interesting items, really enjoyed exploring today.
Plains Trading Select – Calm and organized layout with smooth browsing throughout the site.
Для наглядности представлена таблица с основными направлениями терапии и их эффектами:
Подробнее - наркологическая клиника нарколог краснодар
Plains Trading Corner – Fast response times and organized categories made exploration easy.
Curated Premium Picks – Thoughtfully arranged products with intuitive navigation and clean layout.
Global Premium Market – Premium selections showcased neatly for effortless navigation.
Everwood Market – The store feels responsive, and finding items is fast and simple.
Мужской портал https://phizmat.org.ua о стиле, здоровье, отношениях и деньгах. Свежие новости, честные обзоры гаджетов и авто, тренировки и питание, подборки фильмов и игр, лайфхаки для работы и отдыха — без воды и кликбейта. Советы, инструкции и тесты каждый день.
Туристический портал https://prostokarta.com.ua о путешествиях по России и миру: маршруты, города и страны, советы туристам, визы и перелёты, отели и жильё, обзоры курортов, идеи для отдыха, лайфхаки, личный опыт и актуальные новости туризма.
Срочный эвакуатор Дмитров: оперативный выезд, подача от 20 минут. Перевозка автомобилей после ДТП и поломок, межгород, бережная транспортировка. Работаем круглосуточно, без скрытых доплат, принимаем заявки в любое время.
Женский журнал https://eternaltown.com.ua о стиле, красоте и здоровье. Мода и тренды, уход за кожей и волосами, отношения и психология, дом и семья, карьера и саморазвитие. Полезные советы, подборки, интервью и вдохновение каждый день.
Поэтапный подход помогает достичь устойчивых результатов и минимизировать вероятность рецидива, обеспечивая безопасность пациента на всех стадиях лечения.
Изучить вопрос глубже - http://narkologicheskaya-clinika-v-samare16.ru
EverForest Collective Store – Loved the calm, earthy feel of the products and how smoothly everything navigates.
Everwood Choices – Everything appears organized and responsive, simplifying the shopping process.
Motivation Market – Pages open fast and the overall atmosphere feels encouraging.
Наркологическая клиника в клинике в Нижнем Новгороде специализируется на диагностике, лечении и реабилитации пациентов с алкогольной и наркотической зависимостью. Основная цель деятельности учреждения — восстановление физического здоровья и психологической устойчивости человека, оказавшегося в состоянии зависимости. В клинике применяются современные методы терапии, доказавшие эффективность в медицинской практике. Все процедуры проводятся конфиденциально, с соблюдением медицинских стандартов и под контролем квалифицированных специалистов.
Узнать больше - https://narkologicheskaya-clinika-v-nizhnem-novgorode16.ru/
Мужской портал https://phizmat.org.ua о стиле, здоровье, отношениях и деньгах. Свежие новости, честные обзоры гаджетов и авто, тренировки и питание, подборки фильмов и игр, лайфхаки для работы и отдыха — без воды и кликбейта. Советы, инструкции и тесты каждый день.
Туристический портал https://prostokarta.com.ua о путешествиях по России и миру: маршруты, города и страны, советы туристам, визы и перелёты, отели и жильё, обзоры курортов, идеи для отдыха, лайфхаки, личный опыт и актуальные новости туризма.
Срочный эвакуатор Дмитров: оперативный выезд, подача от 20 минут. Перевозка автомобилей после ДТП и поломок, межгород, бережная транспортировка. Работаем круглосуточно, без скрытых доплат, принимаем заявки в любое время.
Для жителей Ростова-на-Дону клиника работает по схеме «тихих маршрутов»: отдельный вход с нейтральной табличкой, окна записи в невызывающие подозрений часы, немаркированный подъезд автомобиля при выездном визите. На первом звонке диспетчер собирает только то, что влияет на безопасность: эпизоды рвоты, ЧСС/АД, ночные панические эпизоды, сопутствующие препараты, аллергии, наличие хронических заболеваний сердца. Личные и социальные детали не запрашиваются — мы придерживаемся принципа «минимально необходимой информации». По прибытии врача фиксируются базовая линия (сознание, дыхание, SpO?, температура), шкалы симптомов и переносимость небольших объёмов воды. Дальше — один точный шаг, одно «окно проверки» и прозрачное решение: продолжать модуль, модифицировать одну переменную или выключить блок.
Получить дополнительные сведения - частная наркологическая клиника
Женский журнал https://eternaltown.com.ua о стиле, красоте и здоровье. Мода и тренды, уход за кожей и волосами, отношения и психология, дом и семья, карьера и саморазвитие. Полезные советы, подборки, интервью и вдохновение каждый день.
EverForest Home Shop – Loved the simple structure and earthy presentation throughout the catalog.
FreshInspire Place – Navigation feels effortless and the website’s tone is encouraging.
Gift Place Unique – Attractive presentation of items, smooth interface, and easy-to-browse sections.
Мы не используем «универсальные коктейли». Капельницы собираются из модулей под ведущую задачу, а поведенческая часть усиливает эффект. Окончательные назначения делает врач с учётом противопоказаний и взаимодействий; таблица ниже — ориентир для пациента и семьи.
Получить дополнительную информацию - [url=https://vyvod-iz-zapoya-murmansk15.ru/]вывод из запоя на дому[/url]
GlowMarket Picks – Clean, crisp design with well-placed products keeps the shop elegant and accessible.
UniqueGift Finds – Clear layout with a great selection of gifts, pages load quickly and navigation is simple.
EverGlow Creative – A modern, visually appealing design enhances product visibility and flow.
modern shopping picks – Items are appealing, navigating the site is smooth and natural.
modern shopping finds – Products are trendy, site feels clean and user-friendly.
гет икс зеркало гет икс зеркало .
фен дайсон оригинал фен дайсон оригинал .
дайсон купить стайлер для волос с насадками цена официальный сайт fen-ds-1.ru .
дайсон официальный сайт фен https://www.stajler-d-1.ru .
фен дайсон купить оригинал https://fen-d-1.ru/ .
стайлер дайсон стайлер дайсон .
фен купить дайсон фен купить дайсон .
дайсон официальный сайт в россии www.fen-ds-2.ru/ .
решение курсовых работ на заказ решение курсовых работ на заказ .
гет икс регистрация гет икс регистрация .
дайсон фен цена официальный сайт https://www.stajler-d.ru .
фен купить dyson оригинал фен купить dyson оригинал .
цена стайлер дайсон для волос с насадками официальный сайт купить https://www.fen-d-2.ru .
стайлер для волос дайсон с насадками официальный сайт купить цена stajler-d-3.ru .
фен купить dyson оригинал фен купить dyson оригинал .
дайсон купить стайлер официальный сайт https://dn-fen-1.ru/ .
официальный сайт dyson фен https://dn-fen-2.ru .
официальный сайт дайсон в москве интернет магазин http://fen-ds-1.ru .
Ниже — ориентировочная матрица первых часов. Она не заменяет очной оценки, но показывает, как мы переводим наблюдения в действия и какие критерии считаем достаточными для переключения модуля. Приведённые окна проверки помогают не тянуть с нужными корректировками и одновременно не «дергать» схему без повода.
Получить дополнительную информацию - платная наркологическая клиника
адвокат днепр Важно выбрать опытного адвоката, обладающего хорошей репутацией и знанием особенностей местного законодательства
Терапия проводится в комфортных условиях с использованием сертифицированных препаратов и современных медицинских технологий. Команда врачей, психологов и реабилитологов обеспечивает поддержку на всех этапах лечения.
Подробнее можно узнать тут - https://narkologicheskaya-clinika-v-kazani16.ru
Профессиональное агентство интернет маркетинга для малого и среднего бизнеса. Настройка рекламы, продвижение сайтов, рост заявок и продаж. Аналитика, оптимизация и постоянный контроль эффективности рекламных кампаний.
Нужно межевание? межевой план участка профессиональное межевание участка для оформления и регистрации прав. Геодезические измерения, уточнение границ, межевой план, сопровождение в Росреестре. Опытные кадастровые инженеры, точность и прозрачная стоимость.
Продажа тяговых аккумуляторных https://e-battery.ru батарей для вилочных погрузчиков - надёжные решения для стабильной работы складской техники. Подбор АКБ по параметрам, доставка, установка, долгий ресурс и высокая производительность для интенсивной эксплуатации
дайсон стайлер для волос купить цена с насадками официальный сайт fen-d-1.ru .
дайсон фен цена официальный сайт https://www.stajler-d-1.ru .
официальный сайт дайсон официальный сайт дайсон .
дайсон купить стайлер для волос с насадками цена официальный сайт www.fen-ds-3.ru .
дайсон стайлер для волос цена официальный сайт купить с насадками http://fen-ds-2.ru/ .
купить курсовую москва купить курсовую москва .
дайсон стайлер для волос официальный сайт с насадками купить цена http://fen-ds-4.ru/ .
Нужно межевание? кадастровое межевание земельного участка профессиональное межевание участка для оформления и регистрации прав. Геодезические измерения, уточнение границ, межевой план, сопровождение в Росреестре. Опытные кадастровые инженеры, точность и прозрачная стоимость.
Профессиональное агентство интернет маркетинга для малого и среднего бизнеса. Настройка рекламы, продвижение сайтов, рост заявок и продаж. Аналитика, оптимизация и постоянный контроль эффективности рекламных кампаний.
официальный сайт dyson https://dn-fen-3.ru/ .
купить стайлер дайсон официальный сайт www.dn-fen-1.ru .
купить дайсон стайлер с насадками официальный сайт для волос цена https://www.dn-fen-2.ru .
официальный магазин дайсон https://stajler-d.ru/ .
Продажа тяговых аккумуляторных https://e-battery.ru батарей для вилочных погрузчиков - надёжные решения для стабильной работы складской техники. Подбор АКБ по параметрам, доставка, установка, долгий ресурс и высокая производительность для интенсивной эксплуатации
Нужен аккумулятор? аккумулятор автомобильный купить цена подбор АКБ по марке и модели авто, большой выбор ёмкости и пускового тока. Доставка, самовывоз, выгодные условия и помощь в установке.
дайсон стайлер для волос цена официальный сайт купить с насадками http://www.fen-d-2.ru .
All the latest is here: https://podcasts.apple.com/gr/podcast/christmas-puzzles/id1698189758?i=1000740676982
Wild Rose Treasures – Pleasant browsing experience with delightful surprises along the way.
Нужен аккумулятор? аккумуляторы автомобильные спб подбор АКБ по марке и модели авто, большой выбор ёмкости и пускового тока. Доставка, самовывоз, выгодные условия и помощь в установке.
Things Worth Watching: https://vds94837.shotblogs.com/play-digital-jigsaw-puzzles-for-free-52867482
Wild Rose Emporium Online – Lovely boutique with a charming feel, discovered several nice surprises.
Круглосуточный формат критичен именно из-за «первой ночи»: в это окно нестабильны тревога, сон, вегетативная реактивность. Мы не «усиливаем всё сразу», а по одному параметру доводим систему до целевого коридора. Так удаётся избежать полипрагмазии и сохранить управляемость процесса: пациент и семья заранее знают, какие цифры считаются нормой, когда звонить дежурному, как организовать свет и тишину, чтобы ночное восстановление действительно состоялось.
Получить дополнительные сведения - наркологическая клиника нарколог в ростове-на-дону
WildBrook Modern Selection – Stylish and fresh, the overall experience was calm and pleasant.
Реабилитационные программы в наркологической клинике направлены на нормализацию обменных процессов, восстановление сна, эмоциональной стабильности и когнитивных функций. Для достижения этого используются методы физиотерапии, нутритивной поддержки и коррекции поведения. Основное внимание уделяется мотивации пациента, работе с созависимостью и обучению навыкам здорового взаимодействия с окружающей средой.
Получить дополнительные сведения - [url=https://narkologicheskaya-klinika-v-ekb16.ru/]наркологическая клиника лечение алкоголизма екатеринбург[/url]
Mountain Star Boutique Hub – Trend-focused items arranged neatly, navigation is smooth and easy.
WildBrook Modern Hub – The collection feels fresh and polished, navigation was smooth.
Mountain Star Finds – Attractive trends displayed beautifully, exploring the site is easy.
Creative Selections Collective – Layout is tidy and vibrant, discovering items was very smooth.
Tall Cedar Finds Studio – Smooth navigation and a welcoming feel make exploring a pleasure.
QuickValueHub – Smooth browsing, solid picks, and easy-to-use interface.
Наркологическая клиника в клинике в Екатеринбурге — это специализированное медицинское учреждение, где проводится диагностика, лечение и реабилитация людей, страдающих алкогольной или наркотической зависимостью. Комплексный подход включает не только медикаментозную терапию, но и психотерапевтические методики, направленные на восстановление личности и возвращение пациента к социальной активности. Каждое вмешательство проводится с учётом физического состояния, психологического профиля и стадии заболевания. Работа специалистов основана на принципах анонимности, медицинской этики и научно доказанных протоколов лечения.
Ознакомиться с деталями - [url=https://narkologicheskaya-klinika-v-ekb16.ru/]лечение в наркологической клинике екатеринбург[/url]
Лечение в клинике строится на комплексной программе, которая сочетает медикаментозную терапию, психотерапевтические методы и социальную реабилитацию. Такой подход обеспечивает устойчивый результат и предотвращает повторные срывы. Пациент проходит курс под постоянным контролем специалистов, что позволяет отслеживать динамику состояния и корректировать терапию при необходимости.
Получить дополнительные сведения - http://
Tall Cedar Finds Online – Smooth, enjoyable browsing with a cozy, inviting feel.
Creative Commerce Collective – Loved the vibrant and engaging collection, browsing felt effortless and inspiring.
SmartDealsHub – Fast-loading, easy-to-use interface with great value items.
Rainy Collection Hub – Well-organized sections and smooth browsing enhanced the shopping experience.
Курсы арабского языка https://shams-arab.ru блог с полезными статьями, упражнениями и примерами. Разбираем грамматику, лексику, диалоги и особенности языка. Делимся советами по обучению, мотивации и выбору формата занятий.
Сервис помощи https://students-helper.ru студентам с учебными работами. Курсовые, контрольные, рефераты, отчёты и презентации. Индивидуальный подход, соблюдение сроков, доработки по требованиям преподавателя и конфиденциальность.
RainyCity Online – Lovely page design with fast navigation and nicely presented items.
Школа БПЛА https://obucheniebpla.ru обучение управлению беспилотными летательными аппаратами с нуля и для продвинутых. Практика полётов, основы безопасности, навигация, аэрофотосъёмка и подготовка операторов дронов по современным стандартам.
Обучение родителей https://mother-massage.ru массажу и гимнастике для детей от рождения до года. Практические занятия, безопасные техники, развитие моторики и укрепление здоровья малыша. Поддержка специалиста, пошаговые рекомендации и уверенность родителей.
Образовательный блог https://za-obrazovanie.ru о методиках обучения и развитии навыков. Статьи о преподавании, педагогике, оценивании, мотивации и работе с детьми и взрослыми. Практика, кейсы и полезные материалы.
Курсы арабского языка https://shams-arab.ru блог с полезными статьями, упражнениями и примерами. Разбираем грамматику, лексику, диалоги и особенности языка. Делимся советами по обучению, мотивации и выбору формата занятий.
Сервис помощи https://students-helper.ru студентам с учебными работами. Курсовые, контрольные, рефераты, отчёты и презентации. Индивидуальный подход, соблюдение сроков, доработки по требованиям преподавателя и конфиденциальность.
Elevated Clicks Market – Sleek design with intuitive browsing and responsive page flow.
Школа БПЛА https://obucheniebpla.ru обучение управлению беспилотными летательными аппаратами с нуля и для продвинутых. Практика полётов, основы безопасности, навигация, аэрофотосъёмка и подготовка операторов дронов по современным стандартам.
купить стайлер дайсон официальный сайт купить стайлер дайсон официальный сайт .
вызвать эвакуатор Вызвать эвакуатор Когда неприятность застала врасплох, и ваш автомобиль не может продолжать движение, не паникуйте. Просто вызовите наш эвакуатор! Мы работаем круглосуточно и без выходных, чтобы оперативно прийти на помощь в любое время дня и ночи. Наши диспетчеры быстро примут ваш заказ и направят ближайший эвакуатор к вам. Мы гарантируем быструю подачу и безопасную транспортировку вашего автомобиля.
Наркологическая клиника в Краснодаре специализируется на лечении алкогольной, наркотической и других видов зависимостей с использованием современных медицинских технологий и индивидуальных программ терапии. Работа специалистов направлена на устранение физической зависимости, восстановление психоэмоционального состояния и возвращение пациента к полноценной жизни. Все процедуры проводятся в безопасных условиях с соблюдением принципов анонимности и врачебной тайны.
Исследовать вопрос подробнее - http://narkologicheskaya-klinika-v-krasnodare16.ru/narkologicheskaya-klinika-krasnodar-otzyvy/
Образовательный блог https://za-obrazovanie.ru о методиках обучения и развитии навыков. Статьи о преподавании, педагогике, оценивании, мотивации и работе с детьми и взрослыми. Практика, кейсы и полезные материалы.
Обучение родителей https://mother-massage.ru массажу и гимнастике для детей от рождения до года. Практические занятия, безопасные техники, развитие моторики и укрепление здоровья малыша. Поддержка специалиста, пошаговые рекомендации и уверенность родителей.
Digital Clickping Market – A visually appealing marketplace with quick navigation and responsive pages.
В Екатеринбурге бригады выезжают 24/7, покрывая как центральные районы, так и отдалённые кварталы. Координатор уточняет только то, что влияет на безопасность: принимаемые лекарства и дозы, аллергии, эпизоды судорог/психозов, исходные значения давления и пульса, а также бытовые условия — можно ли обеспечить «тихое окно» на 2–3 часа, есть ли свободная розетка и место для полулёжа. Врач приезжает с портативным мониторингом, расходными материалами и резервным планом на случай повышенной реактивности.
Узнать больше - http://vyvod-iz-zapoya-v-ekaterinburge16.ru/vyvod-iz-zapoya-ekaterinburg-nedorogo/
дайсон фен оригинал купить дайсон фен оригинал купить .
купить дайсон в москве оригинал https://fen-ds-3.ru/ .
заказать дипломную работу в москве заказать дипломную работу в москве .
фен купить dyson оригинал фен купить dyson оригинал .
дайсон фен оригинал fen-ds-1.ru .
фен дайсон фен дайсон .
купить фен дайсон официальный сайт купить фен дайсон официальный сайт .
Everyday Forest Goods – Affordable everyday items, browsing and finding products feels quick and easy.
дайсон стайлер для волос с насадками купить официальный сайт цена http://fen-d-1.ru .
your trend hub – Trendy items look great, browsing is smooth and convenient.
купить дайсон фен в москве у официального дилера https://stajler-d-2.ru/ .
Everyday Forest Picks Hub – Products appear neatly, and browsing through options feels smooth.
дайсон стайлер цена официальный сайт https://www.dn-fen-2.ru .
дайсон стайлер купить официальный сайт цена для волос с насадками www.fen-ds-3.ru/ .
modern hub click – Trendy items appear neat, site layout feels clean and simple.
куплю курсовую работу куплю курсовую работу .
дайсон стайлер для волос с насадками купить официальный сайт цена https://fen-ds-2.ru/ .
фен дайсон оригинал www.fen-ds-1.ru .
купить фен дайсон официальный купить фен дайсон официальный .
купить фен дайсон в москве у официального дилера dn-fen-3.ru .
фен дайсон официальный сайт http://dn-fen-1.ru/ .
стайлер дайсон купить в спб стайлер дайсон купить в спб .
купить дайсон стайлер с насадками официальный сайт для волос цена https://www.fen-d-1.ru .
стайлер дайсон для волос цена с насадками официальный сайт купить http://dn-fen-2.ru/ .
UniqueValue Picks Online – Clear layout and value-focused product arrangement create an enjoyable experience.
дайсон стайлер для волос купить официальный сайт цена с насадками https://stajler-d-2.ru .
Наркологическая клиника в клинике в Нижнем Новгороде использует многопрофильный подход, направленный на физическое и психологическое восстановление пациентов. После детоксикации проводится стабилизация обменных процессов, нормализация работы внутренних органов и поддержка нервной системы. Особое внимание уделяется коррекции поведения и мотивации пациента к отказу от употребления алкоголя или наркотиков.
Выяснить больше - [url=https://narkologicheskaya-clinika-v-nizhnem-novgorode16.ru/]лечение в наркологической клинике в нижнем новгороде[/url]
фен dyson купить оригинал фен dyson купить оригинал .
Unique Value Hub – Well-organized items, smooth navigation, and a quick, easy browsing experience.
SeasonSelect Shop – Very user-friendly; the product layout is clean and each category is clearly defined.
dyson официальный магазин http://www.dn-fen-1.ru .
фен дайсон купить в москве у официального дилера фен дайсон купить в москве у официального дилера .
Creative Product Browse – Smooth scrolling and organized sections help browsing.
La plateforme 1xbet burkina: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
Site web de parifoot rd congo: paris sportifs, championnats de football, resultats des matchs et cotes. Informations detaillees sur la plateforme, les conditions d’utilisation, les fonctionnalites et les evenements sportifs disponibles.
Site web 1xbet.cd – paris sportifs en ligne sur le football et autres sports. Propose des paris en direct et a l'avance, des cotes, des resultats et des tournois. Description detaillee du service, des fonctionnalites du compte et de son utilisation au Congo.
Поэтапный подход помогает достичь устойчивых результатов и минимизировать вероятность рецидива, обеспечивая безопасность пациента на всех стадиях лечения.
Исследовать вопрос подробнее - анонимная наркологическая клиника в самаре
Contemporary Design Hub – Everything looks thoughtfully placed and easy to find.
Better Season Market – Items display nicely, pages respond quickly, and navigation feels natural.
La plateforme en ligne 1xbet burkina: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
Application mobile telecharger 1xbet apk. Paris sportifs en ligne, football et tournois populaires, evenements en direct et statistiques. Presentation de l'application et de ses principales fonctionnalites.
dyson официальный сайт в россии http://www.stajler-d-1.ru .
La plateforme telecharger 1xbet burkina faso: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
GlowMoon Studio – Minimalistic design and neatly arranged items create a serene shopping flow.
Site web de pari foot rdc: paris sportifs, championnats de football, resultats des matchs et cotes. Informations detaillees sur la plateforme, les conditions d’utilisation, les fonctionnalites et les evenements sportifs disponibles.
Site web 1xbet rdc telecharger – paris sportifs en ligne sur le football et autres sports. Propose des paris en direct et a l'avance, des cotes, des resultats et des tournois. Description detaillee du service, des fonctionnalites du compte et de son utilisation au Congo.
дайсон стайлер для волос с насадками официальный сайт купить цена stajler-d.ru .
Wild Bird Boutique – Each item feels intentionally chosen, browsing here is a pleasure.
MoonGlow Online – Calm visuals and minimal layout make navigating products simple and pleasant.
Корректная среда — половина успешной инфузии. Этот порядок действий помогает врачу быстрее принять решения, а пациенту — легче перенести первые часы.
Исследовать вопрос подробнее - нарколог на дом вывод в самаре
WildBird Treasures Online – Creative and distinctive items, beautifully presented throughout.
Modern Lifestyle Picks – Smooth navigation and a selection of exciting contemporary items.
La plateforme en ligne 1xbet burkina faso: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
Запой сопровождается сильной интоксикацией, обезвоживанием и нарушением обменных процессов. Врач-нарколог оценивает состояние пациента, определяет тяжесть отравления и подбирает индивидуальную схему терапии. Основная цель — восстановление водно-электролитного баланса, нормализация работы сердца, печени и нервной системы. Современные препараты позволяют мягко вывести человека из состояния запоя, исключив развитие судорог, делирия и других осложнений.
Узнать больше - вывод из запоя с выездом
Future Living Hub – Seamless navigation with modern items that feel fresh and exciting.
dyson официальный www.fen-d-2.ru .
Application mobile 1xbet burkina faso. Paris sportifs en ligne, football et tournois populaires, evenements en direct et statistiques. Presentation de l'application et de ses principales fonctionnalites.
дайсон стайлер для волос с насадками купить официальный сайт цена https://stajler-d.ru .
Mountain View Collection – Well-laid-out products, shopping is easy and pleasant today.
dyson официальный магазин https://stajler-d-3.ru .
Wild Rose Picks – Boutique has a lovely atmosphere, found some special items easily.
Global Intentions Store – Navigation was smooth, and the items have a clear sense of quality and purpose.
Mountain View Deals – Great selections available, site navigation is smooth and easy.
официальный сайт dyson www.fen-d-2.ru .
WildRose Treasures Online – Charming setup with some standout products, exploring was fun.
Curated Global Hub – Loved how effortless it is to browse, items feel quality-driven and intentional.
QuickValueOutlet – Easy-to-use interface, deals are visible, and browsing is fast.
дайсон официальный сайт в россии дайсон официальный сайт в россии .
ValueExpressOutlet – Quick access to items, pleasant site flow, and attractive deals.
Rare Flora Emporium Picks – Clean interface, well-structured categories, and a calming theme.
Rare Botanical Hub – Fast-loading pages and a visually pleasing presentation of products.
Лечение зависимости от алкоголя в стационаре Балашихи. Наши специалисты приедут к вам домой и проведут все необходимые процедуры.
Углубиться в тему - [url=https://https://vyvod-iz-zapoya-v-stacionare-balashiha11.ru//]анонимный вывод из запоя в балашихе[/url]
timelessgoodsstore – TimelessGoodsStore presents carefully chosen products that exude classic charm.
Luxury Living Hub – Stylish, well-organized products with clear and intuitive navigation.
цена курсовой работы цена курсовой работы .
оригинальный фен dyson оригинальный фен dyson .
официальный сайт dyson фен fen-ds-2.ru .
Premium Interiors Marketplace – Elegant arrangement with simple navigation and visually appealing layout.
дайсон стайлер купить официальный сайт дайсон стайлер купить официальный сайт .
timelessgoodsstore – TimelessGoodsStore presents carefully chosen products that exude classic charm.
Platform Picks Hub – Everything presented clearly, browsing feels effortless and pleasant.
стайлер dyson официальный сайт стайлер dyson официальный сайт .
фен дайсон купить оригинал фен дайсон купить оригинал .
купить дайсон стайлер для волос с насадками официальный сайт цена http://fen-ds-1.ru/ .
Neat Click Hub – Clean and structured interface with easy-to-follow sections.
UnlimitedGrowthSpot – Great insights displayed and navigation felt natural.
ростов купить стайлер дайсон http://dn-fen-2.ru/ .
курсовые заказ курсовые заказ .
дайсон фен оригинал цена дайсон фен оригинал цена .
купить дайсон стайлер с насадками официальный сайт для волос цена www.fen-ds-2.ru .
dyson фен официальный сайт www.dn-fen-3.ru/ .
your fashion hub – Fashion selections look appealing, navigation is simple and pleasant.
ExpandPotentialHub – Nice mix of content and smooth navigation experience.
Лечение зависимости требует системного подхода, включающего диагностику, детоксикацию, медикаментозную терапию и психологическую реабилитацию. Наркологическая клиника в Самаре объединяет специалистов различных направлений: врачей-наркологов, психиатров, психологов, терапевтов и реабилитологов. Совместная работа команды обеспечивает комплексное воздействие на физическое и эмоциональное состояние пациента.
Подробнее тут - [url=https://narkologicheskaya-clinika-v-samare16.ru/]вывод наркологическая клиника самара[/url]
дайсон стайлер для волос цена с насадками официальный сайт купить https://dn-fen-4.ru .
dyson сайт официальный в россии dyson сайт официальный в россии .
цена дайсон стайлер для волос с насадками официальный сайт купить https://fen-ds-1.ru .
pure fashion finds – Selections are attractive, site navigation feels simple and clear.
дайсон официальный сайт интернет https://dn-fen-2.ru .
новые казино 2026 онлайн Игра в казино должна приносить удовольствие, а не становиться источником проблем. Играйте ответственно, устанавливайте лимиты и не рискуйте деньгами, которые вы не можете позволить себе потерять.
shop wind hub – Navigation was intuitive and products were neatly displayed.
shop wind boutique – Smooth scrolling and fast pages made finding products easy.
дайсон фен купить официальный https://dn-fen-1.ru/ .
Forest Lane Selection – Attractive forest-themed items, with a soothing and enjoyable layout.
дайсон стайлер для волос купить официальный сайт с насадками цена https://fen-d-1.ru/ .
Forest Lane Deals – Items presented elegantly, giving the site a peaceful and enjoyable feel.
Качество — это не субъективные впечатления, а сравнение базовой линии с целевыми коридорами в обозначенных окнах. Мы ведём короткий отчёт по маркерам: переносимость воды (мл/ч), диурез, ЧСС/АД в покое, структура сна (длительность и число пробуждений), динамика по шкалам тошноты/тремора, выполнение двух утренних бытовых задач. Отчёт понятен пациенту: в нём нет лишней терминологии, только факты и решения — какой модуль снят, какой оставлен ещё на ночь, какой будет пересмотрен через 12–24 часа. Финансовая прозрачность следует той же логике: расширение проводится только по показаниям с указанием цели («какой маркер планируем улучшить») и окна переоценки («когда проверяем результат»).
Ознакомиться с деталями - лечение в наркологической клинике
купить дайсон в москве оригинал https://stajler-d-2.ru/ .
официальный сайт дайсон фен http://dn-fen-1.ru/ .
фен купить дайсон официальный фен купить дайсон официальный .
стайлер дайсон для волос с насадками купить официальный сайт цена http://www.fen-d-1.ru .
Hub Fashion Picks – Fashion choices are neatly displayed, making it simple to explore categories.
Global Picks Hub – Smooth shopping experience with high-quality products and clear layout.
Вывод из запоя в Ростове-на-Дону — это медицинская процедура, направленная на устранение симптомов алкогольной интоксикации, восстановление функций организма и предотвращение осложнений. В клинике помощь оказывается круглосуточно, а лечение проводится под контролем опытных наркологов. Такой подход позволяет безопасно прекратить употребление алкоголя, избежать резкой отмены и стабилизировать состояние пациента. Процедура проводится как в стационаре, так и на дому, с учётом состояния здоровья и степени зависимости.
Получить больше информации - вывод из запоя недорого в ростове-на-дону
FashionChoice Spot – Modern items stand out clearly, and moving through the site feels simple.
дайсон стайлер для волос купить официальный сайт с насадками цена https://stajler-d-2.ru .
Global Essentials Collection – Impressive selection, smooth browsing experience, and high-quality items.
цена дайсон стайлер для волос с насадками официальный сайт купить http://stajler-d-3.ru/ .
Next Generation Finds – The store feels fresh, with an enjoyable browsing experience.
SunrisePeak Inspirations – The creative ideas showcased here feel uplifting and easy to browse.
оригинальный фен dyson https://www.stajler-d-1.ru .
Next Generation Living – Each product is unique, and browsing feels intuitive and enjoyable.
explore alternatives – Focuses on reviewing multiple options instead of rushing.
SunrisePeak Studio Work – Every design feels intentional and expressive, a pleasant site to browse.
find better paths – Suggests discovering routes that feel more aligned and useful.
Ever Forest Treasures Online – Items feel natural, and the overall experience is calm and enjoyable.
Chic Fashion Spot – A clean presentation of stylish outfits with simple, intuitive browsing.
Эта схема помогает постепенно вывести пациента из кризисного состояния, снизить риски осложнений и закрепить результаты лечения.
Узнать больше - http://narkologicheskaya-klinika-v-krasnodare16.ru/narkologicheskaya-klinika-krasnodar-otzyvy/https://narkologicheskaya-klinika-v-krasnodare16.ru
La plateforme 1xbet burkina: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
NameDrift Shop – Items look appealing, navigation is simple and browsing feels pleasant.
EverForest Treasures – The store layout is clean and minimal, making browsing relaxing.
дайсон стайлер для волос купить цена официальный сайт с насадками www.stajler-d-1.ru/ .
Trendy Bright Boutique – A bright, modern feel throughout the store with simple, organized browsing.
carefullychosenluxury – Carefullychosenluxury has an elegant selection that made browsing feel premium and fun.
Site web 1xbet cd apk – paris sportifs en ligne sur le football et autres sports. Propose des paris en direct et a l'avance, des cotes, des resultats et des tournois. Description detaillee du service, des fonctionnalites du compte et de son utilisation au Congo.
NameDrift Treasures Hub – Items displayed clearly, site navigation is smooth and intuitive.
carefullychosenluxury – Carefullychosenluxury has an elegant selection that made browsing feel premium and fun.
Site web de parifoot rd congo: paris sportifs, championnats de football, resultats des matchs et cotes. Informations detaillees sur la plateforme, les conditions d’utilisation, les fonctionnalites et les evenements sportifs disponibles.
DailySavingsStore – Products are well organized, pages load quickly, and shopping feels easy.
La plateforme en ligne xbet burkina: paris sportifs en ligne, matchs de football, evenements en direct et statistiques. Description du service, marches disponibles, cotes et principales fonctionnalites du site.
Капельница — это не «секретный коктейль», а набор узких модулей, каждый из которых отвечает за одну задачу. Мы включаем ровно один новый модуль за раз и заранее обозначаем стоп-критерий, чтобы не тянуть терапию «по инерции». Параллельно настраиваются поведенческие элементы: свет, тишина, дыхательные ритмы и «окна» питья. Это снимает часть нагрузки с организма и ускоряет наступление целевых маркеров.
Подробнее можно узнать тут - нарколог на дом круглосуточно
SmartBudgetShop – Products are easy to browse, pages load quickly, and prices are great.
купить фен дайсон официальный http://stajler-d.ru .
Весь процесс можно представить следующим образом:
Детальнее - [url=https://narkolog-na-dom-v-chelyabinske16.ru/]narkolog-na-dom-v-chelyabinske16.ru/[/url]
дайсон официальный сайт спб http://www.dn-fen-4.ru .
Капельница — основной метод дезинтоксикации при запое. Она позволяет быстро восполнить дефицит жидкости и электролитов, вывести токсины и улучшить общее самочувствие. В состав инфузии входят препараты, нормализующие обмен веществ, а также витамины и гепатопротекторы. Процедура проводится под контролем врача, что гарантирует безопасность и точную дозировку лекарств.
Получить больше информации - срочный вывод из запоя ростов-на-дону
дайсон официальный сайт фен купить www.fen-d-2.ru .
сайт заказать курсовую работу сайт заказать курсовую работу .
купить фен дайсон купить фен дайсон .
дайсон купить стайлер официальный сайт dn-fen-3.ru .
фен дайсон цена официальный сайт http://www.fen-ds-2.ru .
Clickping Central – Items and sections arranged thoughtfully, making exploration seamless.
Market Picks Online – The layout keeps everything clear, offering a pleasant shopping experience overall.
next possibilities – Frames discovery as an easy and enjoyable process.
Clickping Design Hub – Neatly organized sections, user-friendly interface, and smooth browsing.
дайсон фен купить в москве оригинал http://www.stajler-d.ru .
dyson official dyson official .
opportunity discovery – Suggests browsing potential paths without feeling rushed.
DealQuest Market – Everything is laid out logically, contributing to a smooth user journey.
курсовые купить курсовые купить .
фен dyson фен dyson .
стайлер для волос дайсон с насадками официальный сайт купить цена www.fen-ds-3.ru/ .
дайсон стайлер официальный сайт fen-ds-2.ru .
дайсон стайлер для волос купить цена официальный сайт с насадками www.fen-d-2.ru/ .
Curated Lifestyle Hub – Stylish products presented clearly with intuitive flow.
Школа блогеров https://vdskill.ru и видеотехнологий для авторов и предпринимателей. Создание видео, сторителлинг, монтаж и продвижение. Практические занятия, поддержка наставников и актуальные инструменты для роста.
Образовательный блог https://educationruss.ru об обучении за границей. Университеты и колледжи, языковые курсы, условия поступления, стоимость, документы и жизнь студентов. Полезные статьи и рекомендации для абитуриентов и родителей.
Профессиональные обучение инъекции в косметологии теория, практика, безопасность и современные подходы к эстетическим процедурам. Помогаем получить уверенные навыки и системные знания для работы.
Блог Елены Беляевой https://bestyleacademy.ru профессионального стилиста. Разборы гардероба, капсульные коллекции, советы по стилю и актуальным трендам. Практика, вдохновение и понятные рекомендации для женщин и мужчин.
новые казино 2026 онлайн Надеемся, наш топ-10 поможет вам сделать правильный выбор и найти свое идеальное онлайн-казино! Удачной игры!
Application mobile 1xbet apk. Paris sportifs en ligne, football et tournois populaires, evenements en direct et statistiques. Presentation de l'application et de ses principales fonctionnalites.
Curated Lifestyle Hub – Stylish products presented clearly with intuitive flow.
Образовательный блог https://educationruss.ru об обучении за границей. Университеты и колледжи, языковые курсы, условия поступления, стоимость, документы и жизнь студентов. Полезные статьи и рекомендации для абитуриентов и родителей.
Профессиональные обучение инъекции в косметологии теория, практика, безопасность и современные подходы к эстетическим процедурам. Помогаем получить уверенные навыки и системные знания для работы.
Школа блогеров https://vdskill.ru и видеотехнологий для авторов и предпринимателей. Создание видео, сторителлинг, монтаж и продвижение. Практические занятия, поддержка наставников и актуальные инструменты для роста.
Блог Елены Беляевой https://bestyleacademy.ru профессионального стилиста. Разборы гардероба, капсульные коллекции, советы по стилю и актуальным трендам. Практика, вдохновение и понятные рекомендации для женщин и мужчин.
дайсон стайлер для волос с насадками цена официальный сайт купить http://fen-ds-4.ru/ .
dyson official http://www.fen-ds-1.ru .
SuccessJourneySpot – Motivational articles, site layout is simple and intuitive.
value choice center – Items appear strong, shopping feels pleasant and easy.
GrowBeyondLimits – Content inspires, site layout is clear and easy to navigate.
Капельница — основной метод дезинтоксикации при запое. Она позволяет быстро восполнить дефицит жидкости и электролитов, вывести токсины и улучшить общее самочувствие. В состав инфузии входят препараты, нормализующие обмен веществ, а также витамины и гепатопротекторы. Процедура проводится под контролем врача, что гарантирует безопасность и точную дозировку лекарств.
Ознакомиться с деталями - вывод из запоя цена ростов-на-дону
pure value hub – Products here appear reliable, site navigation is smooth and easy.
дайсон фен купить официальный сайт дайсон фен купить официальный сайт .
Эта схема помогает постепенно вывести пациента из кризисного состояния, снизить риски осложнений и закрепить результаты лечения.
Разобраться лучше - вывод наркологическая клиника краснодар
фен dyson www.fen-ds-1.ru .
goal clarity – Focuses on simplifying decisions related to personal growth.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Изучить вопрос глубже - https://friendswestendorf.at/tips-on-buying-a-fixer-upper-2
directional insight – Reinforces making informed decisions about personal growth.
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Тыкай сюда — узнаешь много интересного - https://an-ve.co.uk/conbox-stackable-electric-fan
стайлер дайсон купить в спб https://dn-fen-2.ru .
Premium Global Essentials Picks – Wide variety of well-presented products, very happy with the quality.
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Доступ к полной версии - https://ho.gctu.edu.gh/2021/03/04/hello-world
В этой статье вы найдете уникальные исторические пересечения с научными открытиями. Каждый абзац — это шаг к пониманию того, как наука и события прошлого создают основу для технологического будущего.
Проверенные методы — узнай сейчас - https://www.abcmix.com/lifting-plug-in-double-sided-light-box-illuminate-your-business-everywhere
Global Essentials Picks – Wide assortment of products, well-presented and impressive quality.
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Проверенные методы — узнай сейчас - https://castangia1850.com/blog-01
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Погрузиться в детали - https://castangia1850.com/blog-01
дайсон стайлер http://dn-fen-2.ru/ .
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Переходите по ссылке ниже - https://maracanaonline.com.br/2022/09/27/corinthians-x-sao-jose-assista-ao-vivo-paulistao-feminino-hoje-27-09-com-imagens
Статья знакомит с важнейшими моментами, которые сформировали наше общество. От великих изобретений до культурных переворотов — вы узнаете, как прошлое влияет на наше мышление, технологии и образ жизни.
Следуйте по ссылке - https://massif.co.in/15-secrets-of-digital-transformation
Статья знакомит с важнейшими моментами, которые сформировали наше общество. От великих изобретений до культурных переворотов — вы узнаете, как прошлое влияет на наше мышление, технологии и образ жизни.
Раскрыть тему полностью - https://spira.farm/chicagos-local-mushrooms-%F0%9F%A5%A6%F0%9F%A6%83
Читатель отправляется в интеллектуальное путешествие по самым ярким событиям истории и важнейшим научным открытиям. Мы раскроем тайны эпох, покажем, как идеи меняли миры, и объясним, почему эти знания остаются актуальными сегодня.
Как это работает — подробно - https://davelampole.be/event/the-best-easy-one-pot-chicken-and-rice-recipe
В данной статье вы найдете комплексный подход к изучению насущных тем. Мы комбинируем теоретические сведения с практическими советами, чтобы читатель мог не только понять проблему, но и найти пути её решения.
Перейти к полной версии - https://www2.geo.sc.chula.ac.th/2019-luxury-kitchens
фен дайсон оригинал купить https://dn-fen-1.ru/ .
Этот обзор предлагает структурированное изложение информации по актуальным вопросам. Материал подан так, чтобы даже новичок мог быстро освоиться в теме и начать использовать полученные знания в практике.
Что скрывают от вас? - https://beltema.com.tr/index.php/services/financial-services-consulting